 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Networks Decoded: Targeted and Robust Analysis of Neural Network Decisions via Causal Explanations and Reasoning
Oct 07, 2024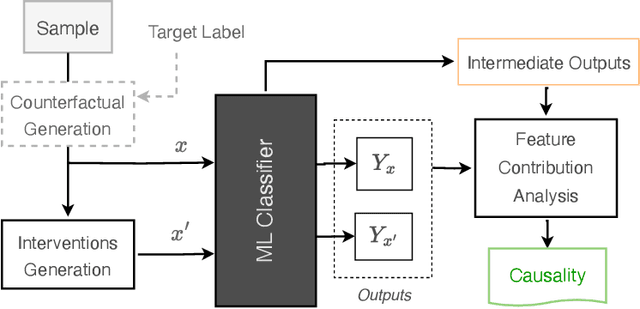
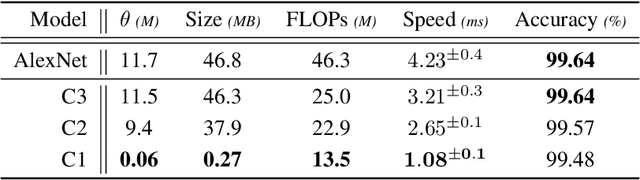
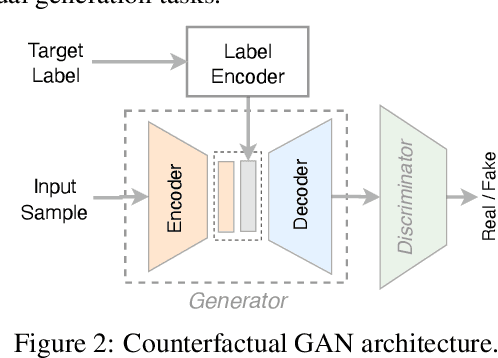
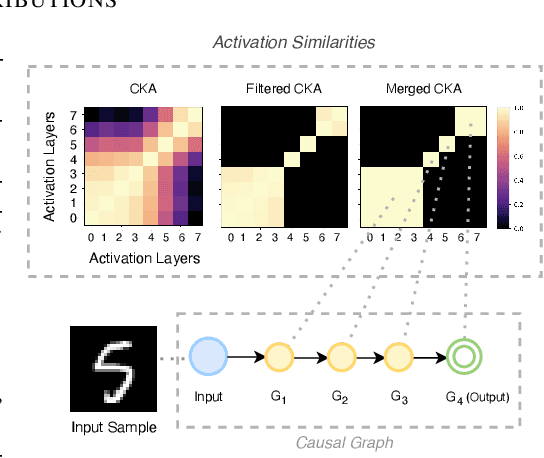
Despite their success and widespread adoption, the opaque nature of deep neural networks (DNNs) continues to hinder trust, especially in critical applications. Current interpretability solutions often yield inconsistent or oversimplified explanations, or require model changes that compromise performance. In this work, we introduce TRACER, a novel method grounded in causal inference theory designed to estimate the causal dynamics underpinning DNN decisions without altering their architecture or compromising their performance. Our approach systematically intervenes on input features to observe how specific changes propagate through the network, affecting internal activations and final outputs. Based on this analysis, we determine the importance of individual features, and construct a high-level causal map by grouping functionally similar layers into cohesive causal nodes, providing a structured and interpretable view of how different parts of the network influence the decisions. TRACER further enhances explainability by generating counterfactuals that reveal possible model biases and offer contrastive explanations for misclassifications. Through comprehensive evaluations across diverse datasets, we demonstrate TRACER's effectiveness over existing methods and show its potential for creating highly compressed yet accurate models, illustrating its dual versatility in both understanding and optimizing DNNs.
