 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIWP: Token Pruning as Implicit Weight Pruning in Large Vision Language Models
Apr 01, 2026Large Vision Language Models show impressive performance across image and video understanding tasks, yet their computational cost grows rapidly with the number of visual tokens. Existing token pruning methods mitigate this issue through empirical approaches while overlooking the internal mechanism of attention. In this paper, we propose a novel training free token pruning framework grounded in the dual form perspective of attention. We reformulate attention as an implicit linear layer whose weight matrix is the sum of rank 1 outer products, each generated by a single token's key value pair. Token pruning thus reduces to selecting an optimal subset of these rank 1 updates that best approximates the original dual weight matrix. Extending this perspective to standard softmax attention in LVLMs, we derive a novel metric quantifying both a token's information magnitude and information duplication. To efficiently select the subset with the proposed metric, we introduce Progressive Chunked Maximal Marginal Relevance. Extensive experiments demonstrate that our method achieves a better trade off between performance and efficiency, while providing another perspective on existing pruning approaches.
B4DL: A Benchmark for 4D LiDAR LLM in Spatio-Temporal Understanding
Aug 07, 2025Understanding dynamic outdoor environments requires capturing complex object interactions and their evolution over time. LiDAR-based 4D point clouds provide precise spatial geometry and rich temporal cues, making them ideal for representing real-world scenes. However, despite their potential, 4D LiDAR remains underexplored in the context of Multimodal Large Language Models (MLLMs) due to the absence of high-quality, modality-specific annotations and the lack of MLLM architectures capable of processing its high-dimensional composition. To address these challenges, we introduce B4DL, a new benchmark specifically designed for training and evaluating MLLMs on 4D LiDAR understanding. In addition, we propose a scalable data generation pipeline and an MLLM model that, for the first time, directly processes raw 4D LiDAR by bridging it with language understanding. Combined with our dataset and benchmark, our model offers a unified solution for spatio-temporal reasoning in dynamic outdoor environments. We provide rendered 4D LiDAR videos, generated dataset, and inference outputs on diverse scenarios at: https://mmb4dl.github.io/mmb4dl/
DAM: Domain-Aware Module for Multi-Domain Dataset Condensation
May 28, 2025Dataset Condensation (DC) has emerged as a promising solution to mitigate the computational and storage burdens associated with training deep learning models. However, existing DC methods largely overlook the multi-domain nature of modern datasets, which are increasingly composed of heterogeneous images spanning multiple domains. In this paper, we extend DC and introduce Multi-Domain Dataset Condensation (MDDC), which aims to condense data that generalizes across both single-domain and multi-domain settings. To this end, we propose the Domain-Aware Module (DAM), a training-time module that embeds domain-related features into each synthetic image via learnable spatial masks. As explicit domain labels are mostly unavailable in real-world datasets, we employ frequency-based pseudo-domain labeling, which leverages low-frequency amplitude statistics. DAM is only active during the condensation process, thus preserving the same images per class (IPC) with prior methods. Experiments show that DAM consistently improves in-domain, out-of-domain, and cross-architecture performance over baseline dataset condensation methods.
Self-supervised Transformation Learning for Equivariant Representations
Jan 15, 2025



Unsupervised representation learning has significantly advanced various machine learning tasks. In the computer vision domain, state-of-the-art approaches utilize transformations like random crop and color jitter to achieve invariant representations, embedding semantically the same inputs despite transformations. However, this can degrade performance in tasks requiring precise features, such as localization or flower classification. To address this, recent research incorporates equivariant representation learning, which captures transformation-sensitive information. However, current methods depend on transformation labels and thus struggle with interdependency and complex transformations. We propose Self-supervised Transformation Learning (STL), replacing transformation labels with transformation representations derived from image pairs. The proposed method ensures transformation representation is image-invariant and learns corresponding equivariant transformations, enhancing performance without increased batch complexity. We demonstrate the approach's effectiveness across diverse classification and detection tasks, outperforming existing methods in 7 out of 11 benchmarks and excelling in detection. By integrating complex transformations like AugMix, unusable by prior equivariant methods, this approach enhances performance across tasks, underscoring its adaptability and resilience. Additionally, its compatibility with various base models highlights its flexibility and broad applicability. The code is available at https://github.com/jaemyung-u/stl.
AH-OCDA: Amplitude-based Curriculum Learning and Hopfield Segmentation Model for Open Compound Domain Adaptation
Dec 03, 2024

