 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Benchmark Lottery on ImageNet: Do Marginal Improvements Translate to Improvements on Similar Datasets?
Paper and Code
Jan 26, 2025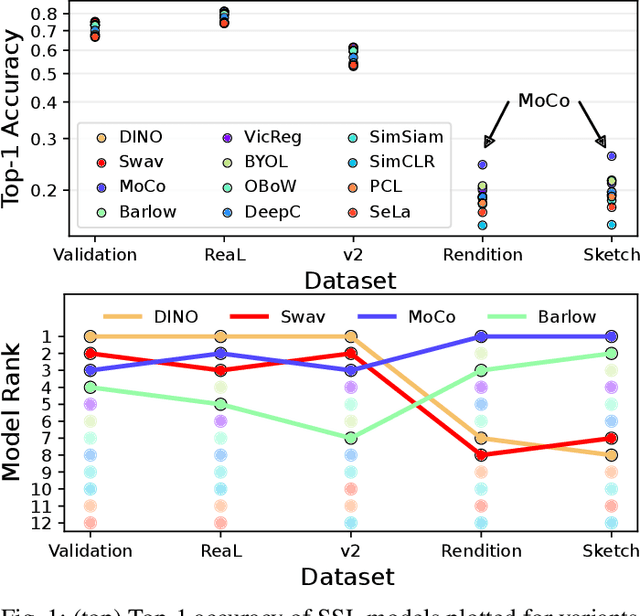

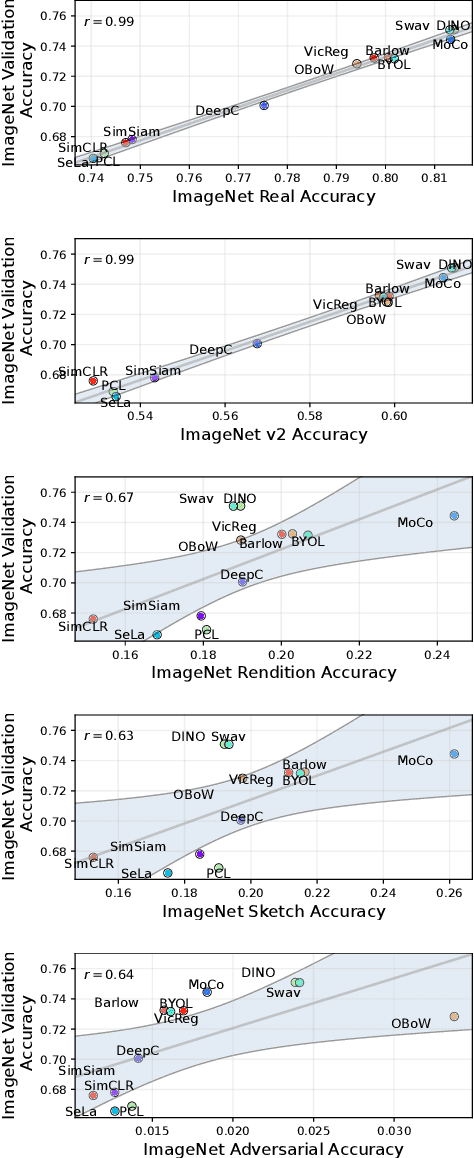
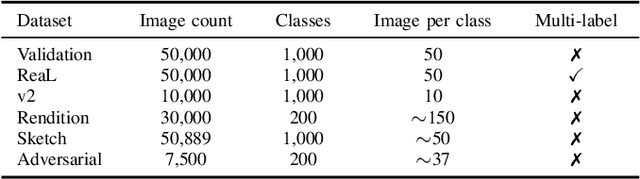
Machine learning (ML) research strongly relies on benchmarks in order to determine the relative effectiveness of newly proposed models. Recently, a number of prominent research effort argued that a number of models that improve the state-of-the-art by a small margin tend to do so by winning what they call a "benchmark lottery". An important benchmark in the field of machine learning and computer vision is the ImageNet where newly proposed models are often showcased based on their performance on this dataset. Given the large number of self-supervised learning (SSL) frameworks that has been proposed in the past couple of years each coming with marginal improvements on the ImageNet dataset, in this work, we evaluate whether those marginal improvements on ImageNet translate to improvements on similar datasets or not. To do so, we investigate twelve popular SSL frameworks on five ImageNet variants and discover that models that seem to perform well on ImageNet may experience significant performance declines on similar datasets. Specifically, state-of-the-art frameworks such as DINO and Swav, which are praised for their performance, exhibit substantial drops in performance while MoCo and Barlow Twins displays comparatively good results. As a result, we argue that otherwise good and desirable properties of models remain hidden when benchmarking is only performed on the ImageNet validation set, making us call for more adequate benchmarking. To avoid the "benchmark lottery" on ImageNet and to ensure a fair benchmarking process, we investigate the usage of a unified metric that takes into account the performance of models on other ImageNet variant datasets.