 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust, High-Precision GNSS Carrier-Phase Positioning with Visual-Inertial Fusion
Mar 02, 2023



Robust, high-precision global localization is fundamental to a wide range of outdoor robotics applications. Conventional fusion methods use low-accuracy pseudorange based GNSS measurements ($>>5m$ errors) and can only yield a coarse registration to the global earth-centered-earth-fixed (ECEF) frame. In this paper, we leverage high-precision GNSS carrier-phase positioning and aid it with local visual-inertial odometry (VIO) tracking using an extended Kalman filter (EKF) framework that better resolves the integer ambiguity concerned with GNSS carrier-phase. %to achieve centimeter-level accuracy in the ECEF frame. We also propose an algorithm for accurate GNSS-antenna-to-IMU extrinsics calibration to accurately align VIO to the ECEF frame. Together, our system achieves robust global positioning demonstrated by real-world hardware experiments in severely occluded urban canyons, and outperforms the state-of-the-art RTKLIB by a significant margin in terms of integer ambiguity solution fix rate and positioning RMSE accuracy.
CubeSLAM: Monocular 3D Object SLAM
Apr 05, 2019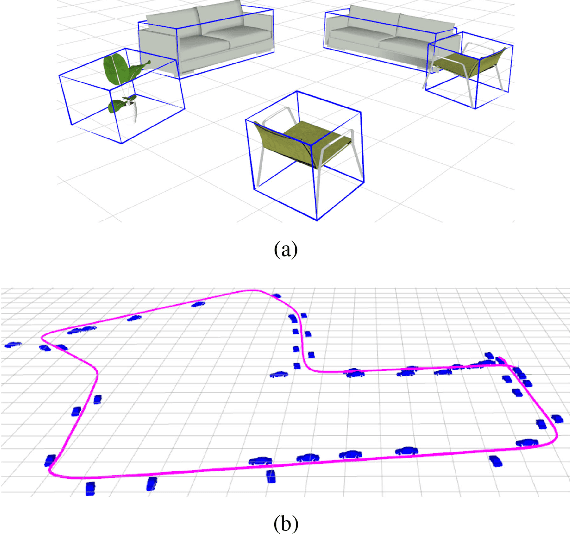
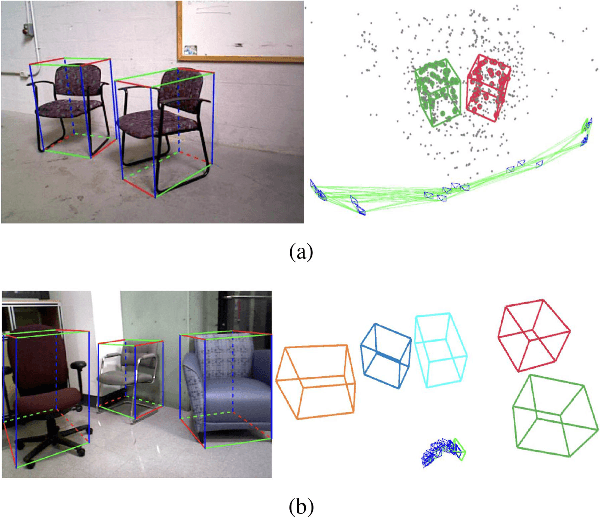
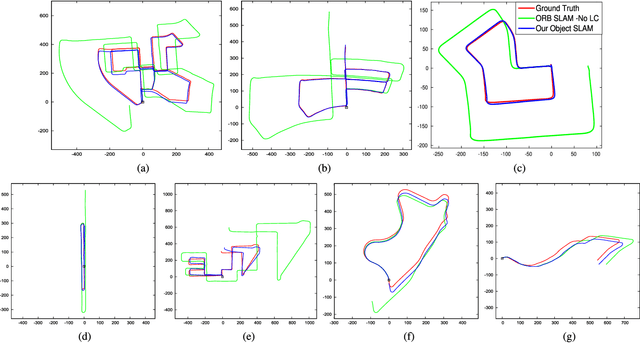
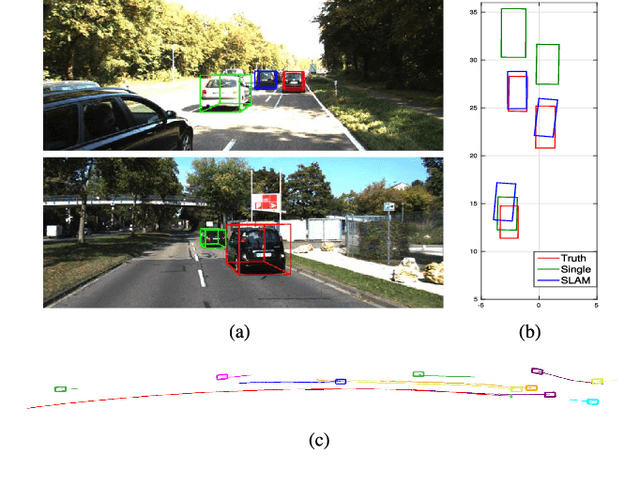
We present a method for single image 3D cuboid object detection and multi-view object SLAM in both static and dynamic environments, and demonstrate that the two parts can improve each other. Firstly for single image object detection, we generate high-quality cuboid proposals