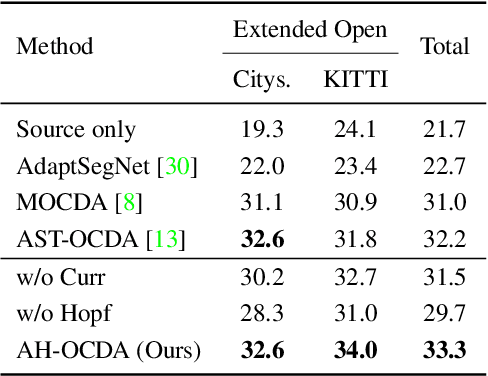

Open compound domain adaptation (OCDA) is a practical domain adaptation problem that consists of a source domain, target compound domain, and unseen open domain. In this problem, the absence of domain labels and pixel-level segmentation labels for both compound and open domains poses challenges to the direct application of existing domain adaptation and generalization methods. To address this issue, we propose Amplitude-based curriculum learning and a Hopfield segmentation model for Open Compound Domain Adaptation (AH-OCDA). Our method comprises two complementary components: 1) amplitude-based curriculum learning and 2) Hopfield segmentation model. Without prior knowledge of target domains within the compound domains, amplitude-based curriculum learning gradually induces the semantic segmentation model to adapt from the near-source compound domain to the far-source compound domain by ranking unlabeled compound domain images through Fast Fourier Transform (FFT). Additionally, the Hopfield segmentation model maps segmentation feature distributions from arbitrary domains to the feature distributions of the source domain. AH-OCDA achieves state-of-the-art performance on two OCDA benchmarks and extended open domains, demonstrating its adaptability to continuously changing compound domains and unseen open domains.
Unlocking the Capabilities of Masked Generative Models for Image Synthesis via Self-Guidance
Oct 17, 2024



Masked generative models (MGMs) have shown impressive generative ability while providing an order of magnitude efficient sampling steps compared to continuous diffusion models. However, MGMs still underperform in image synthesis compared to recent well-developed continuous diffusion models with similar size in terms of quality and diversity of generated samples. A key factor in the performance of continuous diffusion models stems from the guidance methods, which enhance the sample quality at the expense of diversity. In this paper, we extend these guidance methods to generalized guidance formulation for MGMs and propose a self-guidance sampling method, which leads to better generation quality. The proposed approach leverages an auxiliary task for semantic smoothing in vector-quantized token space, analogous to the Gaussian blur in continuous pixel space. Equipped with the parameter-efficient fine-tuning method and high-temperature sampling, MGMs with the proposed self-guidance achieve a superior quality-diversity trade-off, outperforming existing sampling methods in MGMs with more efficient training and sampling costs. Extensive experiments with the various sampling hyperparameters confirm the effectiveness of the proposed self-guidance.
Expanding Expressiveness of Diffusion Models with Limited Data via Self-Distillation based Fine-Tuning
Nov 02, 2023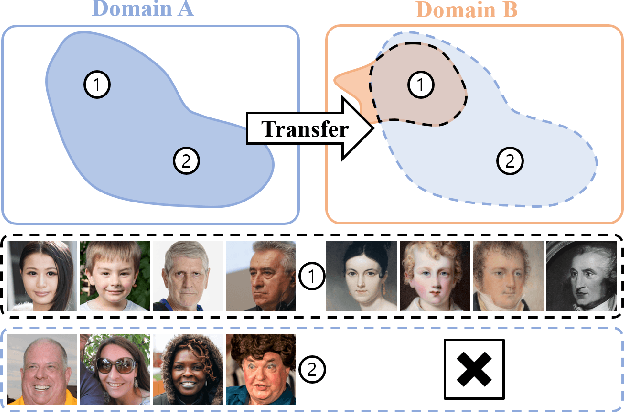
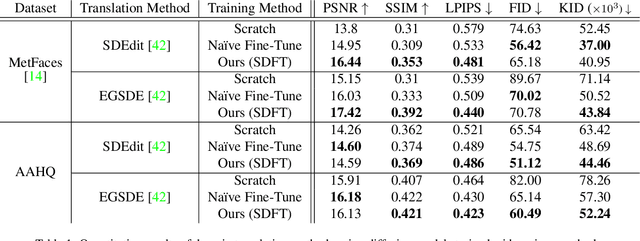

