 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Large Language Models on Cross-Cultural Values in Connection with Training Methodology
Paper and Code
Dec 12, 2024

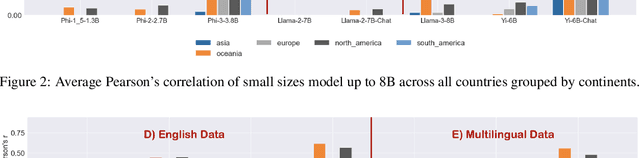

Large language models (LLMs) closely interact with humans, and thus need an intimate understanding of the cultural values of human society. In this paper, we explore how open-source LLMs make judgments on diverse categories of cultural values across countries, and its relation to training methodology such as model sizes, training corpus, alignment, etc. Our analysis shows that LLMs can judge socio-cultural norms similar to humans but less so on social systems and progress. In addition, LLMs tend to judge cultural values biased toward Western culture, which can be improved with training on the multilingual corpus. We also find that increasing model size helps a better understanding of social values, but smaller models can be enhanced by using synthetic data. Our analysis reveals valuable insights into the design methodology of LLMs in connection with their understanding of cultural values.