from 2D bounding boxes and vanishing points sampling. The proposals are further scored and selected based on the alignment with image edges. Secondly, multi-view bundle adjustment with new object measurements is proposed to jointly optimize poses of cameras, objects and points. Objects can provide long-range geometric and scale constraints to improve camera pose estimation and reduce monocular drift. Instead of treating dynamic regions as outliers, we utilize object representation and motion model constraints to improve the camera pose estimation. The 3D detection experiments on SUN RGBD and KITTI show better accuracy and robustness over existing approaches. On the public TUM, KITTI odometry and our own collected datasets, our SLAM method achieves the state-of-the-art monocular camera pose estimation and at the same time, improves the 3D object detection accuracy.
Monocular and Stereo Cues for Landing Zone Evaluation for Micro UAVs
Dec 09, 2018
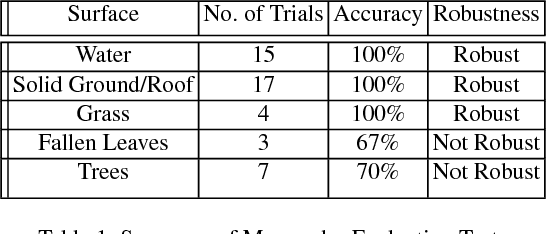
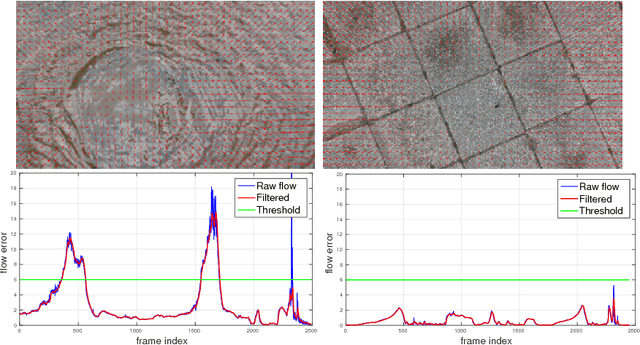
Autonomous and safe landing is important for unmanned aerial vehicles. We present a monocular and stereo image based method for fast and accurate landing zone evaluation for UAVs in various scenarios. Many existing methods rely on Lidar or depth sensor to provide accurate and dense surface reconstruction. We utilize stereo images to evaluate the slope and monocular images to compute homography error. By combining them together, our approach works for both rigid and non-rigid dynamic surfaces. Experiments on many outdoor scenes such as water, grass and roofs, demonstrate the robustness and effectiveness of our approach.
