 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust width: A lightweight and certifiable adversarial defense
May 24, 2024Deep neural networks are vulnerable to so-called adversarial examples: inputs which are intentionally constructed to cause the model to make incorrect predictions or classifications. Adversarial examples are often visually indistinguishable from natural data samples, making them hard to detect. As such, they pose significant threats to the reliability of deep learning systems. In this work, we study an adversarial defense based on the robust width property (RWP), which was recently introduced for compressed sensing. We show that a specific input purification scheme based on the RWP gives theoretical robustness guarantees for images that are approximately sparse. The defense is easy to implement and can be applied to any existing model without additional training or finetuning. We empirically validate the defense on ImageNet against $L^\infty$ perturbations at perturbation budgets ranging from $4/255$ to $32/255$. In the black-box setting, our method significantly outperforms the state-of-the-art, especially for large perturbations. In the white-box setting, depending on the choice of base classifier, we closely match the state of the art in robust ImageNet classification while avoiding the need for additional data, larger models or expensive adversarial training routines. Our code is available at https://github.com/peck94/robust-width-defense.
Distilling Deep RL Models Into Interpretable Neuro-Fuzzy Systems
Sep 07, 2022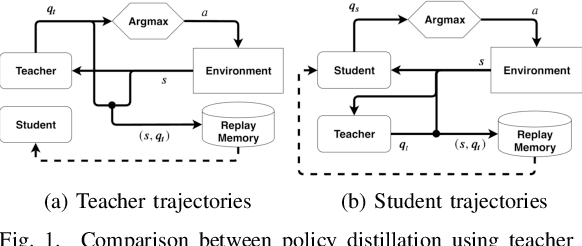
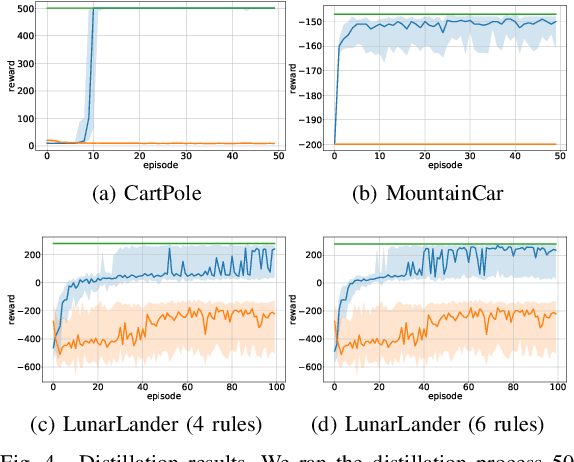
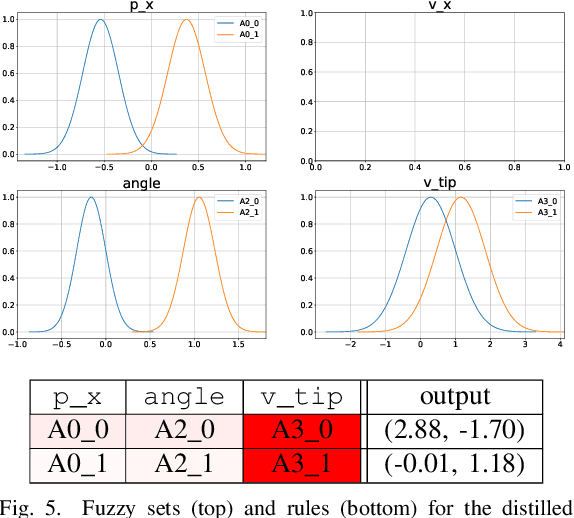
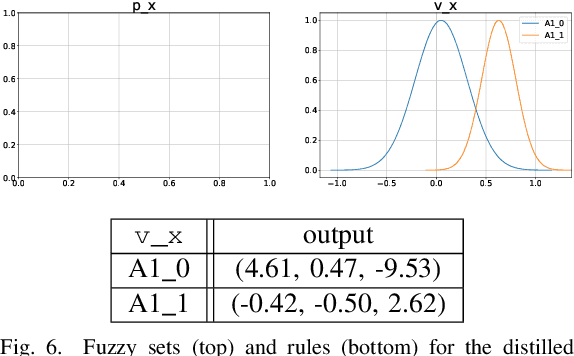