Amoeba: Circumventing ML-supported Network Censorship via Adversarial Reinforcement Learning
Oct 31, 2023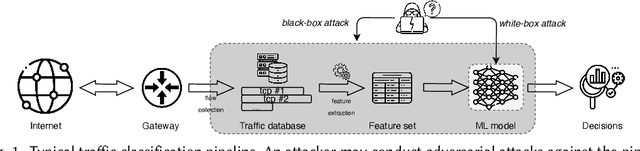
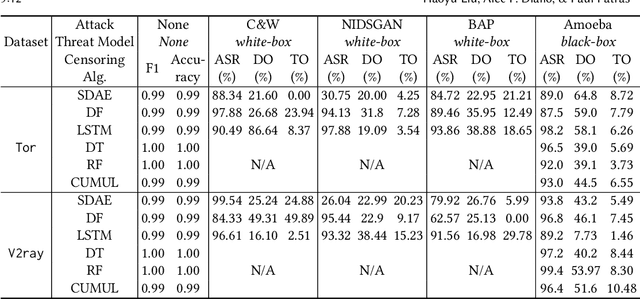
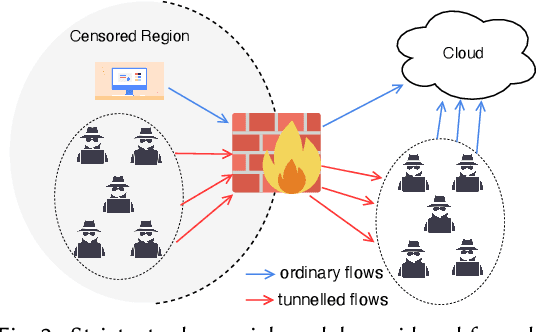
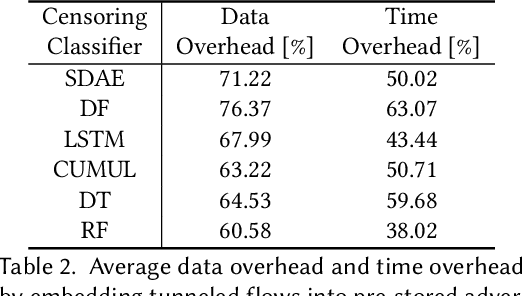
Embedding covert streams into a cover channel is a common approach to circumventing Internet censorship, due to censors' inability to examine encrypted information in otherwise permitted protocols (Skype, HTTPS, etc.). However, recent advances in machine learning (ML) enable detecting a range of anti-censorship systems by learning distinct statistical patterns hidden in traffic flows. Therefore, designing obfuscation solutions able to generate traffic that is statistically similar to innocuous network activity, in order to deceive ML-based classifiers at line speed, is difficult. In this paper, we formulate a practical adversarial attack strategy against flow classifiers as a method for circumventing censorship. Specifically, we cast the problem of finding adversarial flows that will be misclassified as a sequence generation task, which we solve with Amoeba, a novel reinforcement learning algorithm that we design. Amoeba works by interacting with censoring classifiers without any knowledge of their model structure, but by crafting packets and observing the classifiers' decisions, in order to guide the sequence generation process. Our experiments using data collected from two popular anti-censorship systems demonstrate that Amoeba can effectively shape adversarial flows that have on average 94% attack success rate against a range of ML algorithms. In addition, we show that these adversarial flows are robust in different network environments and possess transferability across various ML models, meaning that once trained against one, our agent can subvert other censoring classifiers without retraining.
