 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDS-DETR: DETR with Masked Duplicate Suppressor
May 22, 2026The DEtection TRansformer (DETR) is a powerful end-to-end object detector, yet its one-to-one matching strategy suffers from slow convergence and low recall. A common approach to address this issue is to use one-to-many label assignment to provide more positive samples. However, existing methods that use one-to-many matching as an auxiliary objective lead to increased training costs, with their auxiliary decoders discarded during inference. To address this limitation, we propose MDS-DETR, which leverages both one-to-one and one-to-many supervision within a single decoder. Specifically, we introduce a Masked Duplicate Suppressor (MDS) that injects asymmetry into self-attention via confidence-based causal masking. MDS filters out the duplicates generated by the one-to-many supervised layer, enables explainable, duplicate-free predictions in a fully end-to-end framework. MDS-DETR outperforms existing one-to-many DETR variants such as MS-DETR, MR.DETR and Relation-DETR, without relying on any additional queries or auxiliary decoders. Under a 12-epoch training schedule on MS COCO with a ResNet-50 backbone, MDS-DETR achieves a +2.8 mAP improvement over Deformable-DETR with only a 5\% increase in training time, and outperforms the state-of-the-art MR.DETR by +0.3 mAP while being even 20\% faster in training. Our code and models are available at \href{https://github.com/dcholee/mds-detr}{https://github.com/DChoLee/MDS-DETR}.
FRED: Towards a Full Rotation-Equivariance in Aerial Image Object Detection
Dec 22, 2023Rotation-equivariance is an essential yet challenging property in oriented object detection. While general object detectors naturally leverage robustness to spatial shifts due to the translation-equivariance of the conventional CNNs, achieving rotation-equivariance remains an elusive goal. Current detectors deploy various alignment techniques to derive rotation-invariant features, but still rely on high capacity models and heavy data augmentation with all possible rotations. In this paper, we introduce a Fully Rotation-Equivariant Oriented Object Detector (FRED), whose entire process from the image to the bounding box prediction is strictly equivariant. Specifically, we decouple the invariant task (object classification) and the equivariant task (object localization) to achieve end-to-end equivariance. We represent the bounding box as a set of rotation-equivariant vectors to implement rotation-equivariant localization. Moreover, we utilized these rotation-equivariant vectors as offsets in the deformable convolution, thereby enhancing the existing advantages of spatial adaptation. Leveraging full rotation-equivariance, our FRED demonstrates higher robustness to image-level rotation compared to existing methods. Furthermore, we show that FRED is one step closer to non-axis aligned learning through our experiments. Compared to state-of-the-art methods, our proposed method delivers comparable performance on DOTA-v1.0 and outperforms by 1.5 mAP on DOTA-v1.5, all while significantly reducing the model parameters to 16%.
Projection-based Point Convolution for Efficient Point Cloud Segmentation
Feb 04, 2022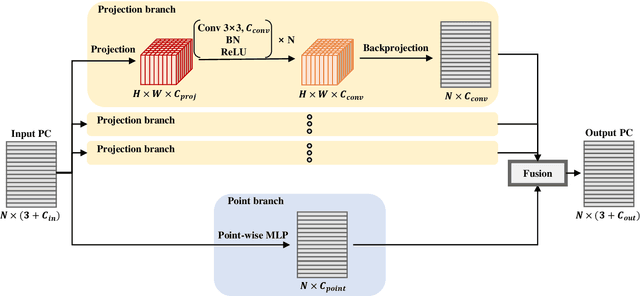
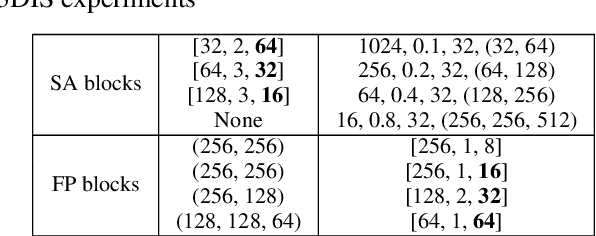
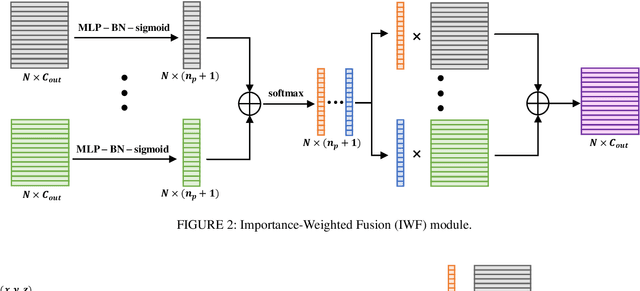
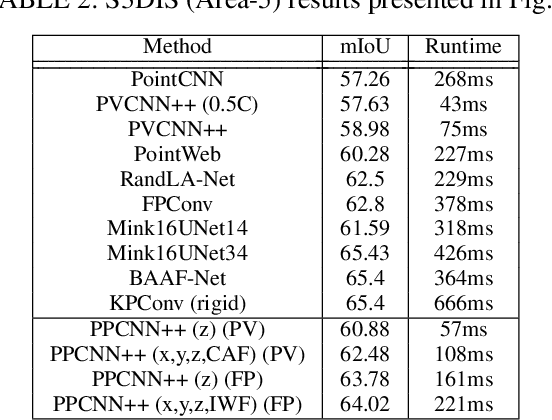
Understanding point cloud has recently gained huge interests following the development of 3D scanning devices and the accumulation of large-scale 3D data. Most point cloud processing algorithms can be classified as either point-based or voxel-based methods, both of which have severe limitations in processing time or memory, or both. To overcome these limitations, we propose Projection-based Point Convolution (PPConv), a point convolutional module that uses 2D convolutions and multi-layer perceptrons (MLPs) as its components. In PPConv, point features are processed through two branches: point branch and projection branch. Point branch consists of MLPs, while projection branch transforms point features into a 2D feature map and then apply 2D convolutions. As PPConv does not use point-based or voxel-based convolutions, it has advantages in fast point cloud processing. When combined with a learnable projection and effective feature fusion strategy, PPConv achieves superior efficiency compared to state-of-the-art methods, even with a simple architecture based on PointNet++. We demonstrate the efficiency of PPConv in terms of the trade-off between inference time and segmentation performance. The experimental results on S3DIS and ShapeNetPart show that PPConv is the most efficient method among the compared ones. The code is available at github.com/pahn04/PPConv.