Deep Reinforcement Learning uses a deep neural network to encode a policy, which achieves very good performance in a wide range of applications but is widely regarded as a black box model. A more interpretable alternative to deep networks is given by neuro-fuzzy controllers. Unfortunately, neuro-fuzzy controllers often need a large number of rules to solve relatively simple tasks, making them difficult to interpret. In this work, we present an algorithm to distill the policy from a deep Q-network into a compact neuro-fuzzy controller. This allows us to train compact neuro-fuzzy controllers through distillation to solve tasks that they are unable to solve directly, combining the flexibility of deep reinforcement learning and the interpretability of compact rule bases. We demonstrate the algorithm on three well-known environments from OpenAI Gym, where we nearly match the performance of a DQN agent using only 2 to 6 fuzzy rules.
Regional Image Perturbation Reduces $L_p$ Norms of Adversarial Examples While Maintaining Model-to-model Transferability
Jul 07, 2020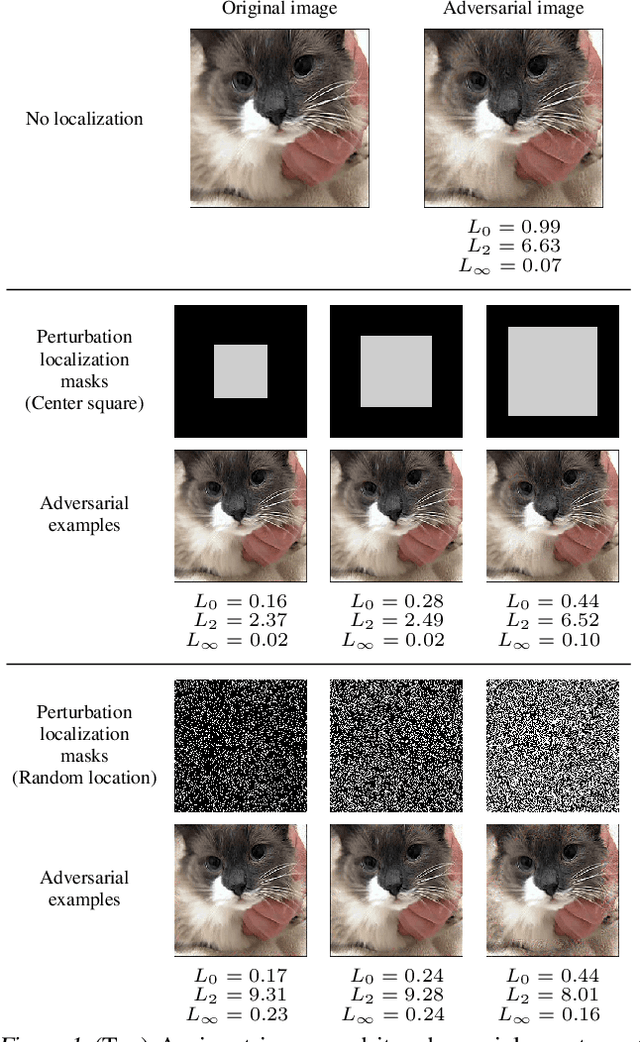
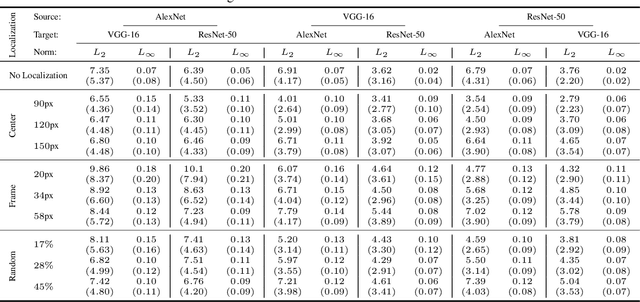

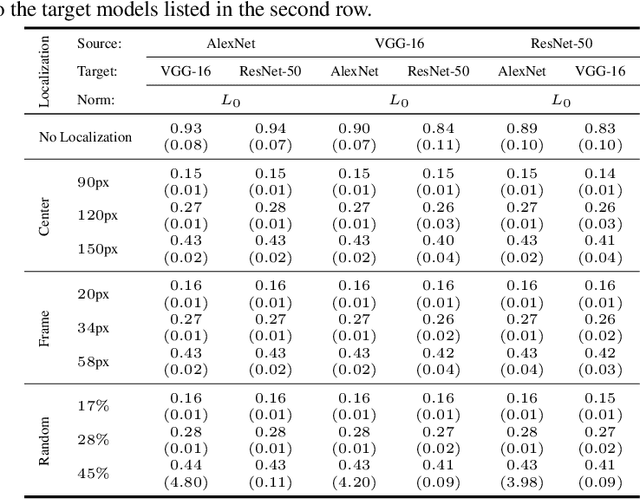
Regional adversarial attacks often rely on complicated methods for generating adversarial perturbations, making it hard to compare their efficacy against well-known attacks. In this study, we show that effective regional perturbations can be generated without resorting to complex methods. We develop a very simple regional adversarial perturbation attack method using cross-entropy sign, one of the most commonly used losses in adversarial machine learning. Our experiments on ImageNet with multiple models reveal that, on average, $76\%$ of the generated