 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Feature Whitening for Hyperparameter-Free Bias Mitigation
Jul 27, 2025As the use of artificial intelligence rapidly increases, the development of trustworthy artificial intelligence has become important. However, recent studies have shown that deep neural networks are susceptible to learn spurious correlations present in datasets. To improve the reliability, we propose a simple yet effective framework called controllable feature whitening. We quantify the linear correlation between the target and bias features by the covariance matrix, and eliminate it through the whitening module. Our results systemically demonstrate that removing the linear correlations between features fed into the last linear classifier significantly mitigates the bias, while avoiding the need to model intractable higher-order dependencies. A particular advantage of the proposed method is that it does not require regularization terms or adversarial learning, which often leads to unstable optimization in practice. Furthermore, we show that two fairness criteria, demographic parity and equalized odds, can be effectively handled by whitening with the re-weighted covariance matrix. Consequently, our method controls the trade-off between the utility and fairness of algorithms by adjusting the weighting coefficient. Finally, we validate that our method outperforms existing approaches on four benchmark datasets: Corrupted CIFAR-10, Biased FFHQ, WaterBirds, and Celeb-A.
Foreseeing Reconstruction Quality of Gradient Inversion: An Optimization Perspective
Dec 19, 2023

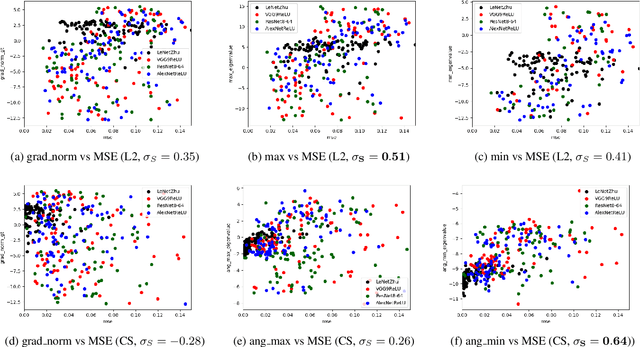
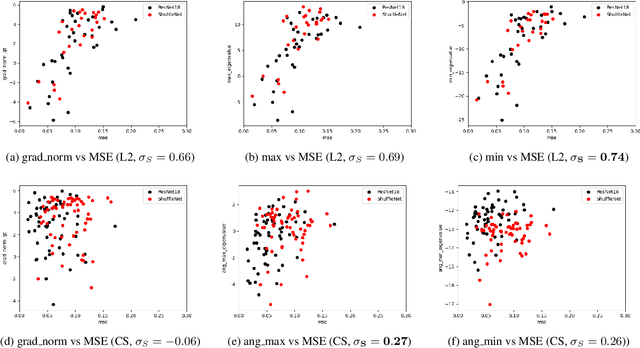
Gradient inversion attacks can leak data privacy when clients share weight updates with the server in federated learning (FL). Existing studies mainly use L2 or cosine distance as the loss function for gradient matching in the attack. Our empirical investigation shows that the vulnerability ranking varies with the loss function used. Gradient norm, which is commonly used as a vulnerability proxy for gradient inversion attack, cannot explain this as it remains constant regardless of the loss function for gradient matching. In this paper, we propose a loss-aware vulnerability proxy (LAVP) for the first time. LAVP refers to either the maximum or minimum eigenvalue of the Hessian with respect to gradient matching loss at ground truth. This suggestion is based on our theoretical findings regarding the local optimization of the gradient inversion in proximity to the ground truth, which corresponds to the worst case attack scenario. We demonstrate the effectiveness of LAVP on various architectures and datasets, showing its consistent superiority over the gradient norm in capturing sample vulnerabilities. The performance of each proxy is measured in terms of Spearman's rank correlation with respect to several similarity scores. This work will contribute to enhancing FL security against any potential loss functions beyond L2 or cosine distance in the future.
