 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-Docent: Instruction Tuning with Multimodal Large Language Model to Support Art Appreciation Education
Feb 09, 2024



Art appreciation is vital in nurturing critical thinking and emotional intelligence among learners. However, traditional art appreciation education has often been hindered by limited access to art resources, especially for disadvantaged students, and an imbalanced emphasis on STEM subjects in mainstream education. In response to these challenges, recent technological advancements have paved the way for innovative solutions. This study explores the application of multi-modal large language models (MLLMs) in art appreciation education, focusing on developing LLaVA-Docent, a model that leverages these advancements. Our approach involved a comprehensive literature review and consultations with experts in the field, leading to developing a robust data framework. Utilizing this framework, we generated a virtual dialogue dataset that was leveraged by GPT-4. This dataset was instrumental in training the MLLM, named LLaVA-Docent. Six researchers conducted quantitative and qualitative evaluations of LLaVA-Docent to assess its effectiveness, benchmarking it against the GPT-4 model in a few-shot setting. The evaluation process revealed distinct strengths and weaknesses of the LLaVA-Docent model. Our findings highlight the efficacy of LLaVA-Docent in enhancing the accessibility and engagement of art appreciation education. By harnessing the potential of MLLMs, this study makes a significant contribution to the field of art education, proposing a novel methodology that reimagines the way art appreciation is taught and experienced.
Co-attention Graph Pooling for Efficient Pairwise Graph Interaction Learning
Jul 28, 2023



Graph Neural Networks (GNNs) have proven to be effective in processing and learning from graph-structured data. However, previous works mainly focused on understanding single graph inputs while many real-world applications require pair-wise analysis for graph-structured data (e.g., scene graph matching, code searching, and drug-drug interaction prediction). To this end, recent works have shifted their focus to learning the interaction between pairs of graphs. Despite their improved performance, these works were still limited in that the interactions were considered at the node-level, resulting in high computational costs and suboptimal performance. To address this issue, we propose a novel and efficient graph-level approach for extracting interaction representations using co-attention in graph pooling. Our method, Co-Attention Graph Pooling (CAGPool), exhibits competitive performance relative to existing methods in both classification and regression tasks using real-world datasets, while maintaining lower computational complexity.
* Published at IEEE Access
Can Language Models be Biomedical Knowledge Bases?
Sep 15, 2021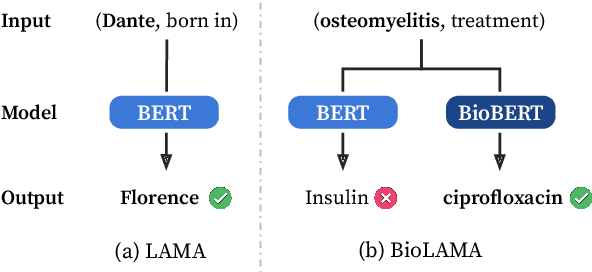



Pre-trained language models (LMs) have become ubiquitous in solving various natural language processing (NLP) tasks. There has been increasing interest in what knowledge these LMs contain and how we can extract that knowledge, treating LMs as knowledge bases (KBs). While there has been much work on probing LMs in the general domain, there has been little attention to whether these powerful LMs can be used as domain-specific KBs. To this end, we create the BioLAMA benchmark, which is comprised of 49K biomedical factual knowledge triples for probing biomedical LMs. We find that biomedical LMs with recently proposed probing methods can achieve up to 18.51% Acc@5 on retrieving biomedical knowledge. Although this seems promising given the task difficulty, our detailed analyses reveal that most predictions are highly correlated with prompt templates without any subjects, hence producing similar results on each relation and hindering their capabilities to be used as domain-specific KBs. We hope that BioLAMA can serve as a challenging benchmark for biomedical factual probing.