 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Question-Aware Keyframe Selection with Synthetic Supervision for Video Question Answering
Mar 16, 2026Large multimodal models (LMMs) have recently demonstrated remarkable performance in video question answering (VideoQA), yet reasoning over video remains challenging due to high inference cost and diluted information. Keyframe selection offers efficiency and sharper reasoning but suffers from sparse supervision and redundant frame choices when relying only on image-text similarity. We present a question-aware keyframe selection framework with two components: pseudo keyframe labels derived from LMMs that provide informative supervision and a coverage regularization that promotes diverse, complementary evidence across time. Experiments on NExT-QA show that our method significantly improves accuracy, especially for temporal and causal question types, establishing keyframe selection as an effective and learnable module for VideoQA.
ConceptPrism: Concept Disentanglement in Personalized Diffusion Models via Residual Token Optimization
Feb 23, 2026Personalized text-to-image generation suffers from concept entanglement, where irrelevant residual information from reference images is captured, leading to a trade-off between concept fidelity and text alignment. Recent disentanglement approaches attempt to solve this utilizing manual guidance, such as linguistic cues or segmentation masks, which limits their applicability and fails to fully articulate the target concept. In this paper, we propose ConceptPrism, a novel framework that automatically disentangles the shared visual concept from image-specific residuals by comparing images within a set. Our method jointly optimizes a target token and image-wise residual tokens using two complementary objectives: a reconstruction loss to ensure fidelity, and a novel exclusion loss that compels residual tokens to discard the shared concept. This process allows the target token to capture the pure concept without direct supervision. Extensive experiments demonstrate that ConceptPrism effectively resolves concept entanglement, achieving a significantly improved trade-off between fidelity and alignment.
FxSearcher: gradient-free text-driven audio transformation
Nov 18, 2025Achieving diverse and high-quality audio transformations from text prompts remains challenging, as existing methods are fundamentally constrained by their reliance on a limited set of differentiable audio effects. This paper proposes \textbf{FxSearcher}, a novel gradient-free framework that discovers the optimal configuration of audio effects (FX) to transform a source signal according to a text prompt. Our method employs Bayesian Optimization and CLAP-based score function to perform this search efficiently. Furthermore, a guiding prompt is introduced to prevent undesirable artifacts and enhance human preference. To objectively evaluate our method, we propose an AI-based evaluation framework. The results demonstrate that the highest scores achieved by our method on these metrics align closely with human preferences. Demos are available at https://hojoonki.github.io/FxSearcher/
Comparison Reveals Commonality: Customized Image Generation through Contrastive Inversion
Aug 11, 2025The recent demand for customized image generation raises a need for techniques that effectively extract the common concept from small sets of images. Existing methods typically rely on additional guidance, such as text prompts or spatial masks, to capture the common target concept. Unfortunately, relying on manually provided guidance can lead to incomplete separation of auxiliary features, which degrades generation quality.In this paper, we propose Contrastive Inversion, a novel approach that identifies the common concept by comparing the input images without relying on additional information. We train the target token along with the image-wise auxiliary text tokens via contrastive learning, which extracts the well-disentangled true semantics of the target. Then we apply disentangled cross-attention fine-tuning to improve concept fidelity without overfitting. Experimental results and analysis demonstrate that our method achieves a balanced, high-level performance in both concept representation and editing, outperforming existing techniques.
FairASR: Fair Audio Contrastive Learning for Automatic Speech Recognition
Jun 12, 2025Large-scale ASR models have achieved remarkable gains in accuracy and robustness. However, fairness issues remain largely unaddressed despite their critical importance in real-world applications. In this work, we introduce FairASR, a system that mitigates demographic bias by learning representations that are uninformative about group membership, enabling fair generalization across demographic groups. Leveraging a multi-demographic dataset, our approach employs a gradient reversal layer to suppress demographic-discriminative features while maintaining the ability to capture generalizable speech patterns through an unsupervised contrastive loss. Experimental results show that FairASR delivers competitive overall ASR performance while significantly reducing performance disparities across different demographic groups.
