 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Training Elicits Concise Reasoning in Large Language Models
Feb 28, 2025Chain-of-thought (CoT) reasoning has enabled large language models (LLMs) to utilize additional computation through intermediate tokens to solve complex tasks. However, we posit that typical reasoning traces contain many redundant tokens, incurring extraneous inference costs. Upon examination of the output distribution of current LLMs, we find evidence on their latent ability to reason more concisely, relative to their default behavior. To elicit this capability, we propose simple fine-tuning methods which leverage self-generated concise reasoning paths obtained by best-of-N sampling and few-shot conditioning, in task-specific settings. Our combined method achieves a 30% reduction in output tokens on average, across five model families on GSM8K and MATH, while maintaining average accuracy. By exploiting the fundamental stochasticity and in-context learning capabilities of LLMs, our self-training approach robustly elicits concise reasoning on a wide range of models, including those with extensive post-training. Code is available at https://github.com/TergelMunkhbat/concise-reasoning
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
Block Transformer: Global-to-Local Language Modeling for Fast Inference
Jun 04, 2024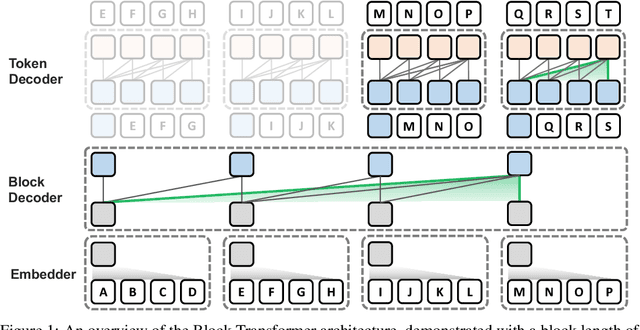
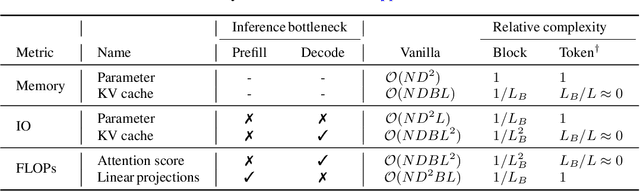
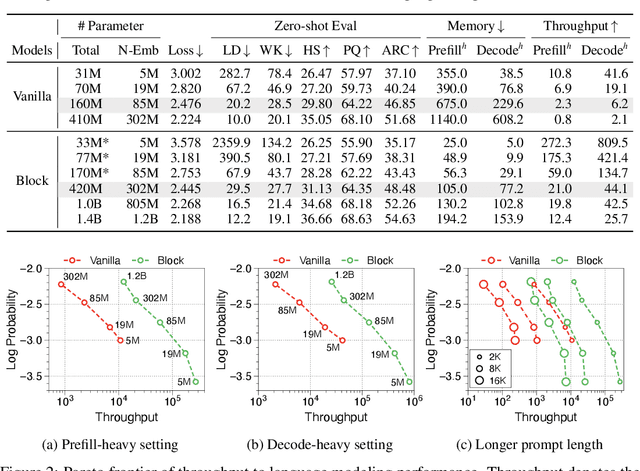
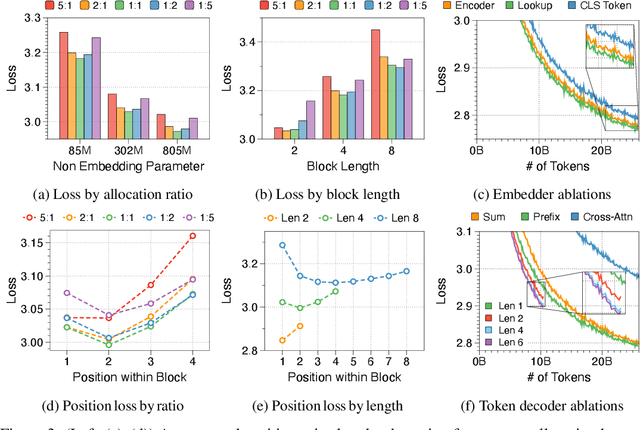
This paper presents the Block Transformer architecture which adopts hierarchical global-to-local modeling to autoregressive transformers to mitigate the inference bottlenecks of self-attention. To apply self-attention, the key-value (KV) cache of all previous sequences must be retrieved from memory at every decoding step. Thereby, this KV cache IO becomes a significant bottleneck in batch inference. We notice that these costs stem from applying self-attention on the global context, therefore we isolate the expensive bottlenecks of global modeling to lower layers and apply fast local modeling in upper layers. To mitigate the remaining costs in the lower layers, we aggregate input tokens into fixed size blocks and then apply self-attention at this coarse level. Context information is aggregated into a single embedding to enable upper layers to decode the next block of tokens, without global attention. Free of global attention bottlenecks, the upper layers can fully utilize the compute hardware to maximize inference throughput. By leveraging global and local modules, the Block Transformer architecture demonstrates 10-20x gains in inference throughput compared to vanilla transformers with equivalent perplexity. Our work introduces a new approach to optimize language model inference through novel application of global-to-local modeling. Code is available at https://github.com/itsnamgyu/block-transformer.