NetSentry: A Deep Learning Approach to Detecting Incipient Large-scale Network Attacks
Feb 20, 2022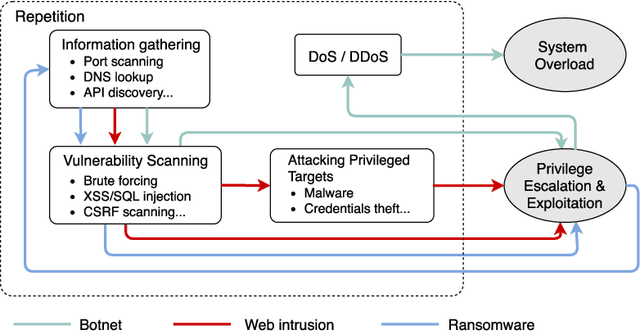
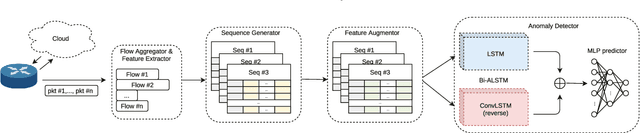

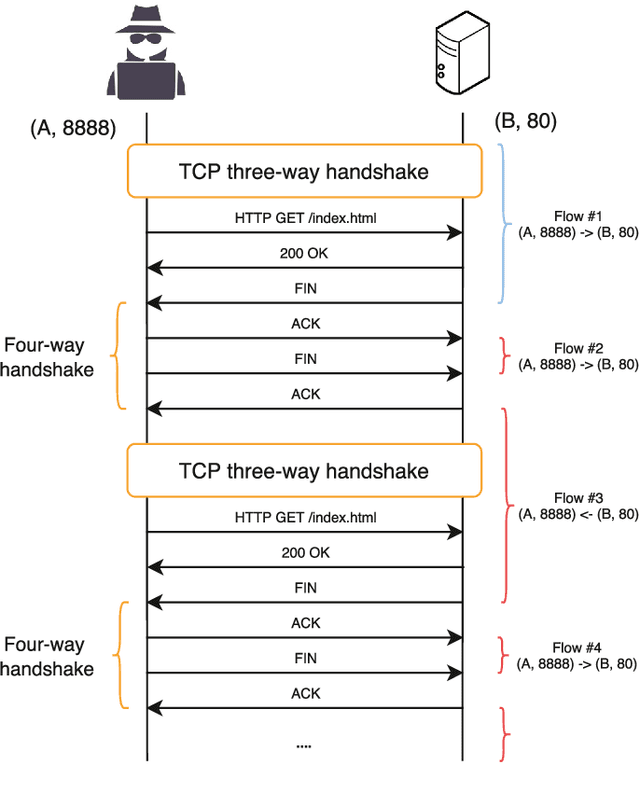
Machine Learning (ML) techniques are increasingly adopted to tackle ever-evolving high-profile network attacks, including DDoS, botnet, and ransomware, due to their unique ability to extract complex patterns hidden in data streams. These approaches are however routinely validated with data collected in the same environment, and their performance degrades when deployed in different network topologies and/or applied on previously unseen traffic, as we uncover. This suggests malicious/benign behaviors are largely learned superficially and ML-based Network Intrusion Detection System (NIDS) need revisiting, to be effective in practice. In this paper we dive into the mechanics of large-scale network attacks, with a view to understanding how to use ML for Network Intrusion Detection (NID) in a principled way. We reveal that, although cyberattacks vary significantly in terms of payloads, vectors and targets, their early stages, which are critical to successful attack outcomes, share many similarities and exhibit important temporal correlations. Therefore, we treat NID as a time-sensitive task and propose NetSentry, perhaps the first of its kind NIDS that builds on Bidirectional Asymmetric LSTM (Bi-ALSTM), an original ensemble of sequential neural models, to detect network threats before they spread. We cross-evaluate NetSentry using two practical datasets, training on one and testing on the other, and demonstrate F1 score gains above 33% over the state-of-the-art, as well as up to 3 times higher rates of detecting attacks such as XSS and web bruteforce. Further, we put forward a novel data augmentation technique that boosts the generalization abilities of a broad range of supervised deep learning algorithms, leading to average F1 score gains above 35%.