Implicit 3D Human Mesh Recovery using Consistency with Pose and Shape from Unseen-view
Jul 03, 2023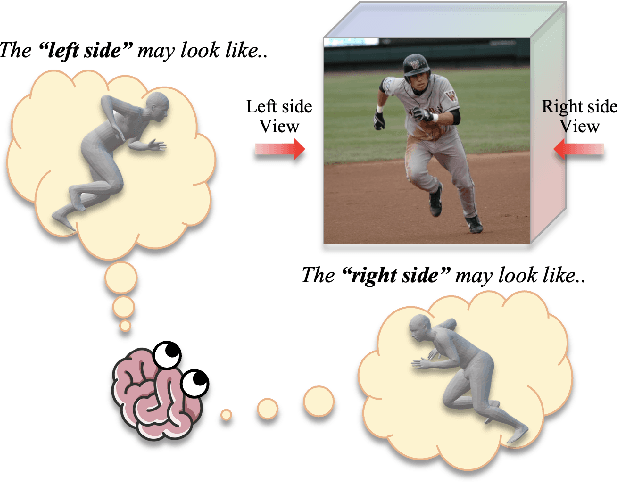
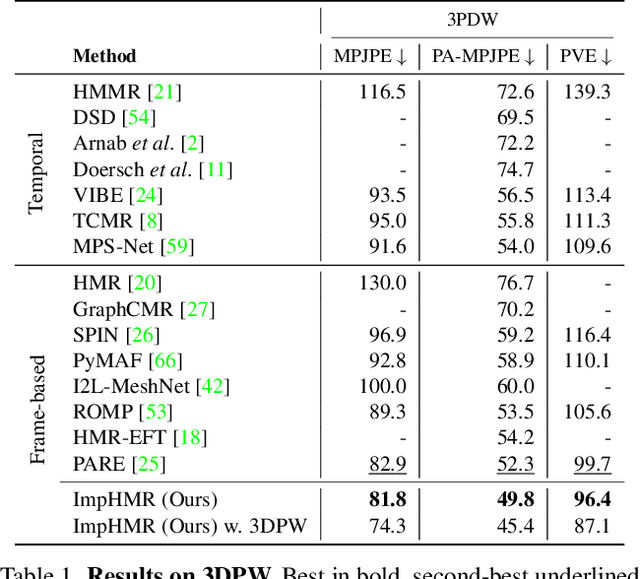
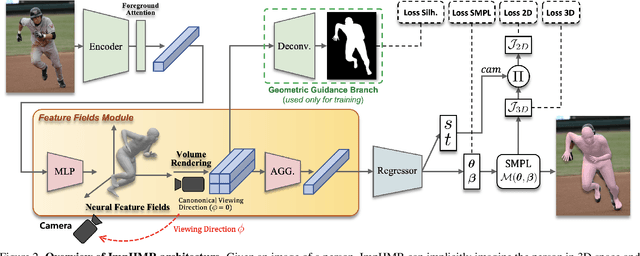

From an image of a person, we can easily infer the natural 3D pose and shape of the person even if ambiguity exists. This is because we have a mental model that allows us to imagine a person's appearance at different viewing directions from a given image and utilize the consistency between them for inference. However, existing human mesh recovery methods only consider the direction in which the image was taken due to their structural limitations. Hence, we propose "Implicit 3D Human Mesh Recovery (ImpHMR)" that can implicitly imagine a person in 3D space at the feature-level via Neural Feature Fields. In ImpHMR, feature fields are generated by CNN-based image encoder for a given image. Then, the 2D feature map is volume-rendered from the feature field for a given viewing direction, and the pose and shape parameters are regressed from the feature. To utilize consistency with pose and shape from unseen-view, if there are 3D labels, the model predicts results including the silhouette from an arbitrary direction and makes it equal to the rotated ground-truth. In the case of only 2D labels, we perform self-supervised learning through the constraint that the pose and shape parameters inferred from different directions should be the same. Extensive evaluations show the efficacy of the proposed method.