PBP-Net: Point Projection and Back-Projection Network for 3D Point Cloud Segmentation
Nov 02, 2020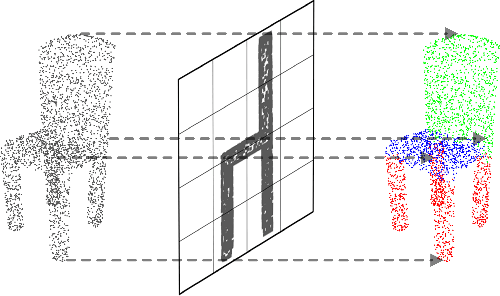
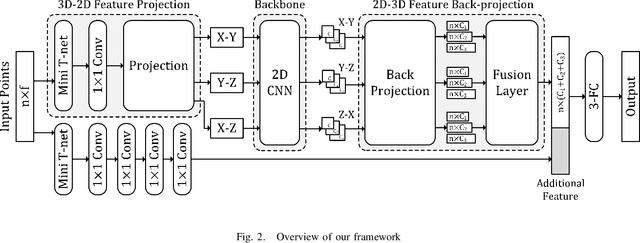
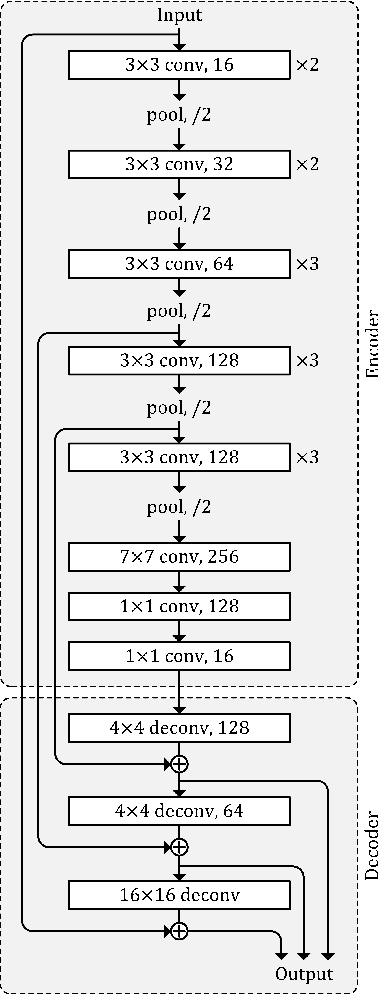

Following considerable development in 3D scanning technologies, many studies have recently been proposed with various approaches for 3D vision tasks, including some methods that utilize 2D convolutional neural networks (CNNs). However, even though 2D CNNs have achieved high performance in many 2D vision tasks, existing works have not effectively applied them onto 3D vision tasks. In particular, segmentation has not been well studied because of the difficulty of dense prediction for each point, which requires rich feature representation. In this paper, we propose a simple and efficient architecture named point projection and back-projection network (PBP-Net), which leverages 2D CNNs for the 3D point cloud segmentation. 3 modules are introduced, each of which projects 3D point cloud onto 2D planes, extracts features using a 2D CNN backbone, and back-projects features onto the original 3D point cloud. To demonstrate effective 3D feature extraction using 2D CNN, we perform various experiments including comparison to recent methods. We analyze the proposed modules through ablation studies and perform experiments on object part segmentation (ShapeNet-Part dataset) and indoor scene semantic segmentation (S3DIS dataset). The experimental results show that proposed PBP-Net achieves comparable performance to existing state-of-the-art methods.