 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFLD: Reducing the content bias for AI-generated Image Detection
Feb 24, 2025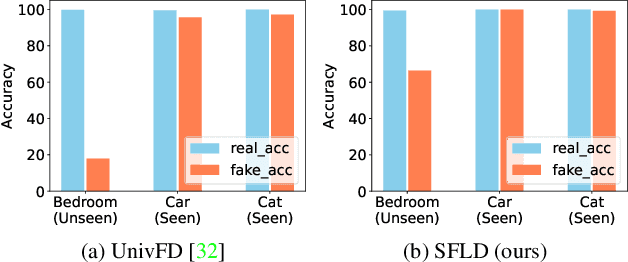
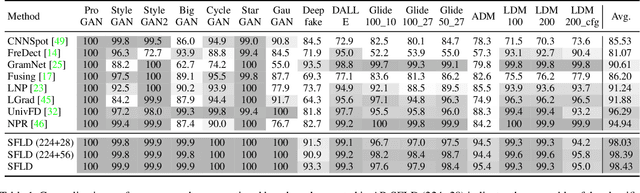

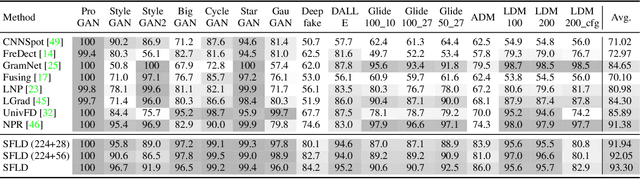
Identifying AI-generated content is critical for the safe and ethical use of generative AI. Recent research has focused on developing detectors that generalize to unknown generators, with popular methods relying either on high-level features or low-level fingerprints. However, these methods have clear limitations: biased towards unseen content, or vulnerable to common image degradations, such as JPEG compression. To address these issues, we propose a novel approach, SFLD, which incorporates PatchShuffle to integrate high-level semantic and low-level textural information. SFLD applies PatchShuffle at multiple levels, improving robustness and generalization across various generative models. Additionally, current benchmarks face challenges such as low image quality, insufficient content preservation, and limited class diversity. In response, we introduce TwinSynths, a new benchmark generation methodology that constructs visually near-identical pairs of real and synthetic images to ensure high quality and content preservation. Our extensive experiments and analysis show that SFLD outperforms existing methods on detecting a wide variety of fake images sourced from GANs, diffusion models, and TwinSynths, demonstrating the state-of-the-art performance and generalization capabilities to novel generative models.
Beta Sampling is All You Need: Efficient Image Generation Strategy for Diffusion Models using Stepwise Spectral Analysis
Jul 16, 2024



Generative diffusion models have emerged as a powerful tool for high-quality image synthesis, yet their iterative nature demands significant computational resources. This paper proposes an efficient time step sampling method based on an image spectral analysis of the diffusion process, aimed at optimizing the denoising process. Instead of the traditional uniform distribution-based time step sampling, we introduce a Beta distribution-like sampling technique that prioritizes critical steps in the early and late stages of the process. Our hypothesis is that certain steps exhibit significant changes in image content, while others contribute minimally. We validated our approach using Fourier transforms to measure frequency response changes at each step, revealing substantial low-frequency changes early on and high-frequency adjustments later. Experiments with ADM and Stable Diffusion demonstrated that our Beta Sampling method consistently outperforms uniform sampling, achieving better FID and IS scores, and offers competitive efficiency relative to state-of-the-art methods like AutoDiffusion. This work provides a practical framework for enhancing diffusion model efficiency by focusing computational resources on the most impactful steps, with potential for further optimization and broader application.