 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotic Midpoint Mixup for Margin Balancing and Moderate Broadening
Jan 26, 2024In the feature space, the collapse between features invokes critical problems in representation learning by remaining the features undistinguished. Interpolation-based augmentation methods such as mixup have shown their effectiveness in relieving the collapse problem between different classes, called inter-class collapse. However, intra-class collapse raised in coarse-to-fine transfer learning has not been discussed in the augmentation approach. To address them, we propose a better feature augmentation method, asymptotic midpoint mixup. The method generates augmented features by interpolation but gradually moves them toward the midpoint of inter-class feature pairs. As a result, the method induces two effects: 1) balancing the margin for all classes and 2) only moderately broadening the margin until it holds maximal confidence. We empirically analyze the collapse effects by measuring alignment and uniformity with visualizing representations. Then, we validate the intra-class collapse effects in coarse-to-fine transfer learning and the inter-class collapse effects in imbalanced learning on long-tailed datasets. In both tasks, our method shows better performance than other augmentation methods.
Revisiting Softmax Masking for Stability in Continual Learning
Sep 26, 2023In continual learning, many classifiers use softmax function to learn confidence. However, numerous studies have pointed out its inability to accurately determine confidence distributions for outliers, often referred to as epistemic uncertainty. This inherent limitation also curtails the accurate decisions for selecting what to forget and keep in previously trained confidence distributions over continual learning process. To address the issue, we revisit the effects of masking softmax function. While this method is both simple and prevalent in literature, its implication for retaining confidence distribution during continual learning, also known as stability, has been under-investigated. In this paper, we revisit the impact of softmax masking, and introduce a methodology to utilize its confidence preservation effects. In class- and task-incremental learning benchmarks with and without memory replay, our approach significantly increases stability while maintaining sufficiently large plasticity. In the end, our methodology shows better overall performance than state-of-the-art methods, particularly in the use with zero or small memory. This lays a simple and effective foundation of strongly stable replay-based continual learning.
Learning from Matured Dumb Teacher for Fine Generalization
Aug 17, 2021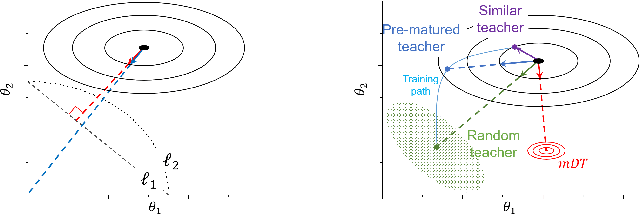
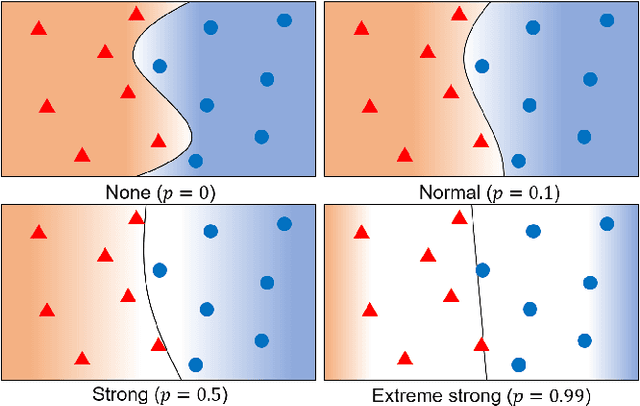
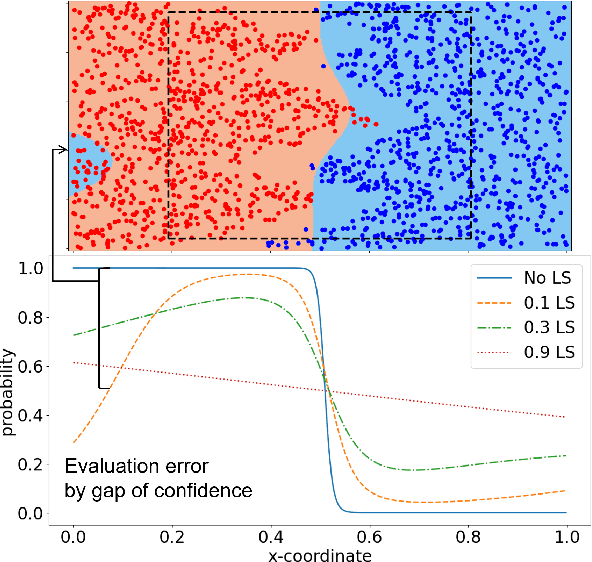
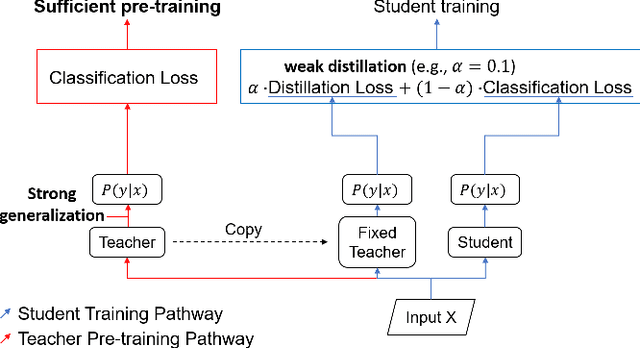
The flexibility of decision boundaries in neural networks that are unguided by training data is a well-known problem typically resolved with generalization methods. A surprising result from recent knowledge distillation (KD) literature is that random, untrained, and equally structured teacher networks can also vastly improve generalization performance. It raises the possibility of existence of undiscovered assumptions useful for generalization on an uncertain region. In this paper, we shed light on the assumptions by analyzing decision boundaries and confidence distributions of both simple and KD-based generalization methods. Assuming that a decision boundary exists to represent the most general tendency of distinction on an input sample space (i.e., the simplest hypothesis), we show the various limitations of methods when using the hypothesis. To resolve these limitations, we propose matured dumb teacher based KD, conservatively transferring the hypothesis for generalization of the student without massive destruction of trained information. In practical experiments on feed-forward and convolution neural networks for image classification tasks on MNIST, CIFAR-10, and CIFAR-100 datasets, the proposed method shows stable improvement to the best test performance in the grid search of hyperparameters. The analysis and results imply that the proposed method can provide finer generalization than existing methods.