CloudLSTM: A Recurrent Neural Model for Spatiotemporal Point-cloud Stream Forecasting
Jul 29, 2019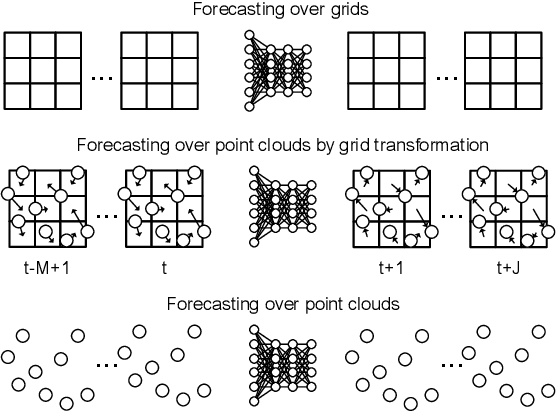
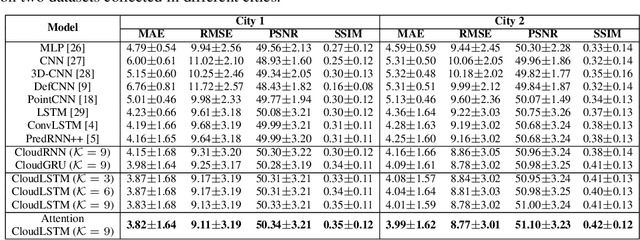
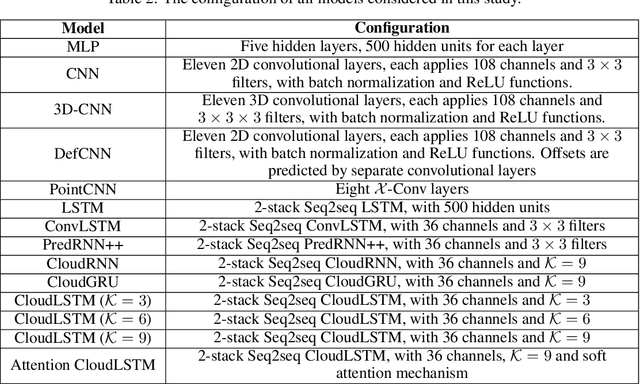
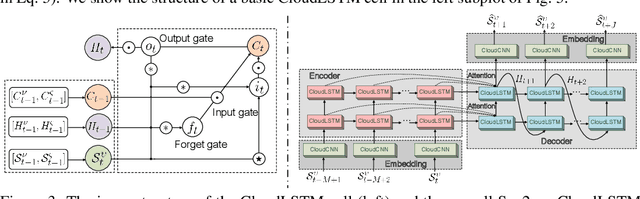
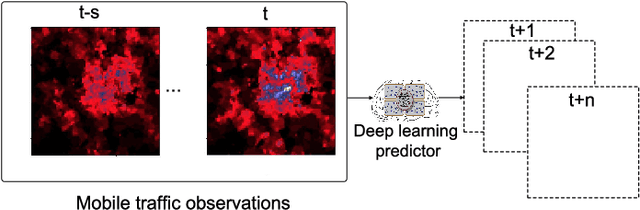
This paper introduces CloudLSTM, a new branch of recurrent neural network models tailored to forecasting over data streams generated by geospatial point-cloud sources. We design a Dynamic Convolution (D-Conv) operator as the core component of CloudLSTMs, which allows performing convolution operations directly over point-clouds and extracts local spatial features from sets of neighboring points that surround different elements of the input. This maintains the permutation invariance of sequence-to-sequence learning frameworks, while enabling learnable neighboring correlations at each time step -- an important aspect in spatiotemporal predictive learning. The D-Conv operator resolves the grid-structural data requirements of existing spatiotemporal forecasting models (e.g. ConvLSTM) and can be easily plugged into traditional LSTM architectures with sequence-to-sequence learning and attention mechanisms. As a case study, we perform antenna-level forecasting of the data traffic generated by mobile services, demonstrating that the proposed CloudLSTM achieves state-of-the-art performance with measurement datasets collected in operational metropolitan-scale mobile network deployments.