adversarial examples maintain model-to-model transferability when the perturbation is applied to local image regions. Depending on the selected region, these localized adversarial examples require significantly less $L_p$ norm distortion (for $p \in \{0, 2, \infty\}$) compared to their non-local counterparts. These localized attacks therefore have the potential to undermine defenses that claim robustness under the aforementioned norms.
Inline Detection of DGA Domains Using Side Information
Mar 12, 2020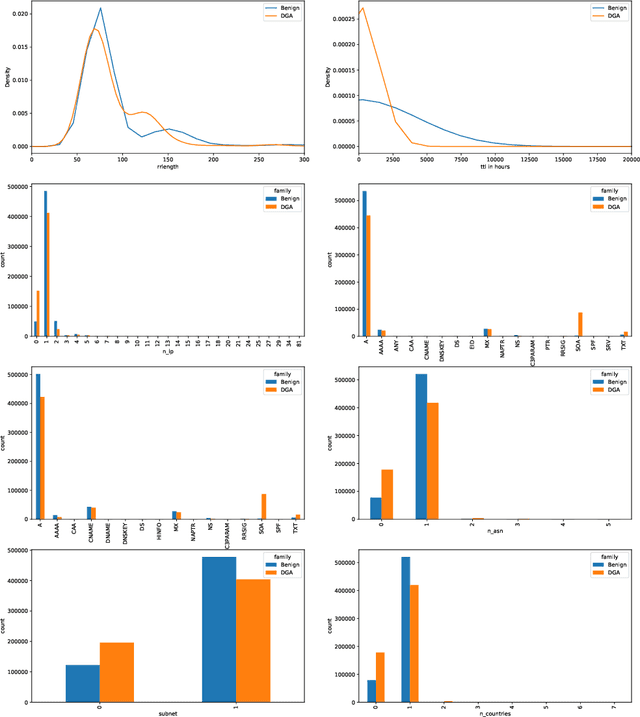

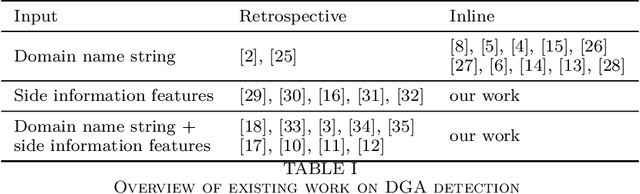

Malware applications typically use a command and control (C&C) server to manage bots to perform malicious activities. Domain Generation Algorithms (DGAs) are popular methods for generating pseudo-random domain names that can be used to establish a communication between an infected bot and the C&C server. In recent years, machine learning based systems have been widely used to detect DGAs. There are several well known state-of-the-art classifiers in the literature that can detect DGA domain names in real-time applications with high predictive performance. However, these DGA classifiers are highly vulnerable to adversarial attacks in which adversaries purposely craft domain names to evade DGA detection classifiers. In our work, we focus on hardening DGA classifiers against adversarial attacks. To this end, we train and evaluate state-of-the-art deep learning and random forest (RF) classifiers for DGA detection using side information that is harder for adversaries to manipulate than the domain name itself. Additionally, the side information features are selected such that they are easily obtainable in practice to perform inline DGA detection. The