Localization using Multi-Focal Spatial Attention for Masked Face Recognition
May 03, 2023
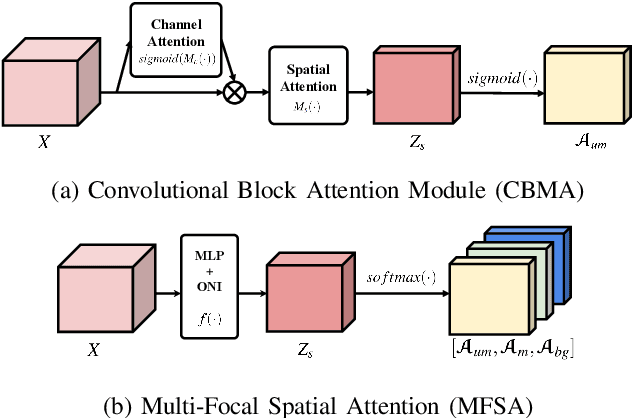
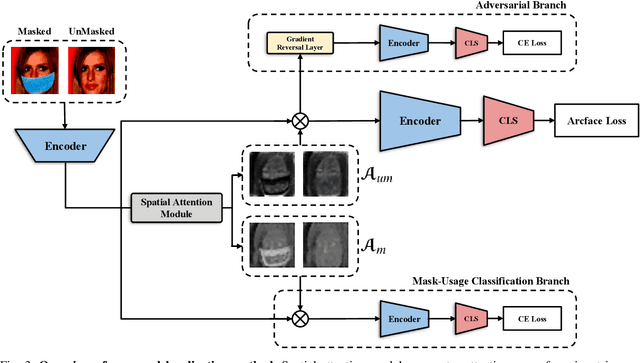
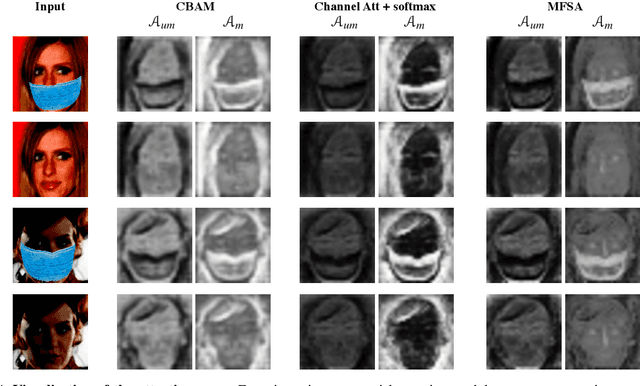
Since the beginning of world-wide COVID-19 pandemic, facial masks have been recommended to limit the spread of the disease. However, these masks hide certain facial attributes. Hence, it has become difficult for existing face recognition systems to perform identity verification on masked faces. In this context, it is necessary to develop masked Face Recognition (MFR) for contactless biometric recognition systems. Thus, in this paper, we propose Complementary Attention Learning and Multi-Focal Spatial Attention that precisely removes masked region by training complementary spatial attention to focus on two distinct regions: masked regions and backgrounds. In our method, standard spatial attention and networks focus on unmasked regions, and extract mask-invariant features while minimizing the loss of the conventional Face Recognition (FR) performance. For conventional FR, we evaluate the performance on the IJB-C, Age-DB, CALFW, and CPLFW datasets. We evaluate the MFR performance on the ICCV2021-MFR/Insightface track, and demonstrate the improved performance on the both MFR and FR datasets. Additionally, we empirically verify that spatial attention of proposed method is more precisely activated in unmasked regions.
Rethinking Efficacy of Softmax for Lightweight Non-Local Neural Networks
Jul 27, 2022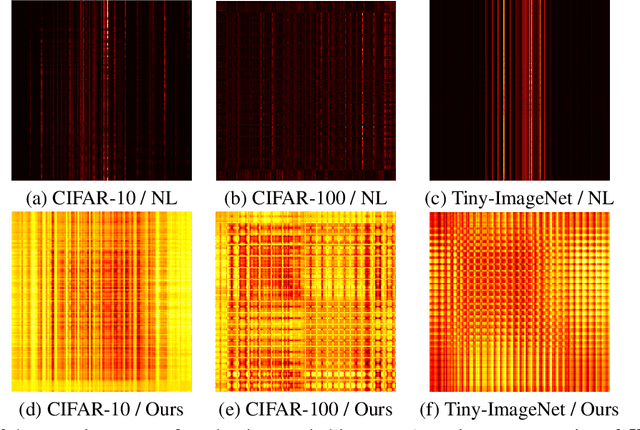
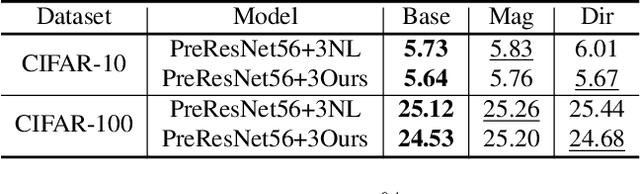
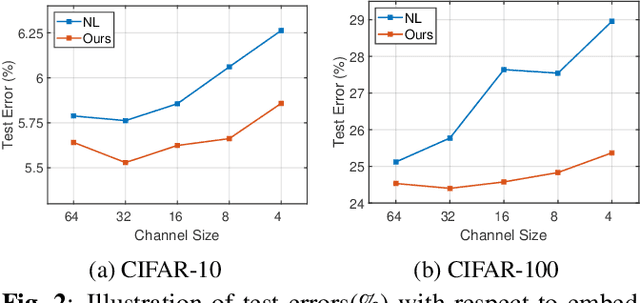
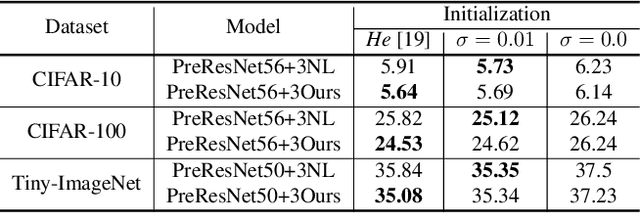
Non-local (NL) block is a popular module that demonstrates the capability to model global contexts. However, NL block generally has heavy computation and memory costs, so it is impractical to apply the block to high-resolution feature maps. In this paper, to investigate the efficacy of NL block, we empirically analyze if the magnitude and direction of input feature vectors properly affect the attention