Multi-Service Mobile Traffic Forecasting via Convolutional Long Short-Term Memories
May 23, 2019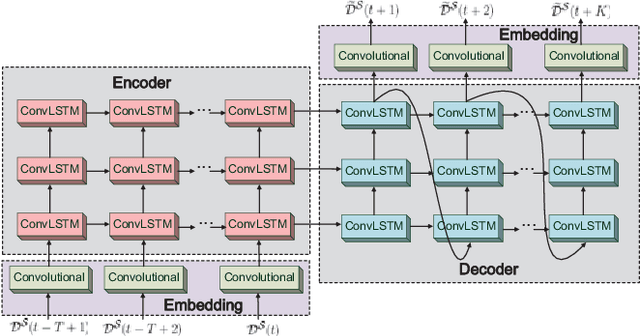
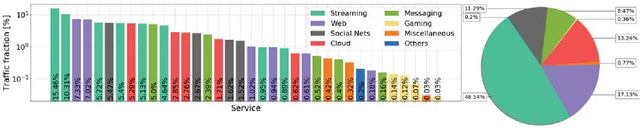
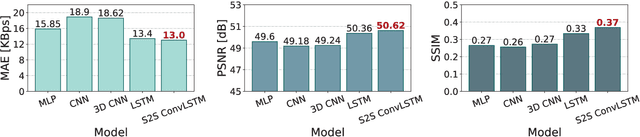
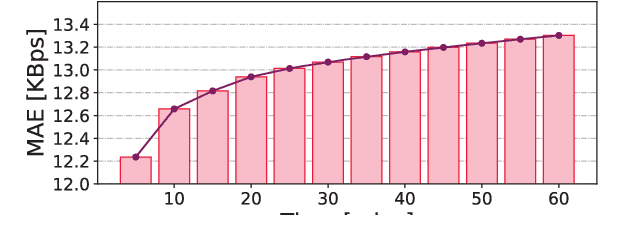
Network slicing is increasingly used to partition network infrastructure between different mobile services. Precise service-wise mobile traffic forecasting becomes essential in this context, as mobile operators seek to pre-allocate resources to each slice in advance, to meet the distinct requirements of individual services. This paper attacks the problem of multi-service mobile traffic forecasting using a sequence-to-sequence (S2S) learning paradigm and convolutional long short-term memories (ConvLSTMs). The proposed architecture is designed so as to effectively extract complex spatiotemporal features of mobile network traffic and predict with high accuracy the future demands for individual services at city scale. We conduct experiments on a mobile traffic dataset collected in a large European metropolis, demonstrating that the proposed S2S-ConvLSTM can forecast the mobile traffic volume produced by tens of different services in advance of up to one hour, by just using measurements taken during the past hour. In particular, our solution achieves mean absolute errors (MAE) at antenna level that are below 13KBps, outperforming other deep learning approaches by up to 31.2%.
Driver Behavior Recognition via Interwoven Deep Convolutional Neural Nets with Multi-stream Inputs
Nov 22, 2018
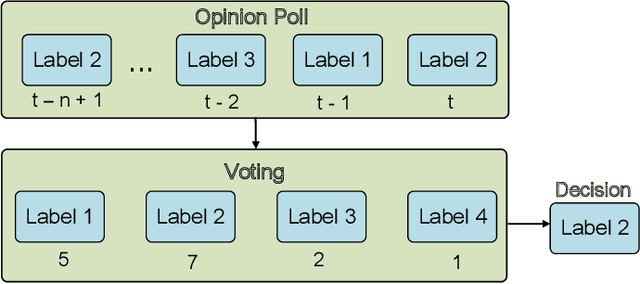
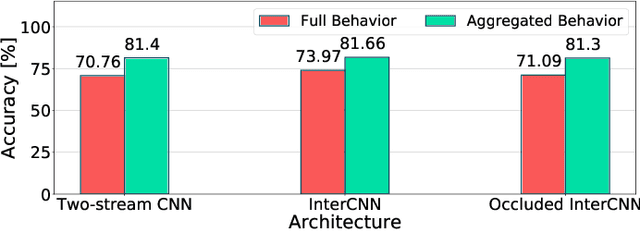
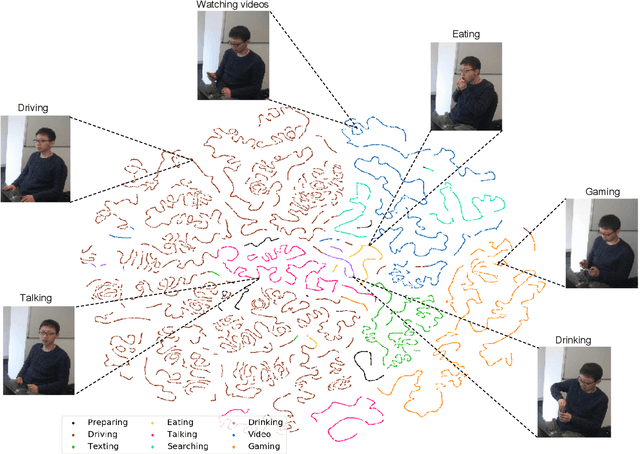
Recognizing driver behaviors is becoming vital for in-vehicle systems that seek to reduce the incidence of car accidents rooted in cognitive distraction. In this paper, we harness the exceptional feature extraction abilities of deep learning and propose a dedicated Interwoven Deep Convolutional Neural Network (InterCNN) architecture to tackle the accurate classification of driver behaviors in real-time. The proposed solution exploits information from multi-stream inputs, i.e., in-vehicle cameras with different fields of view and optical flows computed based on recorded images, and merges through multiple fusion layers abstract features that it extracts. This builds a tight ensembling system, which significantly improves the robustness of the model. We further introduce a temporal voting scheme based on historical inference instances, in order to enhance accuracy. Experiments conducted with a real world dataset that we collect in a mock-up car environment demonstrate that the proposed InterCNN with MobileNet convolutional blocks can classify 9 different behaviors with 73.97% accuracy, and 5 aggregated behaviors with 81.66% accuracy. Our architecture is highly computationally efficient, as it performs inferences within 15ms, which satisfies the real-time constraints of intelligent cars. In addition, our InterCNN is robust to lossy input, as the classification remains accurate when two input streams are occluded.