SFLD: Reducing the content bias for AI-generated Image Detection
Feb 24, 2025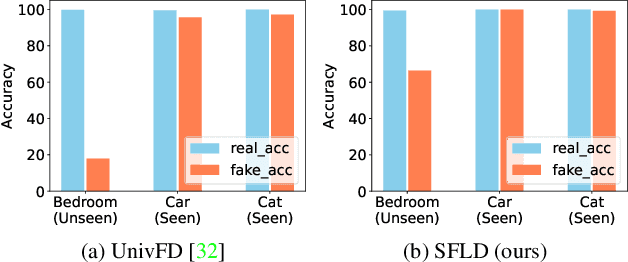
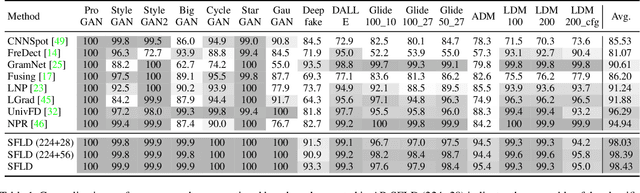

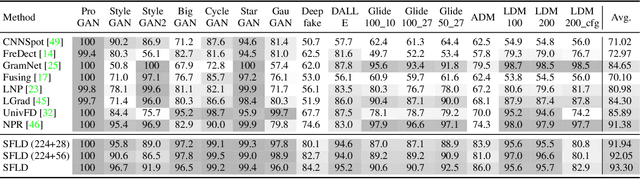
Identifying AI-generated content is critical for the safe and ethical use of generative AI. Recent research has focused on developing detectors that generalize to unknown generators, with popular methods relying either on high-level features or low-level fingerprints. However, these methods have clear limitations: biased towards unseen content, or vulnerable to common image degradations, such as JPEG compression. To address these issues, we propose a novel approach, SFLD, which incorporates PatchShuffle to integrate high-level semantic and low-level textural information. SFLD applies PatchShuffle at multiple levels, improving robustness and generalization across various generative models. Additionally, current benchmarks face challenges such as low image quality, insufficient content preservation, and limited class diversity. In response, we introduce TwinSynths, a new benchmark generation methodology that constructs visually near-identical pairs of real and synthetic images to ensure high quality and content preservation. Our extensive experiments and analysis show that SFLD outperforms existing methods on detecting a wide variety of fake images sourced from GANs, diffusion models, and TwinSynths, demonstrating the state-of-the-art performance and generalization capabilities to novel generative models.
StablePrompt: Automatic Prompt Tuning using Reinforcement Learning for Large Language Models
Oct 10, 2024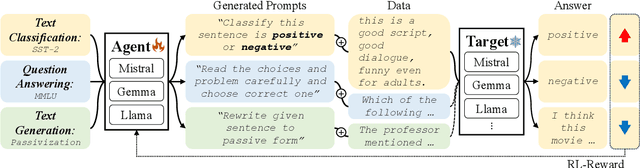
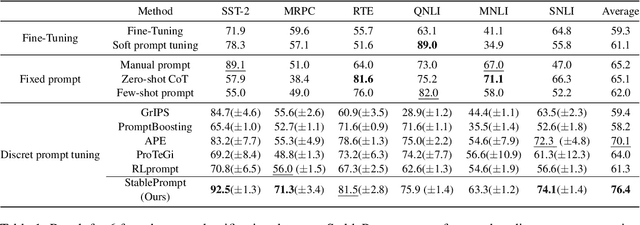
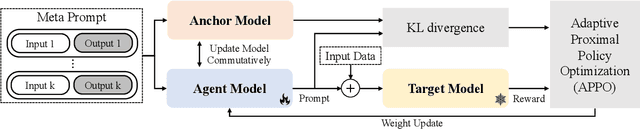
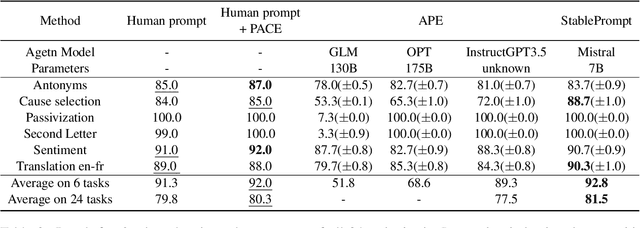
Finding appropriate prompts for the specific task has become an important issue as the usage of Large Language Models (LLM) has expanded. Reinforcement Learning (RL) is widely used for prompt tuning, but its inherent instability and environmental dependency make it difficult to use in practice. In this paper, we propose StablePrompt, which strikes a balance between training stability and search space, mitigating the instability of RL and producing high-performance prompts. We formulate prompt tuning as an online RL problem between the agent and target LLM and introduce Adaptive Proximal Policy Optimization (APPO). APPO introduces an LLM anchor model to adaptively adjust the rate of policy updates. This allows for flexible prompt search while preserving the linguistic ability of the pre-trained LLM. StablePrompt outperforms previous methods on various tasks including text classification, question answering, and text generation. Our code can be found in github.
