 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALUEFLOW: Toward Pluralistic and Steerable Value-based Alignment in Large Language Models
Feb 03, 2026Aligning Large Language Models (LLMs) with the diverse spectrum of human values remains a central challenge: preference-based methods often fail to capture deeper motivational principles. Value-based approaches offer a more principled path, yet three gaps persist: extraction often ignores hierarchical structure, evaluation detects presence but not calibrated intensity, and the steerability of LLMs at controlled intensities remains insufficiently understood. To address these limitations, we introduce VALUEFLOW, the first unified framework that spans extraction, evaluation, and steering with calibrated intensity control. The framework integrates three components: (i) HIVES, a hierarchical value embedding space that captures intra- and cross-theory value structure; (ii) the Value Intensity DataBase (VIDB), a large-scale resource of value-labeled texts with intensity estimates derived from ranking-based aggregation; and (iii) an anchor-based evaluator that produces consistent intensity scores for model outputs by ranking them against VIDB panels. Using VALUEFLOW, we conduct a comprehensive large-scale study across ten models and four value theories, identifying asymmetries in steerability and composition laws for multi-value control. This paper establishes a scalable infrastructure for evaluating and controlling value intensity, advancing pluralistic alignment of LLMs.
KTCF: Actionable Recourse in Knowledge Tracing via Counterfactual Explanations for Education
Jan 14, 2026Using Artificial Intelligence to improve teaching and learning benefits greater adaptivity and scalability in education. Knowledge Tracing (KT) is recognized for student modeling task due to its superior performance and application potential in education. To this end, we conceptualize and investigate counterfactual explanation as the connection from XAI for KT to education. Counterfactual explanations offer actionable recourse, are inherently causal and local, and easy for educational stakeholders to understand who are often non-experts. We propose KTCF, a counterfactual explanation generation method for KT that accounts for knowledge concept relationships, and a post-processing scheme that converts a counterfactual explanation into a sequence of educational instructions. We experiment on a large-scale educational dataset and show our KTCF method achieves superior and robust performance over existing methods, with improvements ranging from 5.7% to 34% across metrics. Additionally, we provide a qualitative evaluation of our post-processing scheme, demonstrating that the resulting educational instructions help in reducing large study burden. We show that counterfactuals have the potential to advance the responsible and practical use of AI in education. Future works on XAI for KT may benefit from educationally grounded conceptualization and developing stakeholder-centered methods.
Don't Let It Fade: Preserving Edits in Diffusion Language Models via Token Timestep Allocation
Oct 30, 2025While diffusion language models (DLMs) enable fine-grained refinement, their practical controllability remains fragile. We identify and formally characterize a central failure mode called update forgetting, in which uniform and context agnostic updates induce token level fluctuations across timesteps, erasing earlier semantic edits and disrupting the cumulative refinement process, thereby degrading fluency and coherence. As this failure originates in uniform and context agnostic updates, effective control demands explicit token ordering. We propose Token Timestep Allocation (TTA), which realizes soft and semantic token ordering via per token timestep schedules: critical tokens are frozen early, while uncertain tokens receive continued refinement. This timestep based ordering can be instantiated as either a fixed policy or an adaptive policy driven by task signals, thereby supporting a broad spectrum of refinement strategies. Because it operates purely at inference time, it applies uniformly across various DLMs and naturally extends to diverse supervision sources. Empirically, TTA improves controllability and fluency: on sentiment control, it yields more than 20 percent higher accuracy and nearly halves perplexity using less than one fifth the steps; in detoxification, it lowers maximum toxicity (12.2 versus 14.5) and perplexity (26.0 versus 32.0). Together, these results demonstrate that softened ordering via timestep allocation is the critical lever for mitigating update forgetting and achieving stable and controllable diffusion text generation.
On Integer Programming for the Binarized Neural Network Verification Problem
Oct 01, 2025



Binarized neural networks (BNNs) are feedforward neural networks with binary weights and activation functions. In the context of using a BNN for classification, the verification problem seeks to determine whether a small perturbation of a given input can lead it to be misclassified by the BNN, and the robustness of the BNN can be measured by solving the verification problem over multiple inputs. The BNN verification problem can be formulated as an integer programming (IP) problem. However, the natural IP formulation is often challenging to solve due to a large integrality gap induced by big-$M$ constraints. We present two techniques to improve the IP formulation. First, we introduce a new method for obtaining a linear objective for the multi-class setting. Second, we introduce a new technique for generating valid inequalities for the IP formulation that exploits the recursive structure of BNNs. We find that our techniques enable verifying BNNs against a higher range of input perturbation than existing IP approaches within a limited time.