between vectors. The results show the inefficacy of softmax operation which is generally used to normalize the attention map of the NL block. Attention maps normalized with softmax operation highly rely upon magnitude of key vectors, and performance is degenerated if the magnitude information is removed. By replacing softmax operation with the scaling factor, we demonstrate improved performance on CIFAR-10, CIFAR-100, and Tiny-ImageNet. In Addition, our method shows robustness to embedding channel reduction and embedding weight initialization. Notably, our method makes multi-head attention employable without additional computational cost.
Camera Distortion-aware 3D Human Pose Estimation in Video with Optimization-based Meta-Learning
Dec 03, 2021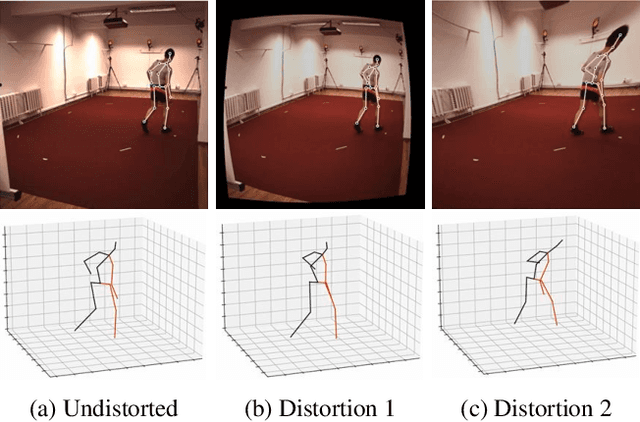

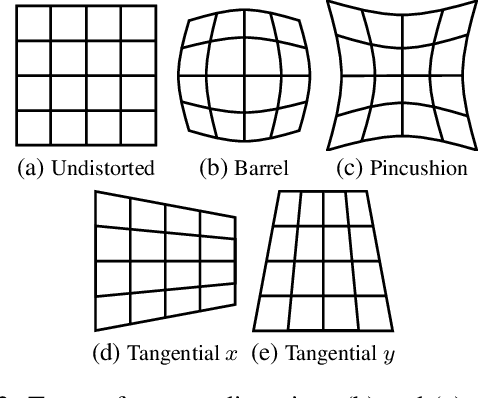
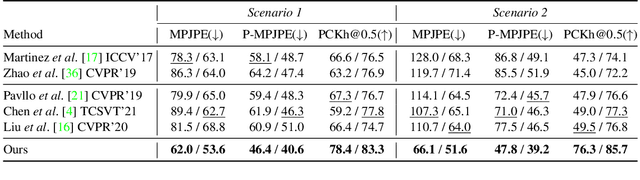
Existing 3D human pose estimation algorithms trained on distortion-free datasets suffer performance drop when applied to new scenarios with a specific camera distortion. In this paper, we propose a simple yet effective model for 3D human pose estimation in video that can quickly adapt to any distortion environment by utilizing MAML, a representative optimization-based meta-learning algorithm. We consider a sequence of 2D keypoints in a particular distortion as a single task of MAML. However, due to the absence of a large-scale dataset in a distorted environment, we propose an efficient method to generate synthetic distorted data from undistorted 2D keypoints. For the evaluation, we assume two practical testing situations depending on whether a motion capture sensor is available or not. In particular, we propose Inference Stage Optimization using bone-length symmetry and consistency. Extensive evaluation shows that our proposed method successfully adapts to various degrees of distortion in the testing phase and outperforms the existing state-of-the-art approaches. The proposed method is useful in practice because it does not require camera calibration and additional computations in a testing set-up.