Monocular Object and Plane SLAM in Structured Environments
Sep 10, 2018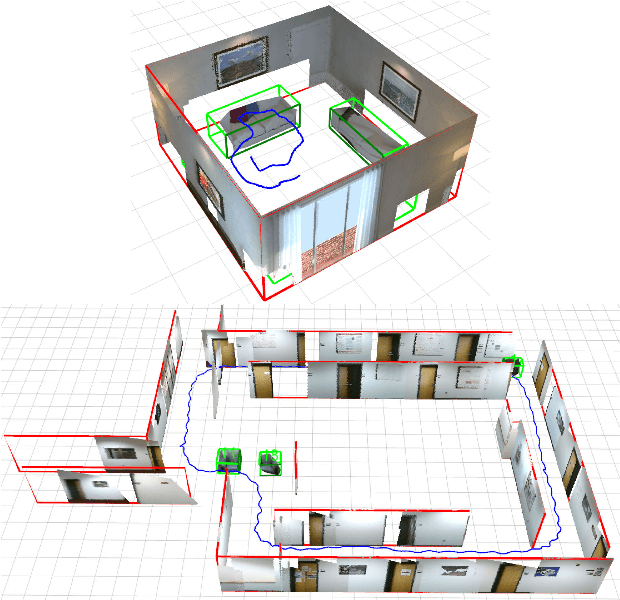
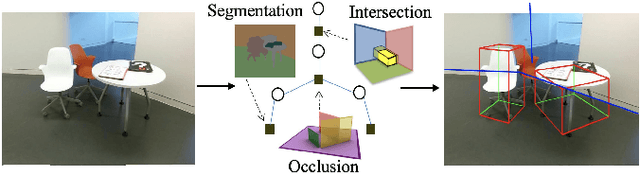
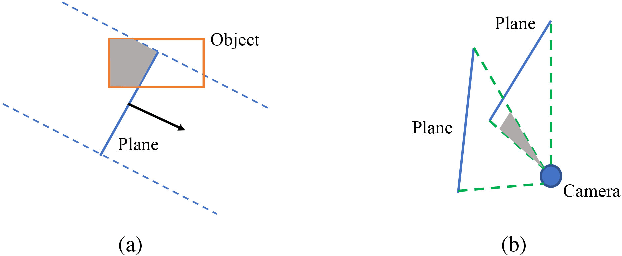
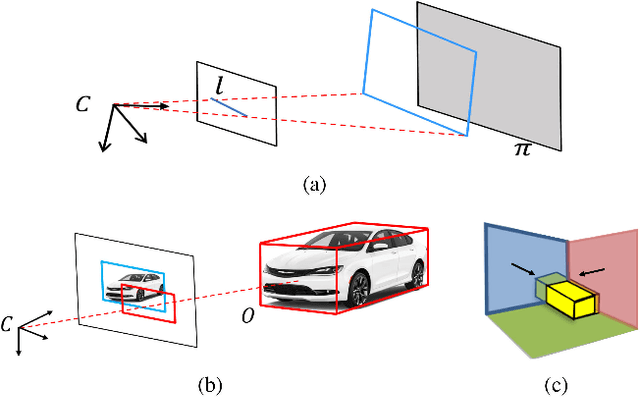
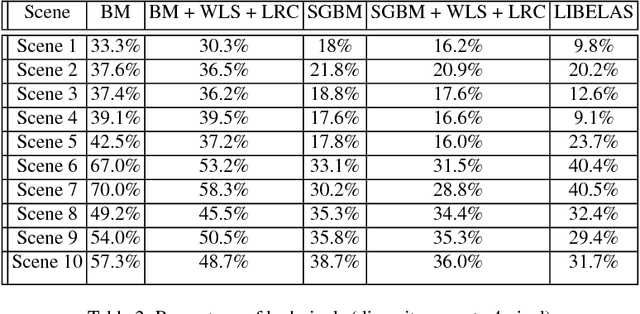
We present a monocular Simultaneous Localization and Mapping (SLAM) using high level object and plane landmarks, in addition to points. The resulting map is denser, more compact and meaningful compared to point only SLAM. We first propose a high order graphical model to jointly infer the 3D object and layout planes from single image considering occlusions and semantic constraints. The extracted cuboid object and layout planes are further optimized in a unified SLAM framework. Objects and planes can provide more semantic constraints such as Manhattan and object supporting relationships compared to points. Experiments on various public and collected datasets including ICL NUIM and TUM mono show that our algorithm can improve camera localization accuracy compared to state-of-the-art SLAM and also generate dense maps in many structured environments.