SECOND: Mitigating Perceptual Hallucination in Vision-Language Models via Selective and Contrastive Decoding
Jun 10, 2025Despite significant advancements in Vision-Language Models (VLMs), the performance of existing VLMs remains hindered by object hallucination, a critical challenge to achieving accurate visual understanding. To address this issue, we propose SECOND: Selective and Contrastive Decoding, a novel approach that enables VLMs to effectively leverage multi-scale visual information with an object-centric manner, closely aligning with human visual perception. SECOND progressively selects and integrates multi-scale visual information, facilitating a more precise interpretation of images. By contrasting these visual information iteratively, SECOND significantly reduces perceptual hallucinations and outperforms a wide range of benchmarks. Our theoretical analysis and experiments highlight the largely unexplored potential of multi-scale application in VLMs, showing that prioritizing and contrasting across scales outperforms existing methods.
Counterfactual Fairness Evaluation of Machine Learning Models on Educational Datasets
Apr 15, 2025As machine learning models are increasingly used in educational settings, from detecting at-risk students to predicting student performance, algorithmic bias and its potential impacts on students raise critical concerns about algorithmic fairness. Although group fairness is widely explored in education, works on individual fairness in a causal context are understudied, especially on counterfactual fairness. This paper explores the notion of counterfactual fairness for educational data by conducting counterfactual fairness analysis of machine learning models on benchmark educational datasets. We demonstrate that counterfactual fairness provides meaningful insight into the causality of sensitive attributes and causal-based individual fairness in education.
CKConv: Learning Feature Voxelization for Point Cloud Analysis
Jul 27, 2021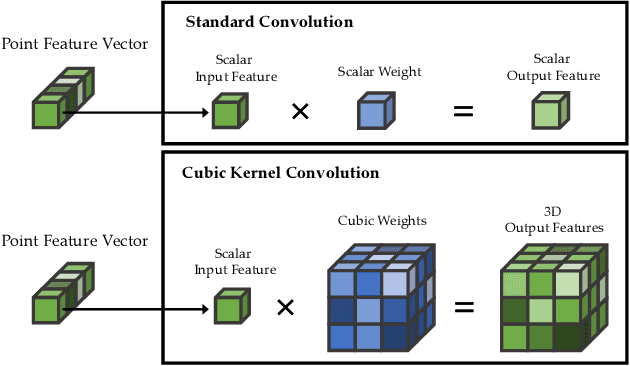
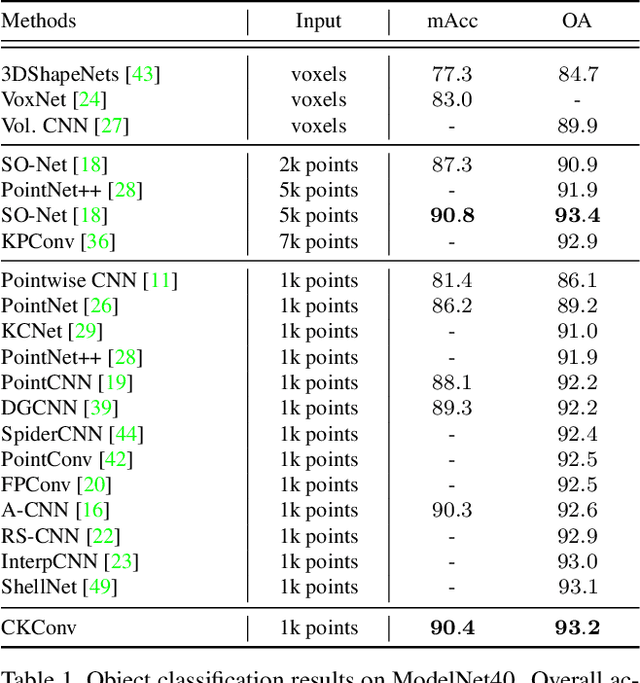
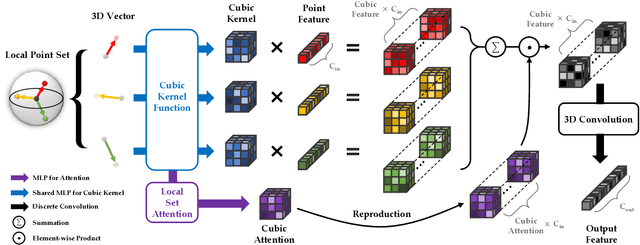

Despite the remarkable success of deep learning, optimal convolution operation on point cloud remains indefinite due to its irregular data structure. In this paper, we present Cubic Kernel Convolution (CKConv) that learns to voxelize the features of local points by exploiting both continuous and discrete convolutions. Our continuous convolution uniquely employs a 3D cubic form of kernel weight representation that splits a feature into voxels in embedding space. By consecutively applying discrete 3D convolutions on the voxelized features in a spatial manner, preceding continuous convolution is forced to learn spatial feature mapping, i.e., feature voxelization. In this way, geometric information can be detailed by encoding with subdivided features, and our 3D convolutions on these fixed structured data do not suffer from discretization artifacts thanks to voxelization in embedding space. Furthermore, we propose a spatial attention module, Local Set Attention (LSA), to provide comprehensive structure awareness within the local point set and hence produce representative features. By learning feature voxelization with LSA, CKConv can extract enriched features for effective point cloud analysis. We show that CKConv has great applicability to point cloud processing tasks including object classification, object part segmentation, and scene semantic segmentation with state-of-the-art results.