performance and robustness of these models is assessed by exposing them to one day of real-traffic data as well as domains generated by adversarial attack algorithms. We found that the DGA classifiers that rely on both the domain name and side information have high performance and are more robust against adversaries.
CharBot: A Simple and Effective Method for Evading DGA Classifiers
May 30, 2019
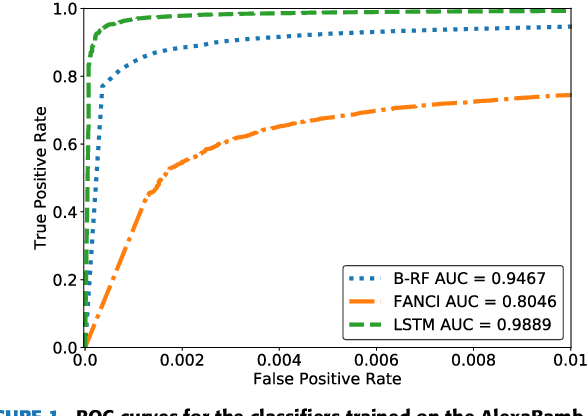

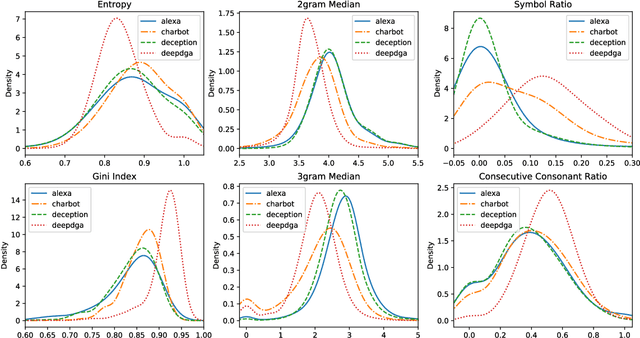
Domain generation algorithms (DGAs) are commonly leveraged by malware to create lists of domain names which can be used for command and control (C&C) purposes. Approaches based on machine learning have recently been developed to automatically detect generated domain names in real-time. In this work, we present a novel DGA called CharBot which is capable of producing large numbers of unregistered domain names that are not detected by state-of-the-art classifiers for real-time detection of DGAs, including the recently published methods FANCI (a random forest based on human-engineered features) and LSTM.MI (a deep learning approach). CharBot is very simple, effective and requires no knowledge of the targeted DGA classifiers. We show that retraining the classifiers on CharBot samples is not a viable defense strategy. We believe these findings show that DGA classifiers are inherently vulnerable to adversarial attacks if they rely only on the domain name string to make a decision. Designing a robust DGA classifier may, therefore, necessitate the use of additional information besides the domain name alone. To the best of our knowledge, CharBot is the simplest and most efficient black-box adversarial attack against DGA classifiers proposed to date.