HARE: Explainable Hate Speech Detection with Step-by-Step Reasoning
Nov 01, 2023



With the proliferation of social media, accurate detection of hate speech has become critical to ensure safety online. To combat nuanced forms of hate speech, it is important to identify and thoroughly explain hate speech to help users understand its harmful effects. Recent benchmarks have attempted to tackle this issue by training generative models on free-text annotations of implications in hateful text. However, we find significant reasoning gaps in the existing annotations schemes, which may hinder the supervision of detection models. In this paper, we introduce a hate speech detection framework, HARE, which harnesses the reasoning capabilities of large language models (LLMs) to fill these gaps in explanations of hate speech, thus enabling effective supervision of detection models. Experiments on SBIC and Implicit Hate benchmarks show that our method, using model-generated data, consistently outperforms baselines, using existing free-text human annotations. Analysis demonstrates that our method enhances the explanation quality of trained models and improves generalization to unseen datasets. Our code is available at https://github.com/joonkeekim/hare-hate-speech.git.
Cross-Modal Retrieval Meets Inference:Improving Zero-Shot Classification with Cross-Modal Retrieval
Aug 29, 2023
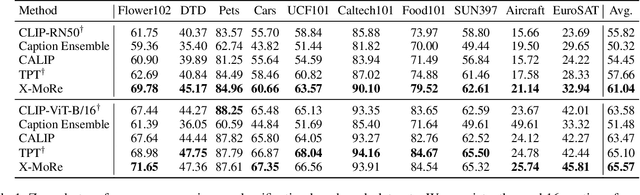
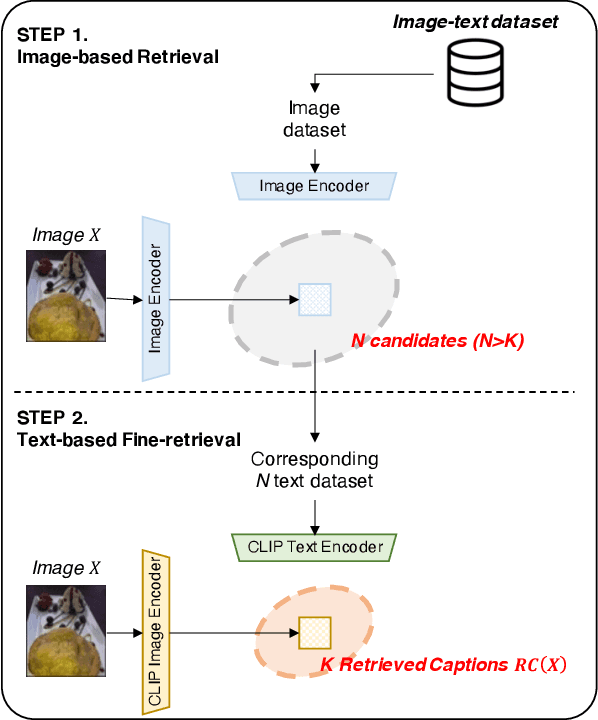

Contrastive language-image pre-training (CLIP) has demonstrated remarkable zero-shot classification ability, namely image classification using novel text labels. Existing works have attempted to enhance CLIP by fine-tuning on downstream tasks, but these have inadvertently led to performance degradation on unseen classes, thus harming zero-shot generalization. This paper aims to address this challenge by leveraging readily available image-text pairs from an external dataset for cross-modal guidance during inference. To this end, we propose X-MoRe, a novel inference method comprising two key steps: (1) cross-modal retrieval and (2) modal-confidence-based ensemble. Given a query image, we harness the power of CLIP's cross-modal representations to retrieve relevant textual information from an external image-text pair dataset. Then, we assign higher weights to the more reliable modality between the original query image and retrieved text, contributing to the final prediction. X-MoRe demonstrates robust performance across a diverse set of tasks without the need for additional training, showcasing the effectiveness of utilizing cross-modal features to maximize CLIP's zero-shot ability.
