 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Attribution-Based Explanations Using Functional Decomposition
Dec 18, 2024
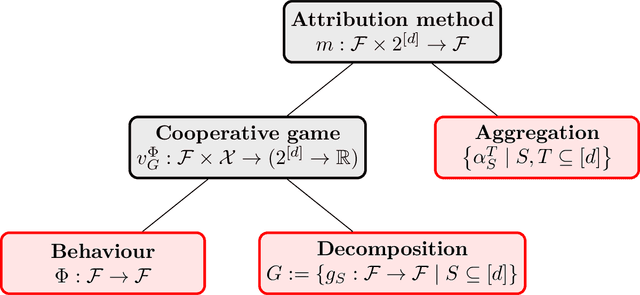


The black box problem in machine learning has led to the introduction of an ever-increasing set of explanation methods for complex models. These explanations have different properties, which in turn has led to the problem of method selection: which explanation method is most suitable for a given use case? In this work, we propose a unifying framework of attribution-based explanation methods, which provides a step towards a rigorous study of the similarities and differences of explanations. We first introduce removal-based attribution methods (RBAMs), and show that an extensively broad selection of existing methods can be viewed as such RBAMs. We then introduce the canonical additive decomposition (CAD). This is a general construction for additively decomposing any function based on the central idea of removing (groups of) features. We proceed to show that indeed every valid additive decomposition is an instance of the CAD, and that any removal-based attribution method is associated with a specific CAD. Next, we show that any removal-based attribution method can be completely defined as a game-theoretic value or interaction index for a specific (possibly constant-shifted) cooperative game, which is defined using the corresponding CAD of the method. We then use this intrinsic connection to define formal descriptions of specific behaviours of explanation methods, which we also call functional axioms, and identify sufficient conditions on the corresponding CAD and game-theoretic value or interaction index of an attribution method under which the attribution method is guaranteed to adhere to these functional axioms. Finally, we show how this unifying framework can be used to develop new, efficient approximations for existing explanation methods.
Distilling Deep RL Models Into Interpretable Neuro-Fuzzy Systems
