 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Cross-Domain Few-Shot Learning: An Experimental Study
Paper and Code
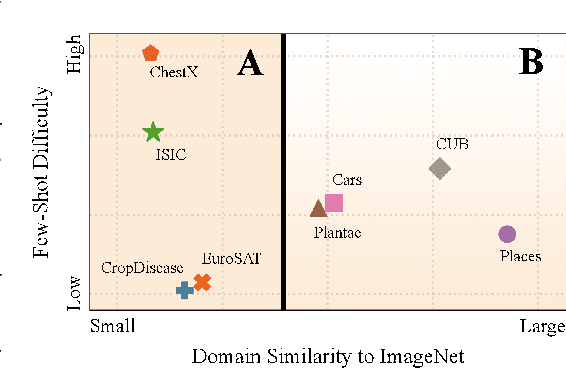
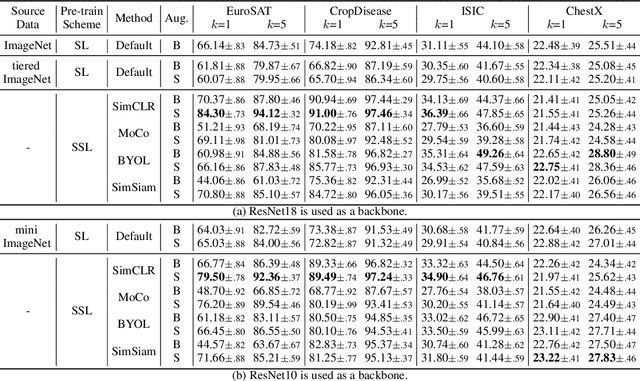
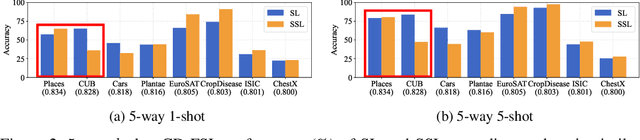
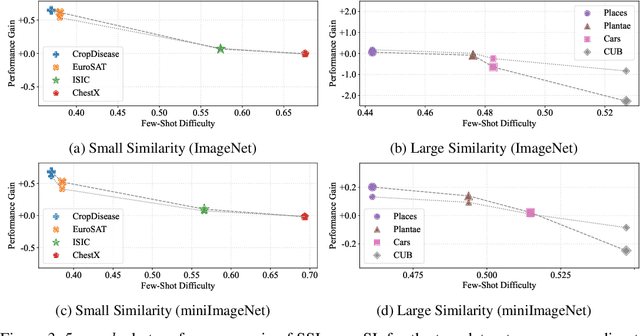
Cross-domain few-shot learning has drawn increasing attention for handling large differences between the source and target domains--an important concern in real-world scenarios. To overcome these large differences, recent works have considered exploiting small-scale unlabeled data from the target domain during the pre-training stage. This data enables self-supervised pre-training on the target domain, in addition to supervised pre-training on the source domain. In this paper, we empirically investigate scenarios under which it is advantageous to use each pre-training scheme, based on domain similarity and few-shot difficulty: performance gain of self-supervised pre-training over supervised pre-training increases when domain similarity is smaller or few-shot difficulty is lower. We further design two pre-training schemes, mixed-supervised and two-stage learning, that improve performance. In this light, we present seven findings for CD-FSL which are supported by extensive experiments and analyses on three source and eight target benchmark datasets with varying levels of domain similarity and few-shot difficulty. Our code is available at https://anonymous.4open.science/r/understandingCDFSL.