Large Language Models Are Reasoning Teachers
Dec 20, 2022Language models (LMs) have demonstrated remarkable performance on downstream tasks, using in-context exemplars or human instructions. Recent works have shown that chain-of-thought (CoT) prompting can elicit models to solve complex reasoning tasks, step-by-step. However, the efficacy of prompt-based CoT methods is restricted to very large LMs such as GPT-3 (175B), thus limiting deployability. In this paper, we revisit the fine-tuning approach to enable complex reasoning in smaller LMs, optimized to efficiently perform a specific task. We propose Fine-tune-CoT, a method that leverages the capabilities of very large LMs to generate reasoning samples and teach smaller models via fine-tuning. We evaluate our method on publicly available LMs across a wide range of complex tasks and model sizes. We find that Fine-tune-CoT enables substantial reasoning capability in small models, whereas previous prompt-based baselines exhibit near-random performance. Student models can even outperform the teacher in some tasks while reducing model size requirements by several orders of magnitude. We conduct extensive ablations and sample studies to understand the reasoning capabilities of student models. We also identify several important nuances that have been overlooked in concurrent fine-tuning works on CoT and address them in our analysis.
Benchmark Dataset for Precipitation Forecasting by Post-Processing the Numerical Weather Prediction
Jun 30, 2022
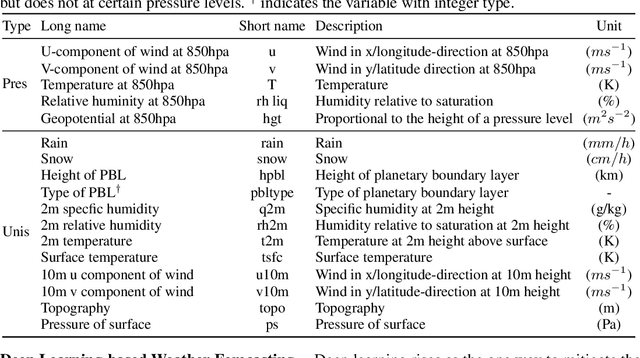
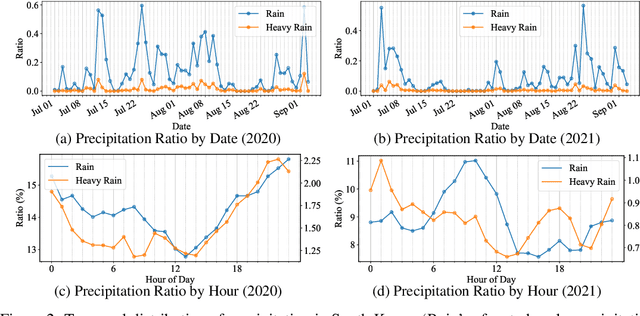
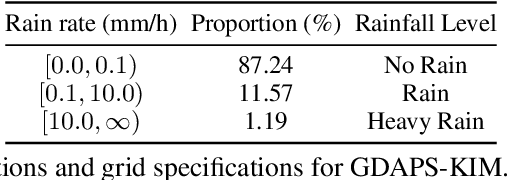
Precipitation forecasting is an important scientific challenge that has wide-reaching impacts on society. Historically, this challenge has been tackled using numerical weather prediction (NWP) models, grounded on physics-based simulations. Recently, many works have proposed an alternative approach, using end-to-end deep learning (DL) models to replace physics-based NWP. While these DL methods show improved performance and computational efficiency, they exhibit limitations in long-term forecasting and lack the explainability of NWP models. In this work, we present a hybrid NWP-DL workflow to fill the gap between standalone NWP and DL approaches. Under this workflow, the NWP output is fed into a deep model, which post-processes the data to yield a refined precipitation forecast. The deep model is trained with supervision, using Automatic Weather Station (AWS) observations as ground-truth labels. This can achieve the best of both worlds, and can even benefit from future improvements in NWP technology. To facilitate study in this direction, we present a novel dataset focused on the Korean Peninsula, termed KoMet (Korea Meteorological Dataset), comprised of NWP predictions and AWS observations. For NWP, we use the Global Data Assimilation and Prediction Systems-Korea Integrated Model (GDAPS-KIM).
