 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Feature Whitening for Hyperparameter-Free Bias Mitigation
Jul 27, 2025


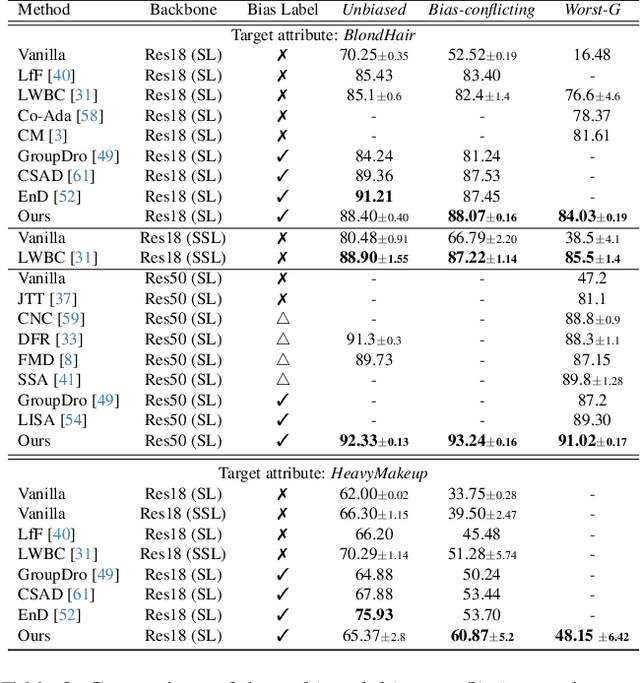
As the use of artificial intelligence rapidly increases, the development of trustworthy artificial intelligence has become important. However, recent studies have shown that deep neural networks are susceptible to learn spurious correlations present in datasets. To improve the reliability, we propose a simple yet effective framework called controllable feature whitening. We quantify the linear correlation between the target and bias features by the covariance matrix, and eliminate it through the whitening module. Our results systemically demonstrate that removing the linear correlations between features fed into the last linear classifier significantly mitigates the bias, while avoiding the need to model intractable higher-order dependencies. A particular advantage of the proposed method is that it does not require regularization terms or adversarial learning, which often leads to unstable optimization in practice. Furthermore, we show that two fairness criteria, demographic parity and equalized odds, can be effectively handled by whitening with the re-weighted covariance matrix. Consequently, our method controls the trade-off between the utility and fairness of algorithms by adjusting the weighting coefficient. Finally, we validate that our method outperforms existing approaches on four benchmark datasets: Corrupted CIFAR-10, Biased FFHQ, WaterBirds, and Celeb-A.
Self-supervised Transformation Learning for Equivariant Representations
Jan 15, 2025



Unsupervised representation learning has significantly advanced various machine learning tasks. In the computer vision domain, state-of-the-art approaches utilize transformations like random crop and color jitter to achieve invariant representations, embedding semantically the same inputs despite transformations. However, this can degrade performance in tasks requiring precise features, such as localization or flower classification. To address this, recent research incorporates equivariant representation learning, which captures transformation-sensitive information. However, current methods depend on transformation labels and thus struggle with interdependency and complex transformations. We propose Self-supervised Transformation Learning (STL), replacing transformation labels with transformation representations derived from image pairs. The proposed method ensures transformation representation is image-invariant and learns corresponding equivariant transformations, enhancing performance without increased batch complexity. We demonstrate the approach's effectiveness across diverse classification and detection tasks, outperforming existing methods in 7 out of 11 benchmarks and excelling in detection. By integrating complex transformations like AugMix, unusable by prior equivariant methods, this approach enhances performance across tasks, underscoring its adaptability and resilience. Additionally, its compatibility with various base models highlights its flexibility and broad applicability. The code is available at https://github.com/jaemyung-u/stl.
Foreseeing Reconstruction Quality of Gradient Inversion: An Optimization Perspective
Dec 19, 2023

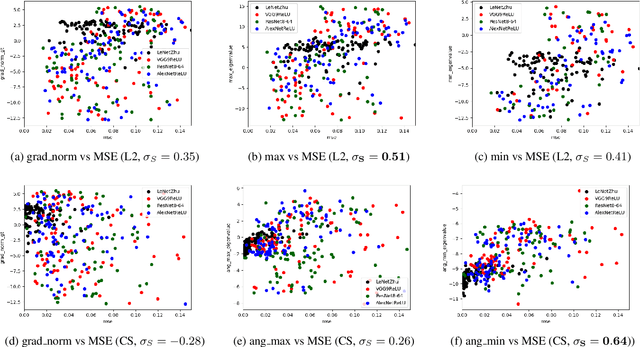
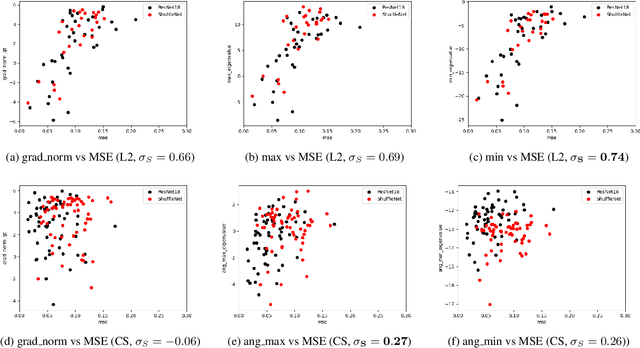
Gradient inversion attacks can leak data privacy when clients share weight updates with the server in federated learning (FL). Existing studies mainly use L2 or cosine distance as the loss function for gradient matching in the attack. Our empirical investigation shows that the vulnerability ranking varies with the loss function used. Gradient norm, which is commonly used as a vulnerability proxy for gradient inversion attack, cannot explain this as it remains constant regardless of the loss function for gradient matching. In this paper, we propose a loss-aware vulnerability proxy (LAVP) for the first time. LAVP refers to either the maximum or minimum eigenvalue of the Hessian with respect to gradient matching loss at ground truth. This suggestion is based on our theoretical findings regarding the local optimization of the gradient inversion in proximity to the ground truth, which corresponds to the worst case attack scenario. We demonstrate the effectiveness of LAVP on various architectures and datasets, showing its consistent superiority over the gradient norm in capturing sample vulnerabilities. The performance of each proxy is measured in terms of Spearman's rank correlation with respect to several similarity scores. This work will contribute to enhancing FL security against any potential loss functions beyond L2 or cosine distance in the future.