 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-Edge: Tensor-Train-Assisted LoRA for Practical CNN Fine-Tuning on Edge Devices
Nov 07, 2025



On-device fine-tuning of CNNs is essential to withstand domain shift in edge applications such as Human Activity Recognition (HAR), yet full fine-tuning is infeasible under strict memory, compute, and energy budgets. We present LoRA-Edge, a parameter-efficient fine-tuning (PEFT) method that builds on Low-Rank Adaptation (LoRA) with tensor-train assistance. LoRA-Edge (i) applies Tensor-Train Singular Value Decomposition (TT-SVD) to pre-trained convolutional layers, (ii) selectively updates only the output-side core with zero-initialization to keep the auxiliary path inactive at the start, and (iii) fuses the update back into dense kernels, leaving inference cost unchanged. This design preserves convolutional structure and reduces the number of trainable parameters by up to two orders of magnitude compared to full fine-tuning. Across diverse HAR datasets and CNN backbones, LoRA-Edge achieves accuracy within 4.7% of full fine-tuning while updating at most 1.49% of parameters, consistently outperforming prior parameter-efficient baselines under similar budgets. On a Jetson Orin Nano, TT-SVD initialization and selective-core training yield 1.4-3.8x faster convergence to target F1. LoRA-Edge thus makes structure-aligned, parameter-efficient on-device CNN adaptation practical for edge platforms.
Posterior Contraction for Sparse Neural Networks in Besov Spaces with Intrinsic Dimensionality
Jun 23, 2025This work establishes that sparse Bayesian neural networks achieve optimal posterior contraction rates over anisotropic Besov spaces and their hierarchical compositions. These structures reflect the intrinsic dimensionality of the underlying function, thereby mitigating the curse of dimensionality. Our analysis shows that Bayesian neural networks equipped with either sparse or continuous shrinkage priors attain the optimal rates which are dependent on the intrinsic dimension of the true structures. Moreover, we show that these priors enable rate adaptation, allowing the posterior to contract at the optimal rate even when the smoothness level of the true function is unknown. The proposed framework accommodates a broad class of functions, including additive and multiplicative Besov functions as special cases. These results advance the theoretical foundations of Bayesian neural networks and provide rigorous justification for their practical effectiveness in high-dimensional, structured estimation problems.
HH-PIM: Dynamic Optimization of Power and Performance with Heterogeneous-Hybrid PIM for Edge AI Devices
Apr 02, 2025



Processing-in-Memory (PIM) architectures offer promising solutions for efficiently handling AI applications in energy-constrained edge environments. While traditional PIM designs enhance performance and energy efficiency by reducing data movement between memory and processing units, they are limited in edge devices due to continuous power demands and the storage requirements of large neural network weights in SRAM and DRAM. Hybrid PIM architectures, incorporating non-volatile memories like MRAM and ReRAM, mitigate these limitations but struggle with a mismatch between fixed computing resources and dynamically changing inference workloads. To address these challenges, this study introduces a Heterogeneous-Hybrid PIM (HH-PIM) architecture, comprising high-performance MRAM-SRAM PIM modules and low-power MRAM-SRAM PIM modules. We further propose a data placement optimization algorithm that dynamically allocates data based on computational demand, maximizing energy efficiency. FPGA prototyping and power simulations with processors featuring HH-PIM and other PIM types demonstrate that the proposed HH-PIM achieves up to $60.43$ percent average energy savings over conventional PIMs while meeting application latency requirements. These results confirm the suitability of HH-PIM for adaptive, energy-efficient AI processing in edge devices.
Asymptotic Properties for Bayesian Neural Network in Besov Space
Jun 01, 2022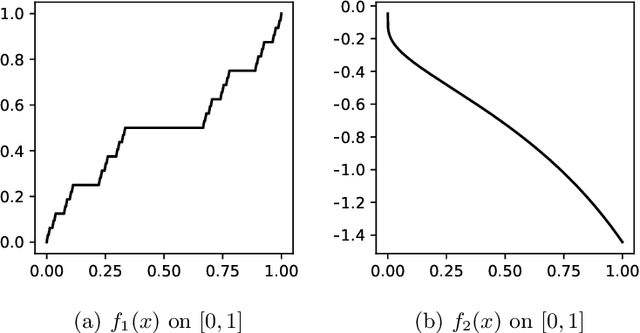


Neural networks have shown great predictive power when dealing with various unstructured data such as images and natural languages. The Bayesian neural network captures the uncertainty of prediction by putting a prior distribution for the parameter of the model and computing the posterior distribution. In this paper, we show that the Bayesian neural network using spike-and-slab prior has consistency with nearly minimax convergence rate when the true regression function is in the Besov space. Even when the smoothness of the regression function is unknown the same posterior convergence rate holds and thus the spike and slab prior is adaptive to the smoothness of the regression function. We also consider the shrinkage prior and show that it has the same convergence rate. In other words, we propose a practical Bayesian neural network with guaranteed asymptotic properties.