 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKanana: Compute-efficient Bilingual Language Models
Feb 26, 2025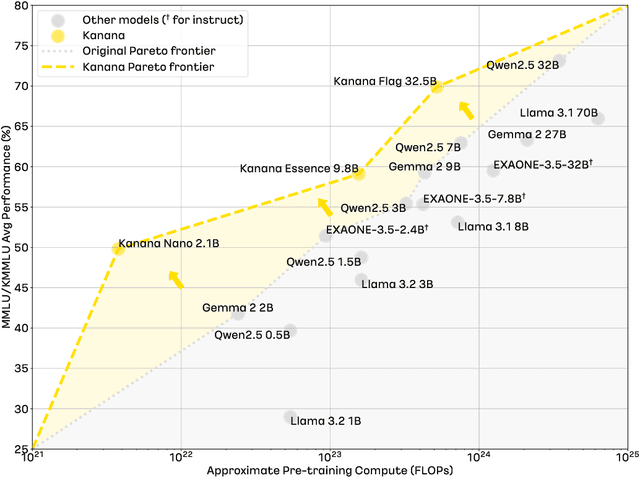



We introduce Kanana, a series of bilingual language models that demonstrate exceeding performance in Korean and competitive performance in English. The computational cost of Kanana is significantly lower than that of state-of-the-art models of similar size. The report details the techniques employed during pre-training to achieve compute-efficient yet competitive models, including high quality data filtering, staged pre-training, depth up-scaling, and pruning and distillation. Furthermore, the report outlines the methodologies utilized during the post-training of the Kanana models, encompassing supervised fine-tuning and preference optimization, aimed at enhancing their capability for seamless interaction with users. Lastly, the report elaborates on plausible approaches used for language model adaptation to specific scenarios, such as embedding, retrieval augmented generation, and function calling. The Kanana model series spans from 2.1B to 32.5B parameters with 2.1B models (base, instruct, embedding) publicly released to promote research on Korean language models.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Sample-based Regularization: A Transfer Learning Strategy Toward Better Generalization
Jul 10, 2020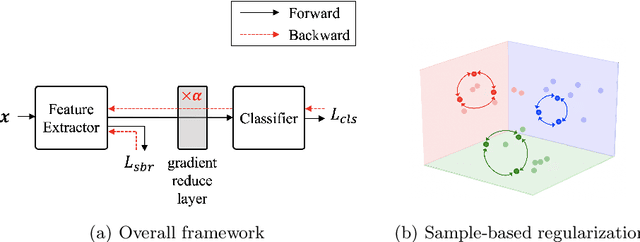
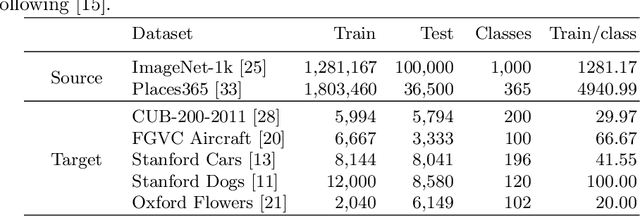
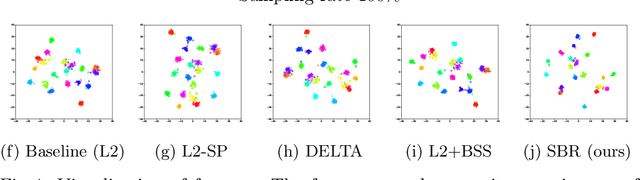
Training a deep neural network with a small amount of data is a challenging problem as it is vulnerable to overfitting. However, one of the practical difficulties that we often face is to collect many samples. Transfer learning is a cost-effective solution to this problem. By using the source model trained with a large-scale dataset, the target model can alleviate the overfitting originated from the lack of training data. Resorting to the ability of generalization of the source model, several methods proposed to use the source knowledge during the whole training procedure. However, this is likely to restrict the potential of the target model and some transferred knowledge from the source can interfere with the training procedure. For improving the generalization performance of the target model with a few training samples, we proposed a regularization method called sample-based regularization (SBR), which does not rely on the source's knowledge during training. With SBR, we suggested a new training framework for transfer learning. Experimental results showed that our framework outperformed existing methods in various configurations.