Sep 07, 2022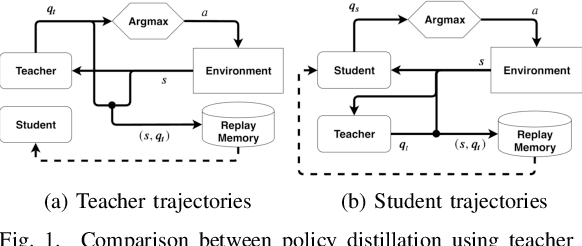
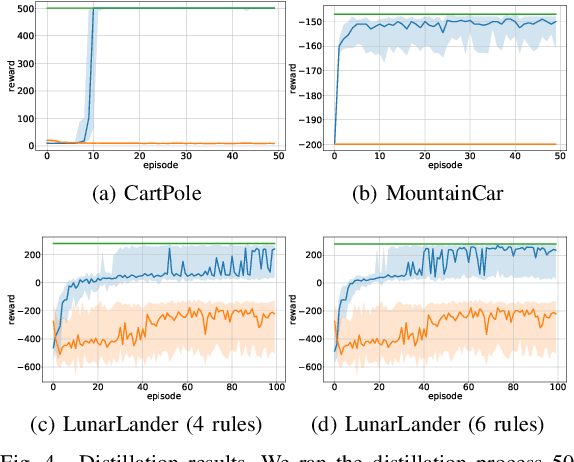
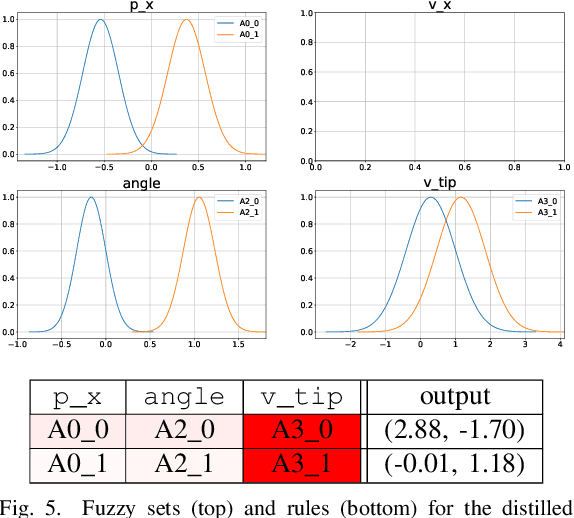
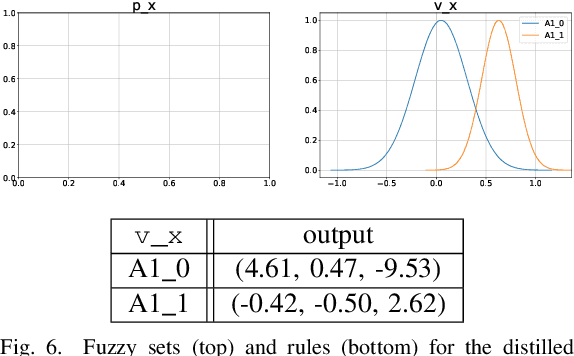
Deep Reinforcement Learning uses a deep neural network to encode a policy, which achieves very good performance in a wide range of applications but is widely regarded as a black box model. A more interpretable alternative to deep networks is given by neuro-fuzzy controllers. Unfortunately, neuro-fuzzy controllers often need a large number of rules to solve relatively simple tasks, making them difficult to interpret. In this work, we present an algorithm to distill the policy from a deep Q-network into a compact neuro-fuzzy controller. This allows us to train compact neuro-fuzzy controllers through distillation to solve tasks that they are unable to solve directly, combining the flexibility of deep reinforcement learning and the interpretability of compact rule bases. We demonstrate the algorithm on three well-known environments from OpenAI Gym, where we nearly match the performance of a DQN agent using only 2 to 6 fuzzy rules.
PDD-SHAP: Fast Approximations for Shapley Values using Functional Decomposition
Aug 26, 2022
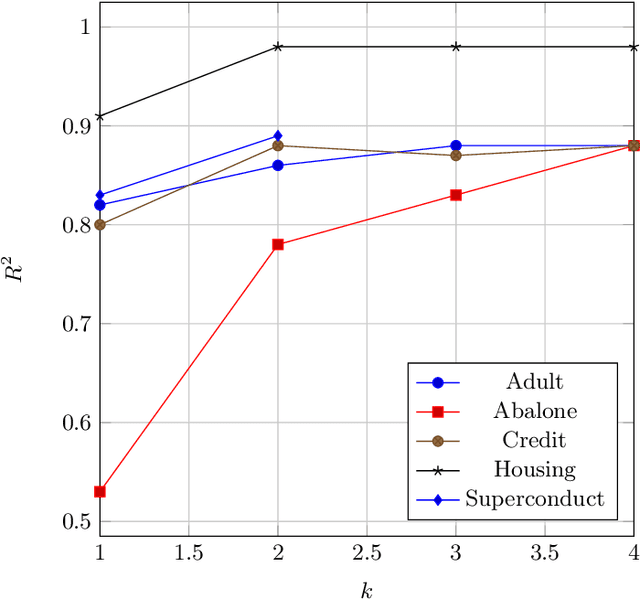
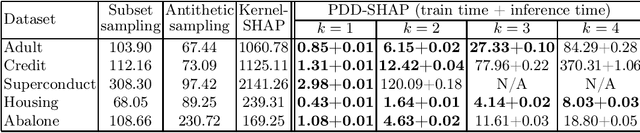
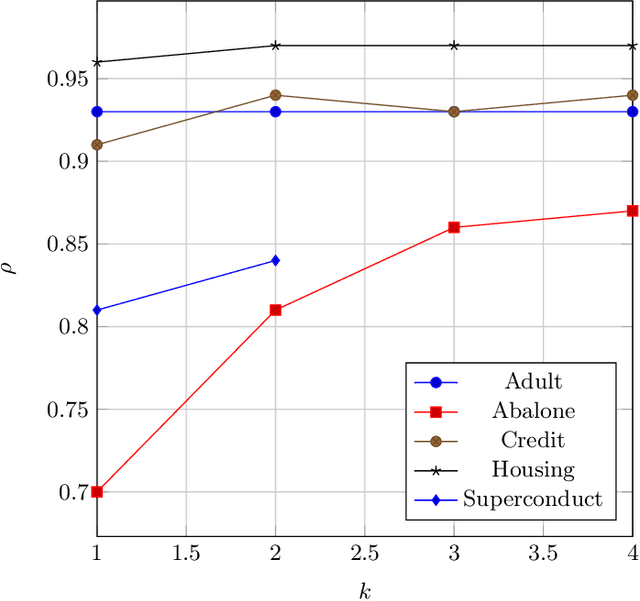
Because of their strong theoretical properties, Shapley values have become very popular as a way to explain predictions made by black box models. Unfortuately, most existing techniques to compute Shapley values are computationally very expensive. We propose PDD-SHAP, an algorithm that uses an ANOVA-based functional decomposition model to approximate the black-box model being explained. This allows us to calculate Shapley values orders of magnitude faster than existing methods for large datasets, significantly reducing the amortized cost of computing Shapley values when many predictions need to be explained.
