 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Principled Evaluation Protocol for Comparative Investigation of the Effectiveness of DNN Classification Models on Similar-but-non-identical Datasets
Paper and Code
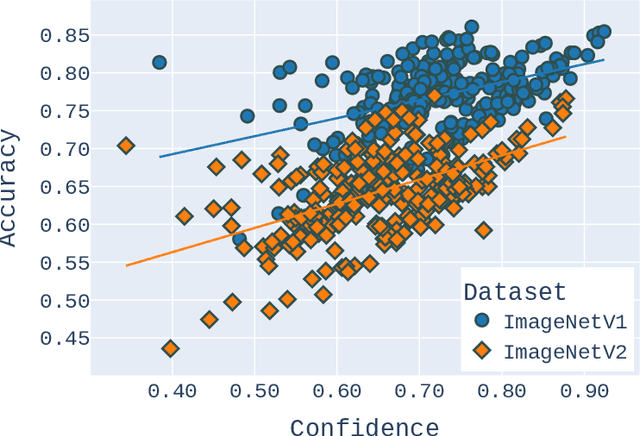

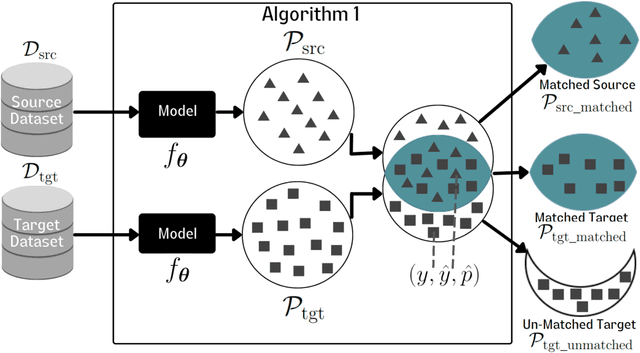

Deep Neural Network (DNN) models are increasingly evaluated using new replication test datasets, which have been carefully created to be similar to older and popular benchmark datasets. However, running counter to expectations, DNN classification models show significant, consistent, and largely unexplained degradation in accuracy on these replication test datasets. While the popular evaluation approach is to assess the accuracy of a model by making use of all the datapoints available in the respective test datasets, we argue that doing so hinders us from adequately capturing the behavior of DNN models and from having realistic expectations about their accuracy. Therefore, we propose a principled evaluation protocol that is suitable for performing comparative investigations of the accuracy of a DNN model on multiple test datasets, leveraging subsets of datapoints that can be selected using different criteria, including uncertainty-related information. By making use of this new evaluation protocol, we determined the accuracy of $564$ DNN models on both (1) the CIFAR-10 and ImageNet datasets and (2) their replication datasets. Our experimental results indicate that the observed accuracy degradation between established benchmark datasets and their replications is consistently lower (that is, models do perform better on the replication test datasets) than the accuracy degradation reported in published works, with these published works relying on conventional evaluation approaches that do not utilize uncertainty-related information.