Semantic 3D Occupancy Mapping through Efficient High Order CRFs
Jul 24, 2017
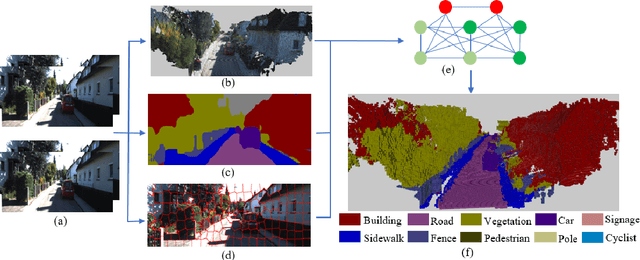

Semantic 3D mapping can be used for many applications such as robot navigation and virtual interaction. In recent years, there has been great progress in semantic segmentation and geometric 3D mapping. However, it is still challenging to combine these two tasks for accurate and large-scale semantic mapping from images. In the paper, we propose an incremental and (near) real-time semantic mapping system. A 3D scrolling occupancy grid map is built to represent the world, which is memory and computationally efficient and bounded for large scale environments. We utilize the CNN segmentation as prior prediction and further optimize 3D grid labels through a novel CRF model. Superpixels are utilized to enforce smoothness and form robust P N high order potential. An efficient mean field inference is developed for the graph optimization. We evaluate our system on the KITTI dataset and improve the segmentation accuracy by 10% over existing systems.
Obstacle Avoidance through Deep Networks based Intermediate Perception
Apr 27, 2017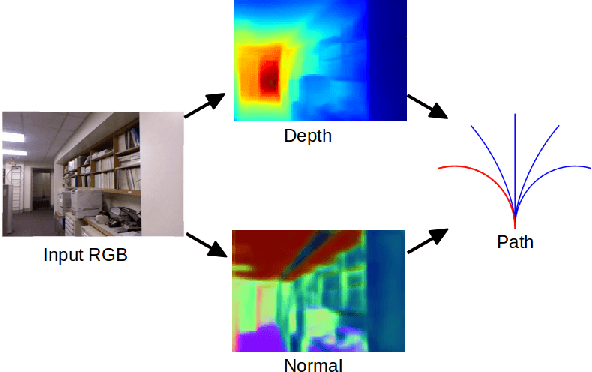

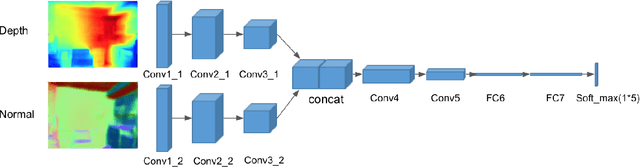
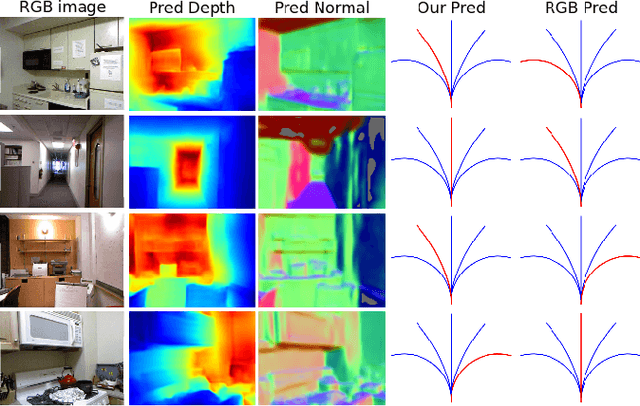
Obstacle avoidance from monocular images is a challenging problem for robots. Though multi-view structure-from-motion could build 3D maps, it is not robust in textureless environments. Some learning based methods exploit human demonstration to predict a steering command directly from a single image. However, this method is usually biased towards certain tasks or demonstration scenarios and also biased by human understanding. In this paper, we propose a new method to predict a trajectory from images. We train our system on more diverse NYUv2 dataset. The ground truth trajectory is computed from the designed cost functions automatically. The Convolutional Neural Network perception is divided into two stages: first, predict depth map and surface normal from RGB images, which are two important geometric properties related to 3D obstacle representation. Second, predict the trajectory from the depth and normal. Results show that our intermediate perception increases the accuracy by 20% than the direct prediction. Our model generalizes well to other public indoor datasets and is also demonstrated for robot flights in simulation and experiments.