Revisiting Softmax Masking for Stability in Continual Learning
Sep 26, 2023In continual learning, many classifiers use softmax function to learn confidence. However, numerous studies have pointed out its inability to accurately determine confidence distributions for outliers, often referred to as epistemic uncertainty. This inherent limitation also curtails the accurate decisions for selecting what to forget and keep in previously trained confidence distributions over continual learning process. To address the issue, we revisit the effects of masking softmax function. While this method is both simple and prevalent in literature, its implication for retaining confidence distribution during continual learning, also known as stability, has been under-investigated. In this paper, we revisit the impact of softmax masking, and introduce a methodology to utilize its confidence preservation effects. In class- and task-incremental learning benchmarks with and without memory replay, our approach significantly increases stability while maintaining sufficiently large plasticity. In the end, our methodology shows better overall performance than state-of-the-art methods, particularly in the use with zero or small memory. This lays a simple and effective foundation of strongly stable replay-based continual learning.
Enhancing Accuracy and Robustness through Adversarial Training in Class Incremental Continual Learning
May 23, 2023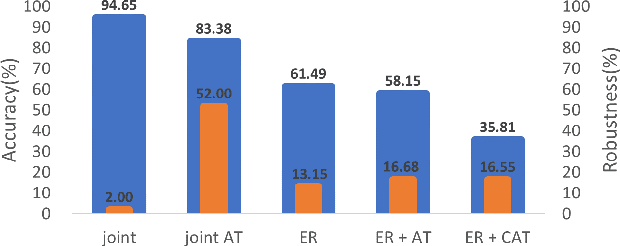
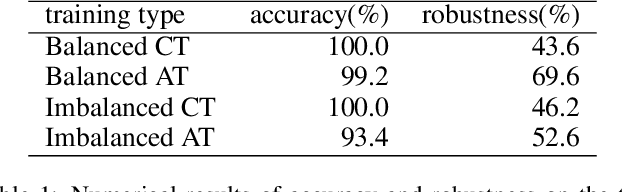
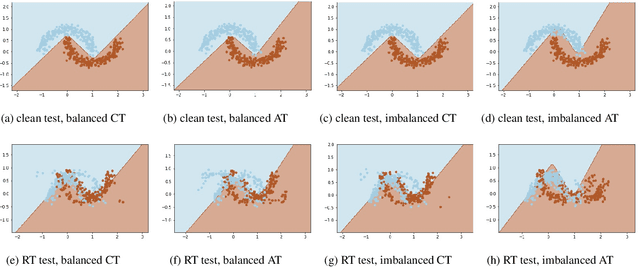

In real life, adversarial attack to deep learning models is a fatal security issue. However, the issue has been rarely discussed in a widely used class-incremental continual learning (CICL). In this paper, we address problems of applying adversarial training to CICL, which is well-known defense method against adversarial attack. A well-known problem of CICL is class-imbalance that biases a model to the current task by a few samples of previous tasks. Meeting with the adversarial training, the imbalance causes another imbalance of attack trials over tasks. Lacking clean data of a minority class by the class-imbalance and increasing of attack trials from a majority class by the secondary imbalance, adversarial training distorts optimal decision boundaries. The distortion eventually decreases both accuracy and robustness than adversarial training. To exclude the effects, we propose a straightforward but significantly effective method, External Adversarial Training (EAT) which can be applied to methods using experience replay. This method conduct adversarial training to an auxiliary external model for the current task data at each time step, and applies generated adversarial examples to train the target model. We verify the effects on a toy problem and show significance on CICL benchmarks of image classification. We expect that the results will be used as the first baseline for robustness research of CICL.