Deep Learning in Mobile and Wireless Networking: A Survey
Sep 17, 2018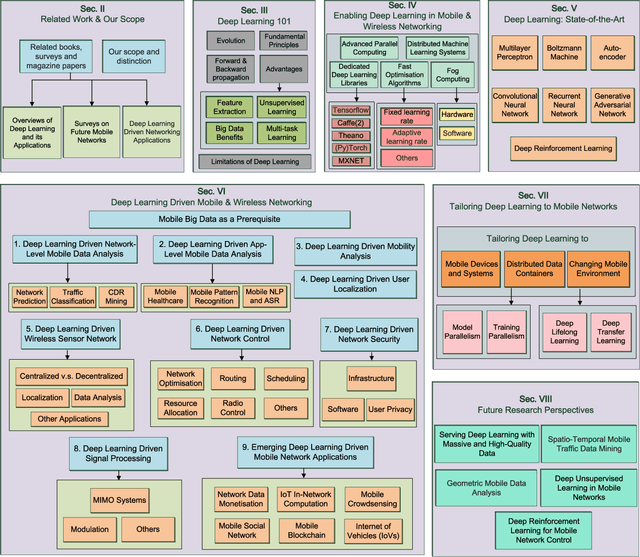
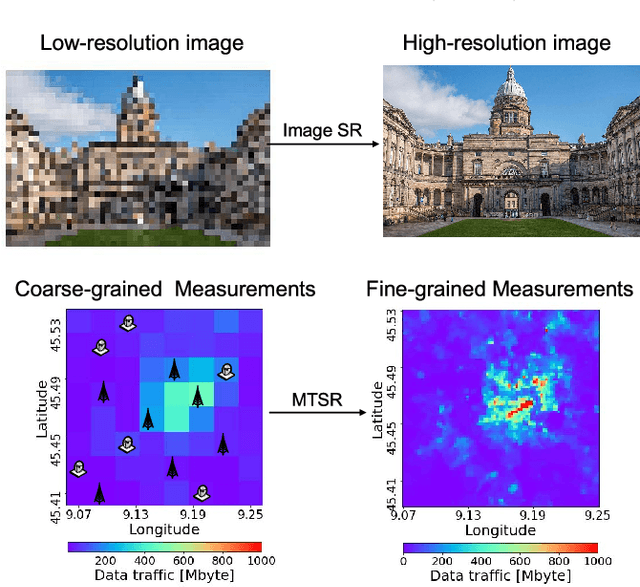
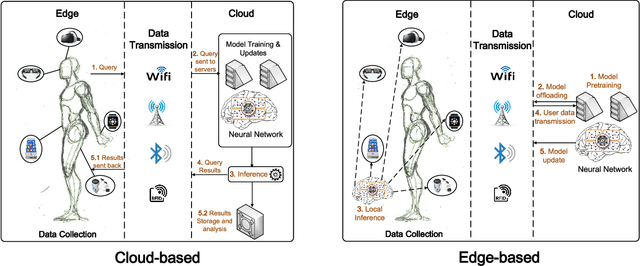
The rapid uptake of mobile devices and the rising popularity of mobile applications and services pose unprecedented demands on mobile and wireless networking infrastructure. Upcoming 5G systems are evolving to support exploding mobile traffic volumes, agile management of network resource to maximize user experience, and extraction of fine-grained real-time analytics. Fulfilling these tasks is challenging, as mobile environments are increasingly complex, heterogeneous, and evolving. One potential solution is to resort to advanced machine learning techniques to help managing the rise in data volumes and algorithm-driven applications. The recent success of deep learning underpins new and powerful tools that tackle problems in this space. In this paper we bridge the gap between deep learning and mobile and wireless networking research, by presenting a comprehensive survey of the crossovers between the two areas. We first briefly introduce essential background and state-of-the-art in deep learning techniques with potential applications to networking. We then discuss several techniques and platforms that facilitate the efficient deployment of deep learning onto mobile systems. Subsequently, we provide an encyclopedic review of mobile and wireless networking research based on deep learning, which we categorize by different domains. Drawing from our experience, we discuss how to tailor deep learning to mobile environments. We complete this survey by pinpointing current challenges and open future directions for research.