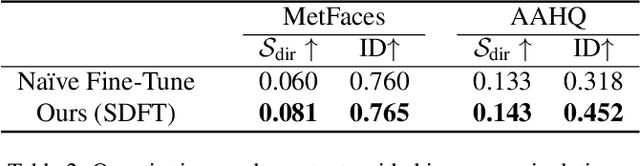
Training diffusion models on limited datasets poses challenges in terms of limited generation capacity and expressiveness, leading to unsatisfactory results in various downstream tasks utilizing pretrained diffusion models, such as domain translation and text-guided image manipulation. In this paper, we propose Self-Distillation for Fine-Tuning diffusion models (SDFT), a methodology to address these challenges by leveraging diverse features from diffusion models pretrained on large source datasets. SDFT distills more general features (shape, colors, etc.) and less domain-specific features (texture, fine details, etc) from the source model, allowing successful knowledge transfer without disturbing the training process on target datasets. The proposed method is not constrained by the specific architecture of the model and thus can be generally adopted to existing frameworks. Experimental results demonstrate that SDFT enhances the expressiveness of the diffusion model with limited datasets, resulting in improved generation capabilities across various downstream tasks.
SimCol3D -- 3D Reconstruction during Colonoscopy Challenge
Jul 20, 2023Colorectal cancer is one of the most common cancers in the world. While colonoscopy is an effective screening technique, navigating an endoscope through the colon to detect polyps is challenging. A 3D map of the observed surfaces could enhance the identification of unscreened colon tissue and serve as a training platform. However, reconstructing the colon from video footage remains unsolved due to numerous factors such as self-occlusion, reflective surfaces, lack of texture, and tissue deformation that limit feature-based methods. Learning-based approaches hold promise as robust alternatives, but necessitate extensive datasets. By establishing a benchmark, the 2022 EndoVis sub-challenge SimCol3D aimed to facilitate data-driven depth and pose prediction during colonoscopy. The challenge was hosted as part of MICCAI 2022 in Singapore. Six teams from around the world and representatives from academia and industry participated in the three sub-challenges: synthetic depth prediction, synthetic pose prediction, and real pose prediction. This paper describes the challenge, the submitted methods, and their results. We show that depth prediction in virtual colonoscopy is robustly solvable, while pose estimation remains an open research question.
Deep Cross-Modal Steganography Using Neural Representations
Jul 18, 2023Steganography is the process of embedding secret data into another message or data, in such a way that it is not easily noticeable. With the advancement of deep learning, Deep Neural Networks (DNNs) have recently been utilized in steganography. However, existing deep steganography techniques are limited in scope, as they focus on specific data types and are not effective for cross-modal steganography. Therefore, We propose a deep cross-modal steganography framework using Implicit Neural Representations (INRs) to hide secret data of various formats in cover images. The proposed framework employs INRs to represent the secret data, which can handle data of various modalities and resolutions. Experiments on various secret datasets of diverse types demonstrate that the proposed approach is expandable and capable of accommodating different modalities.
Lightweight Monocular Depth Estimation via Token-Sharing Transformer
Jun 09, 2023Depth estimation is an important task in various robotics systems and applications. In mobile robotics systems, monocular depth estimation is desirable since a single RGB camera can be deployable at a low cost and compact size. Due to its significant and growing needs, many lightweight monocular depth estimation networks have been proposed for mobile robotics systems. While most lightweight monocular depth estimation methods have been developed using convolution neural networks, the Transformer has been gradually utilized in monocular depth estimation recently. However, massive parameters and large computational costs in the Transformer disturb the deployment to embedded devices. In this paper, we present a Token-Sharing Transformer (TST), an architecture using the Transformer for monocular depth estimation, optimized especially in embedded devices. The proposed TST utilizes global token sharing, which enables the model to obtain an accurate depth prediction with high throughput in embedded devices. Experimental results show that TST outperforms the existing lightweight monocular depth estimation methods. On the NYU Depth v2 dataset, TST can deliver depth maps up to 63.4 FPS in NVIDIA Jetson nano and 142.6 FPS in NVIDIA Jetson TX2, with lower errors than the existing methods. Furthermore, TST achieves real-time depth estimation of high-resolution images on Jetson TX2 with competitive results.