Robust Lane Detection via Expanded Self Attention
Feb 14, 2021

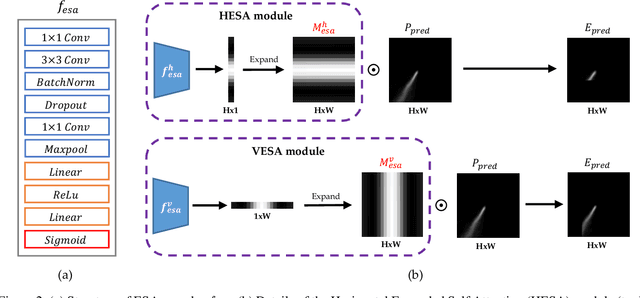

The image-based lane detection algorithm is one of the key technologies in autonomous vehicles. Modern deep learning methods achieve high performance in lane detection, but it is still difficult to accurately detect lanes in challenging situations such as congested roads and extreme lighting conditions. To be robust on these challenging situations, it is important to extract global contextual information even from limited visual cues. In this paper, we propose a simple but powerful self-attention mechanism optimized for lane detection called the Expanded Self Attention (ESA) module. Inspired by the simple geometric structure of lanes, the proposed method predicts the confidence of a lane along the vertical and horizontal directions in an image. The prediction of the confidence enables estimating occluded locations by extracting global contextual information. ESA module can be easily implemented and applied to any encoder-decoder-based model without increasing the inference time. The performance of our method is evaluated on three popular lane detection benchmarks (TuSimple, CULane and BDD100K). We achieve state-of-the-art performance in CULane and BDD100K and distinct improvement on TuSimple dataset. The experimental results show that our approach is robust to occlusion and extreme lighting conditions.
False Positive Removal for 3D Vehicle Detection with Penetrated Point Classifier
May 28, 2020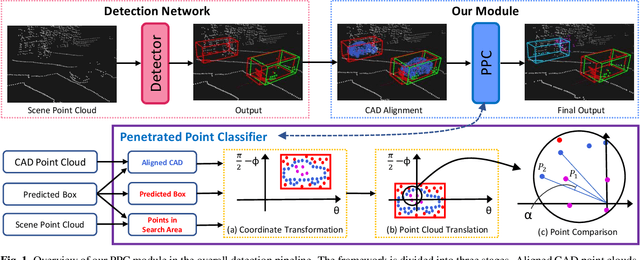

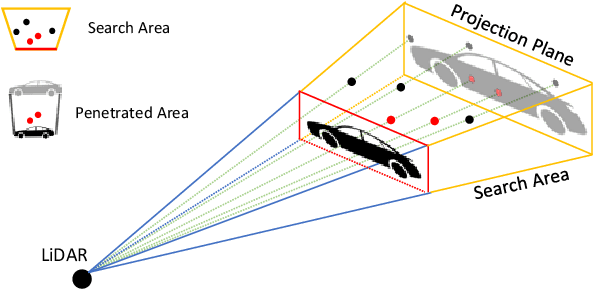
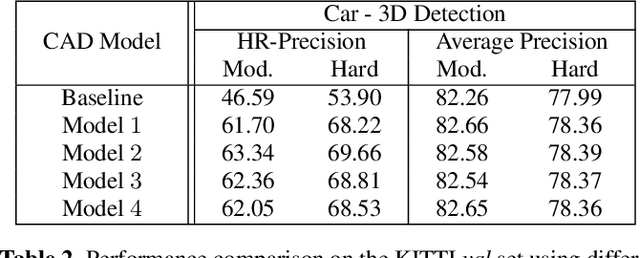
Recently, researchers have been leveraging LiDAR point cloud for higher accuracy in 3D vehicle detection. Most state-of-the-art methods are deep learning based, but are easily affected by the number of points generated on the object. This vulnerability leads to numerous false positive boxes at high recall positions, where objects are occasionally predicted with few points. To address the issue, we introduce Penetrated Point Classifier (PPC) based on the underlying property of LiDAR that points cannot be generated behind vehicles. It determines whether a point exists behind the vehicle of the predicted box, and if does, the box is distinguished as false positive. Our straightforward yet unprecedented approach is evaluated on KITTI dataset and achieved performance improvement of PointRCNN, one of the state-of-the-art methods. The experiment results show that precision at the highest recall position is dramatically increased by 15.46 percentage points and 14.63 percentage points on the moderate and hard difficulty of car class, respectively.