Improving Generalization of Batch Whitening by Convolutional Unit Optimization
Aug 24, 2021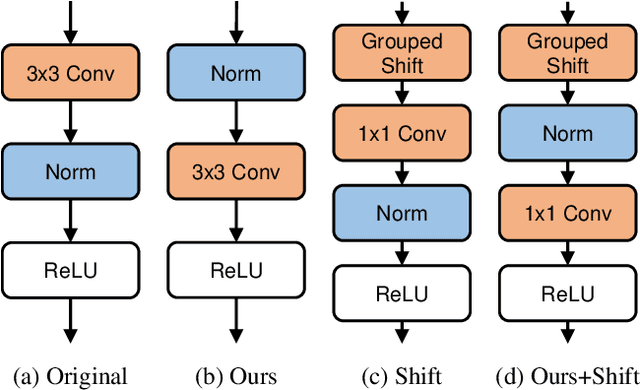
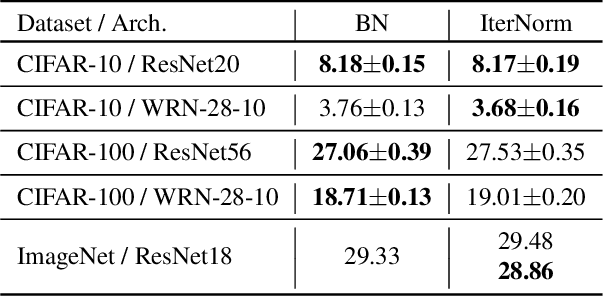
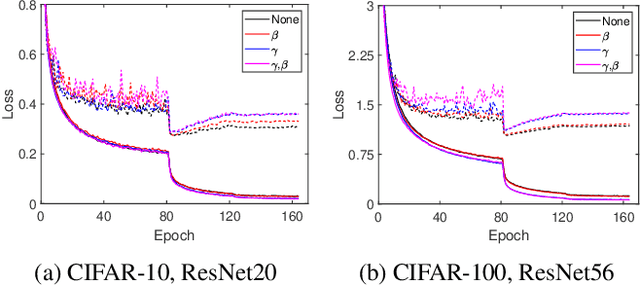
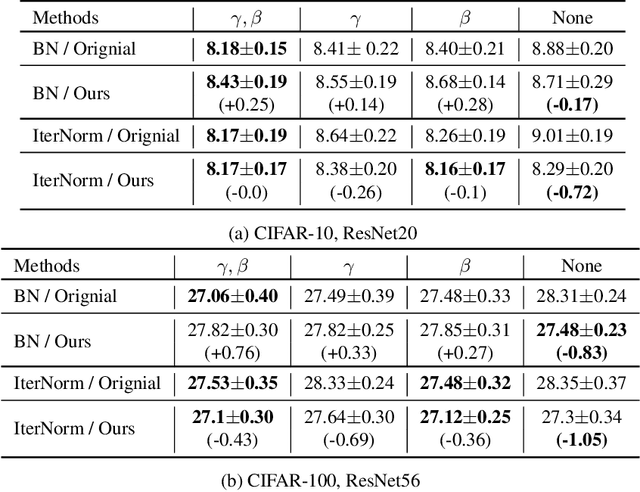
Batch Whitening is a technique that accelerates and stabilizes training by transforming input features to have a zero mean (Centering) and a unit variance (Scaling), and by removing linear correlation between channels (Decorrelation). In commonly used structures, which are empirically optimized with Batch Normalization, the normalization layer appears between convolution and activation function. Following Batch Whitening studies have employed the same structure without further analysis; even Batch Whitening was analyzed on the premise that the input of a linear layer is whitened. To bridge the gap, we propose a new Convolutional Unit that is in line with the theory, and our method generally improves the performance of Batch Whitening. Moreover, we show the inefficacy of the original Convolutional Unit by investigating rank and correlation of features. As our method is employable off-the-shelf whitening modules, we use Iterative Normalization (IterNorm), the state-of-the-art whitening module, and obtain significantly improved performance on five image classification datasets: CIFAR-10, CIFAR-100, CUB-200-2011, Stanford Dogs, and ImageNet. Notably, we verify that our method improves stability and performance of whitening when using large learning rate, group size, and iteration number.