ReFine: Re-randomization before Fine-tuning for Cross-domain Few-shot Learning
May 11, 2022
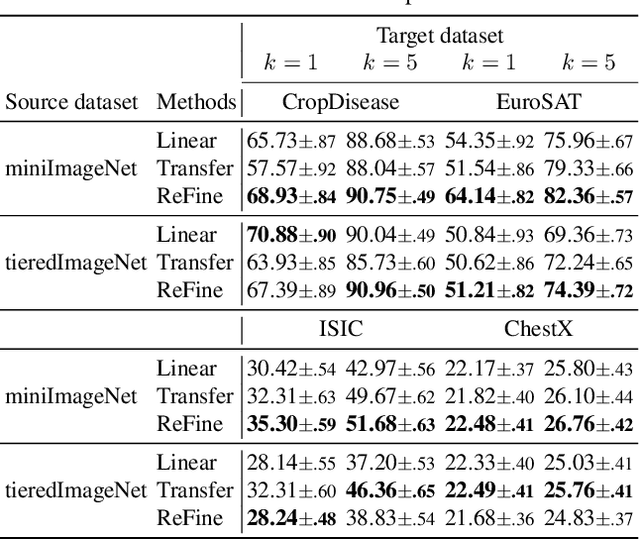
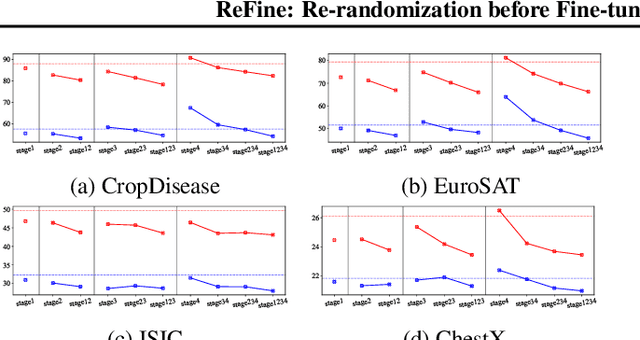
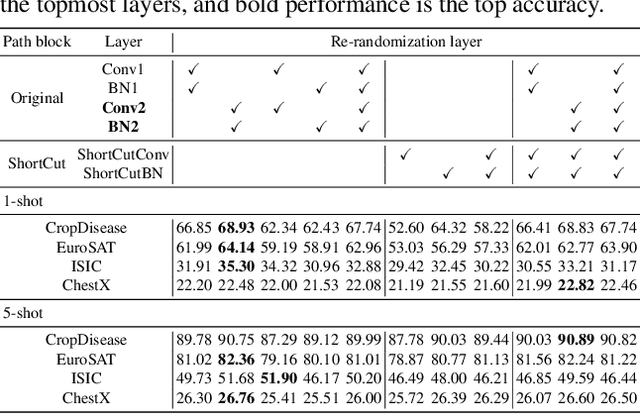
Cross-domain few-shot learning (CD-FSL), where there are few target samples under extreme differences between source and target domains, has recently attracted huge attention. For CD-FSL, recent studies generally have developed transfer learning based approaches that pre-train a neural network on popular labeled source domain datasets and then transfer it to target domain data. Although the labeled datasets may provide suitable initial parameters for the target data, the domain difference between the source and target might hinder the fine-tuning on the target domain. This paper proposes a simple yet powerful method that re-randomizes the parameters fitted on the source domain before adapting to the target data. The re-randomization resets source-specific parameters of the source pre-trained model and thus facilitates fine-tuning on the target domain, improving few-shot performance.