Driver Behavior Recognition via Interwoven Deep Convolutional Neural Nets with Multi-stream Inputs
Nov 22, 2018
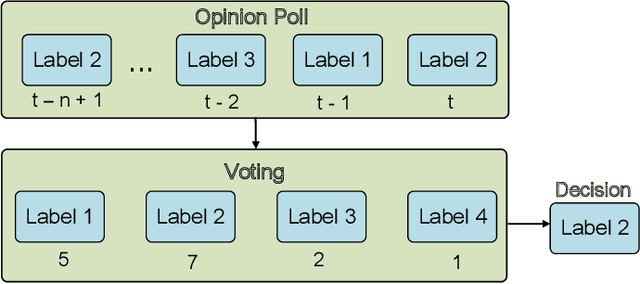
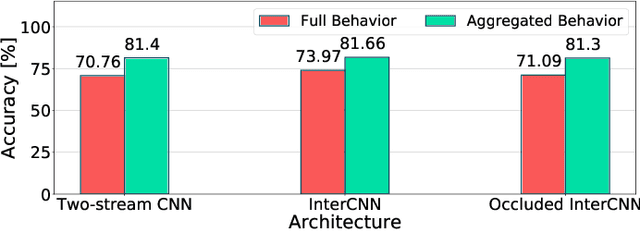
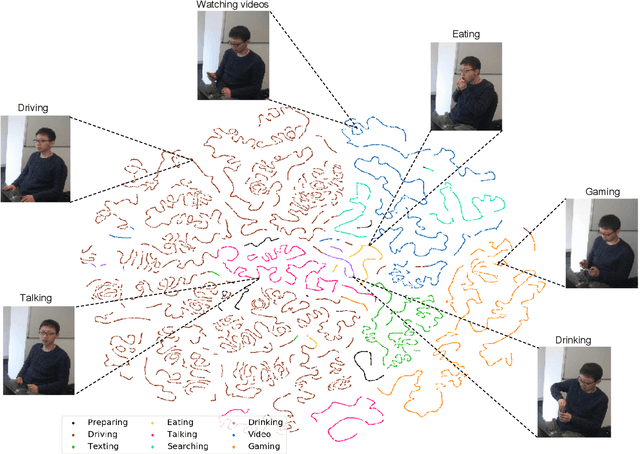
Recognizing driver behaviors is becoming vital for in-vehicle systems that seek to reduce the incidence of car accidents rooted in cognitive distraction. In this paper, we harness the exceptional feature extraction abilities of deep learning and propose a dedicated Interwoven Deep Convolutional Neural Network (InterCNN) architecture to tackle the accurate classification of driver behaviors in real-time. The proposed solution exploits information from multi-stream inputs, i.e., in-vehicle cameras with different fields of view and optical flows computed based on recorded images, and merges through multiple fusion layers abstract features that it extracts. This builds a tight ensembling system, which significantly improves the robustness of the model. We further introduce a temporal voting scheme based on historical inference instances, in order to enhance accuracy. Experiments conducted with a real world dataset that we collect in a mock-up car environment demonstrate that the proposed InterCNN with MobileNet convolutional blocks can classify 9 different behaviors with 73.97% accuracy, and 5 aggregated behaviors with 81.66% accuracy. Our architecture is highly computationally efficient, as it performs inferences within 15ms, which satisfies the real-time constraints of intelligent cars. In addition, our InterCNN is robust to lossy input, as the classification remains accurate when two input streams are occluded.