Evaluating Feature Attribution Methods in the Image Domain
Feb 22, 2022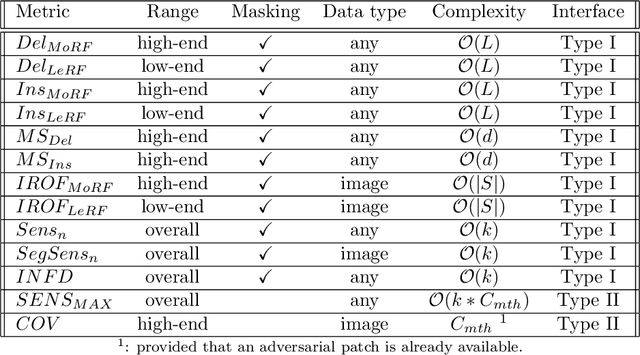

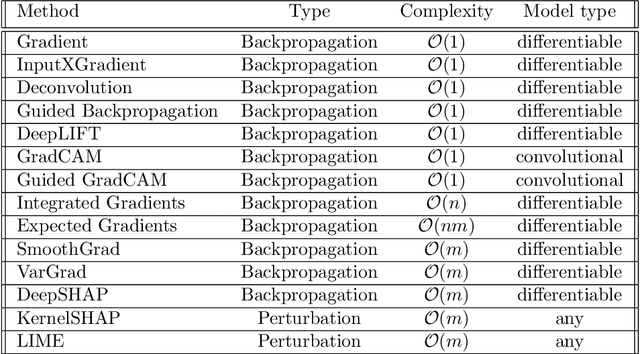
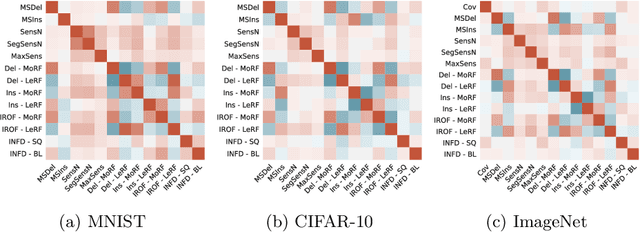
Feature attribution maps are a popular approach to highlight the most important pixels in an image for a given prediction of a model. Despite a recent growth in popularity and available methods, little attention is given to the objective evaluation of such attribution maps. Building on previous work in this domain, we investigate existing metrics and propose new variants of metrics for the evaluation of attribution maps. We confirm a recent finding that different attribution metrics seem to measure different underlying concepts of attribution maps, and extend this finding to a larger selection of attribution metrics. We also find that metric results on one dataset do not necessarily generalize to other datasets, and methods with desirable theoretical properties such as DeepSHAP do not necessarily outperform computationally cheaper alternatives. Based on these findings, we propose a general benchmarking approach to identify the ideal feature attribution method for a given use case. Implementations of attribution metrics and our experiments are available online.