 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStablePrompt: Automatic Prompt Tuning using Reinforcement Learning for Large Language Models
Paper and Code
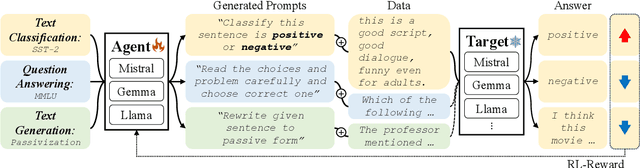
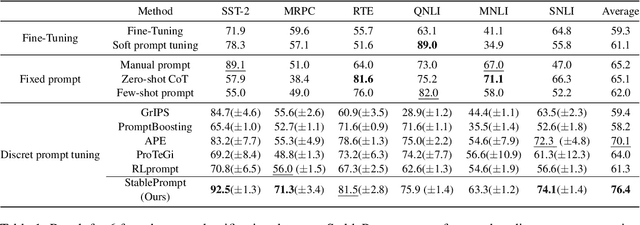
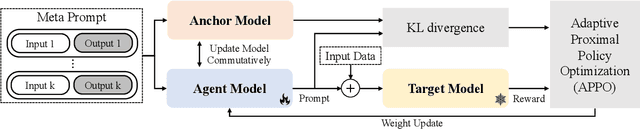
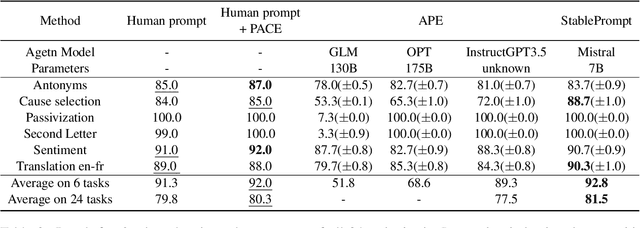
Finding appropriate prompts for the specific task has become an important issue as the usage of Large Language Models (LLM) has expanded. Reinforcement Learning (RL) is widely used for prompt tuning, but its inherent instability and environmental dependency make it difficult to use in practice. In this paper, we propose StablePrompt, which strikes a balance between training stability and search space, mitigating the instability of RL and producing high-performance prompts. We formulate prompt tuning as an online RL problem between the agent and target LLM and introduce Adaptive Proximal Policy Optimization (APPO). APPO introduces an LLM anchor model to adaptively adjust the rate of policy updates. This allows for flexible prompt search while preserving the linguistic ability of the pre-trained LLM. StablePrompt outperforms previous methods on various tasks including text classification, question answering, and text generation. Our code can be found in github.