Understanding Cross-Domain Few-Shot Learning: An Experimental Study
Feb 08, 2022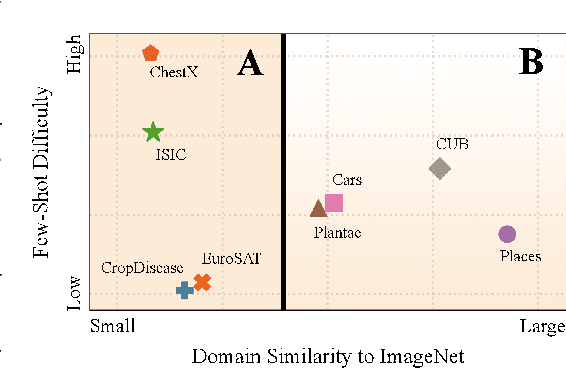
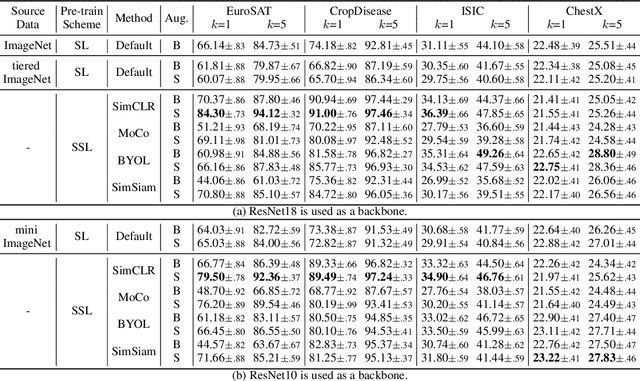
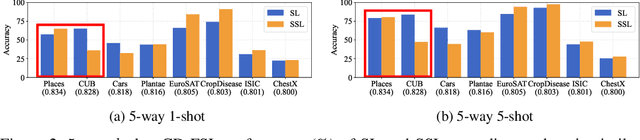
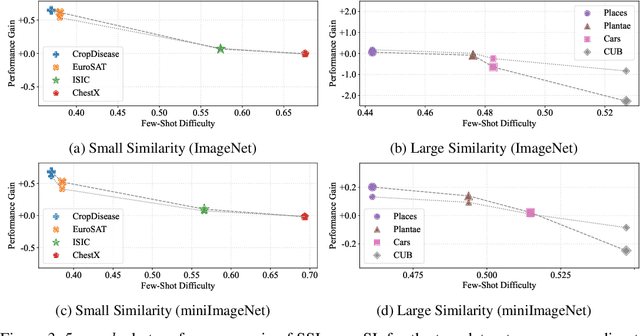
Cross-domain few-shot learning has drawn increasing attention for handling large differences between the source and target domains--an important concern in real-world scenarios. To overcome these large differences, recent works have considered exploiting small-scale unlabeled data from the target domain during the pre-training stage. This data enables self-supervised pre-training on the target domain, in addition to supervised pre-training on the source domain. In this paper, we empirically investigate scenarios under which it is advantageous to use each pre-training scheme, based on domain similarity and few-shot difficulty: performance gain of self-supervised pre-training over supervised pre-training increases when domain similarity is smaller or few-shot difficulty is lower. We further design two pre-training schemes, mixed-supervised and two-stage learning, that improve performance. In this light, we present seven findings for CD-FSL which are supported by extensive experiments and analyses on three source and eight target benchmark datasets with varying levels of domain similarity and few-shot difficulty. Our code is available at https://anonymous.4open.science/r/understandingCDFSL.