Pop-up SLAM: Semantic Monocular Plane SLAM for Low-texture Environments
Mar 21, 2017

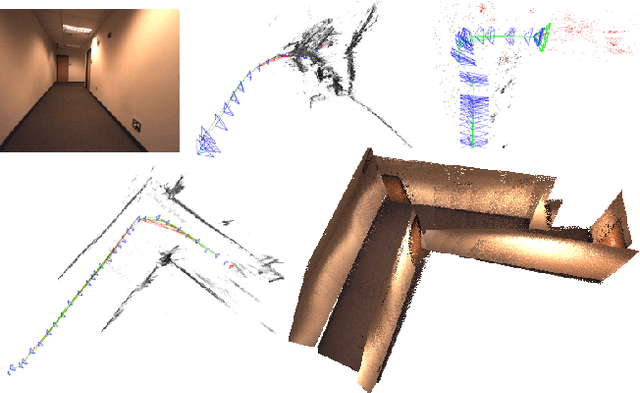

Existing simultaneous localization and mapping (SLAM) algorithms are not robust in challenging low-texture environments because there are only few salient features. The resulting sparse or semi-dense map also conveys little information for motion planning. Though some work utilize plane or scene layout for dense map regularization, they require decent state estimation from other sources. In this paper, we propose real-time monocular plane SLAM to demonstrate that scene understanding could improve both state estimation and dense mapping especially in low-texture environments. The plane measurements come from a pop-up 3D plane model applied to each single image. We also combine planes with point based SLAM to improve robustness. On a public TUM dataset, our algorithm generates a dense semantic 3D model with pixel depth error of 6.2 cm while existing SLAM algorithms fail. On a 60 m long dataset with loops, our method creates a much better 3D model with state estimation error of 0.67%.
Direct Monocular Odometry Using Points and Lines
Mar 19, 2017

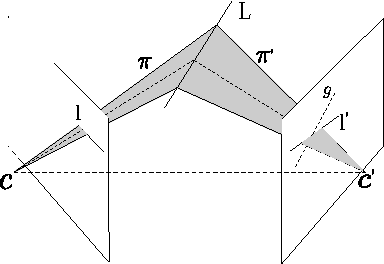
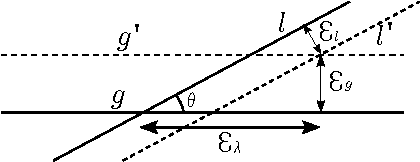
Most visual odometry algorithm for a monocular camera focuses on points, either by feature matching, or direct alignment of pixel intensity, while ignoring a common but important geometry entity: edges. In this paper, we propose an odometry algorithm that combines points and edges to benefit from the advantages of both direct and feature based methods. It works better in texture-less environments and is also more robust to lighting changes and fast motion by increasing the convergence basin. We maintain a depth map for the keyframe then in the tracking part, the camera pose is recovered by minimizing both the photometric error and geometric error to the matched edge in a probabilistic framework. In the mapping part, edge is used to speed up and increase stereo matching accuracy. On various public datasets, our algorithm achieves better or comparable performance than state-of-the-art monocular odometry methods. In some challenging texture-less environments, our algorithm reduces the state estimation error over 50%.