ZipNet-GAN: Inferring Fine-grained Mobile Traffic Patterns via a Generative Adversarial Neural Network
Nov 07, 2017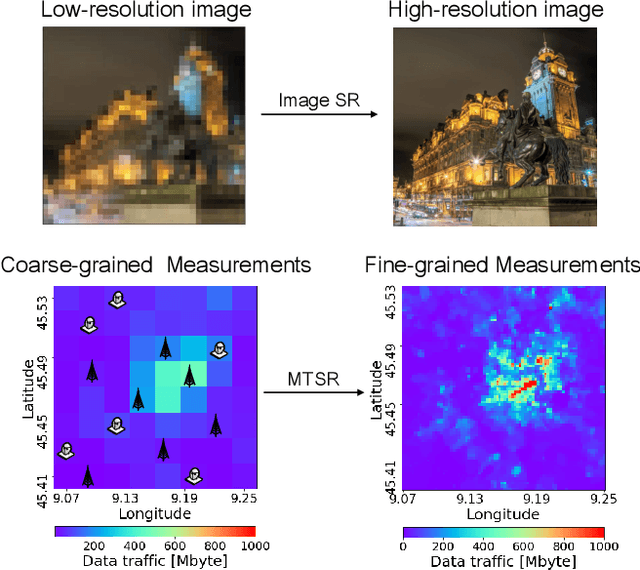

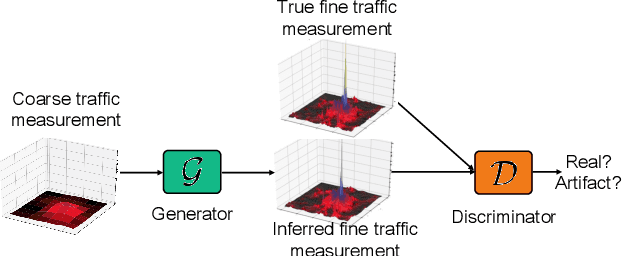

Large-scale mobile traffic analytics is becoming essential to digital infrastructure provisioning, public transportation, events planning, and other domains. Monitoring city-wide mobile traffic is however a complex and costly process that relies on dedicated probes. Some of these probes have limited precision or coverage, others gather tens of gigabytes of logs daily, which independently offer limited insights. Extracting fine-grained patterns involves expensive spatial aggregation of measurements, storage, and post-processing. In this paper, we propose a mobile traffic super-resolution technique that overcomes these problems by inferring narrowly localised traffic consumption from coarse measurements. We draw inspiration from image processing and design a deep-learning architecture tailored to mobile networking, which combines Zipper Network (ZipNet) and Generative Adversarial neural Network (GAN) models. This enables to uniquely capture spatio-temporal relations between traffic volume snapshots routinely monitored over broad coverage areas (`low-resolution') and the corresponding consumption at 0.05 km $^2$ level (`high-resolution') usually obtained after intensive computation. Experiments we conduct with a real-world data set demonstrate that the proposed ZipNet(-GAN) infers traffic consumption with remarkable accuracy and up to 100$\times$ higher granularity as compared to standard probing, while outperforming existing data interpolation techniques. To our knowledge, this is the first time super-resolution concepts are applied to large-scale mobile traffic analysis and our solution is the first to infer fine-grained urban traffic patterns from coarse aggregates.