 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFloMat: Detection with Flow Matching for Stable and Efficient Generative Object Localization
Dec 26, 2025We propose DeFloMat (Detection with Flow Matching), a novel generative object detection framework that addresses the critical latency bottleneck of diffusion-based detectors, such as DiffusionDet, by integrating Conditional Flow Matching (CFM). Diffusion models achieve high accuracy by formulating detection as a multi-step stochastic denoising process, but their reliance on numerous sampling steps ($T \gg 60$) makes them impractical for time-sensitive clinical applications like Crohn's Disease detection in Magnetic Resonance Enterography (MRE). DeFloMat replaces this slow stochastic path with a highly direct, deterministic flow field derived from Conditional Optimal Transport (OT) theory, specifically approximating the Rectified Flow. This shift enables fast inference via a simple Ordinary Differential Equation (ODE) solver. We demonstrate the superiority of DeFloMat on a challenging MRE clinical dataset. Crucially, DeFloMat achieves state-of-the-art accuracy ($43.32\% \text{ } AP_{10:50}$) in only $3$ inference steps, which represents a $1.4\times$ performance improvement over DiffusionDet's maximum converged performance ($31.03\% \text{ } AP_{10:50}$ at $4$ steps). Furthermore, our deterministic flow significantly enhances localization characteristics, yielding superior Recall and stability in the few-step regime. DeFloMat resolves the trade-off between generative accuracy and clinical efficiency, setting a new standard for stable and rapid object localization.
Beta Sampling is All You Need: Efficient Image Generation Strategy for Diffusion Models using Stepwise Spectral Analysis
Jul 16, 2024



Generative diffusion models have emerged as a powerful tool for high-quality image synthesis, yet their iterative nature demands significant computational resources. This paper proposes an efficient time step sampling method based on an image spectral analysis of the diffusion process, aimed at optimizing the denoising process. Instead of the traditional uniform distribution-based time step sampling, we introduce a Beta distribution-like sampling technique that prioritizes critical steps in the early and late stages of the process. Our hypothesis is that certain steps exhibit significant changes in image content, while others contribute minimally. We validated our approach using Fourier transforms to measure frequency response changes at each step, revealing substantial low-frequency changes early on and high-frequency adjustments later. Experiments with ADM and Stable Diffusion demonstrated that our Beta Sampling method consistently outperforms uniform sampling, achieving better FID and IS scores, and offers competitive efficiency relative to state-of-the-art methods like AutoDiffusion. This work provides a practical framework for enhancing diffusion model efficiency by focusing computational resources on the most impactful steps, with potential for further optimization and broader application.
GenMix: Combining Generative and Mixture Data Augmentation for Medical Image Classification
May 31, 2024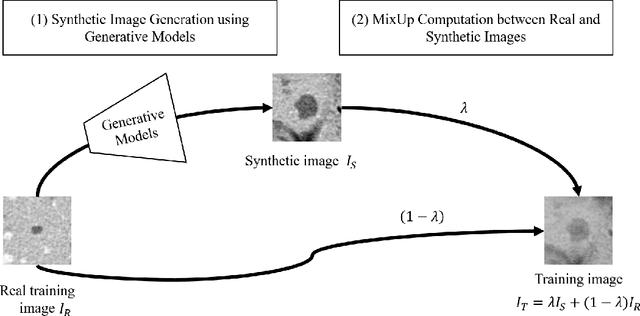
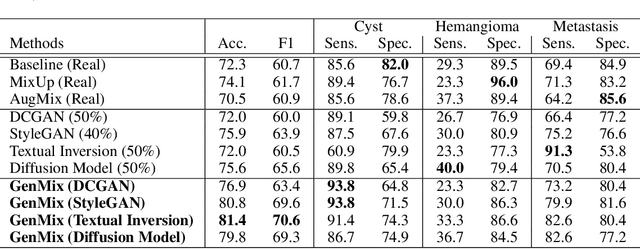

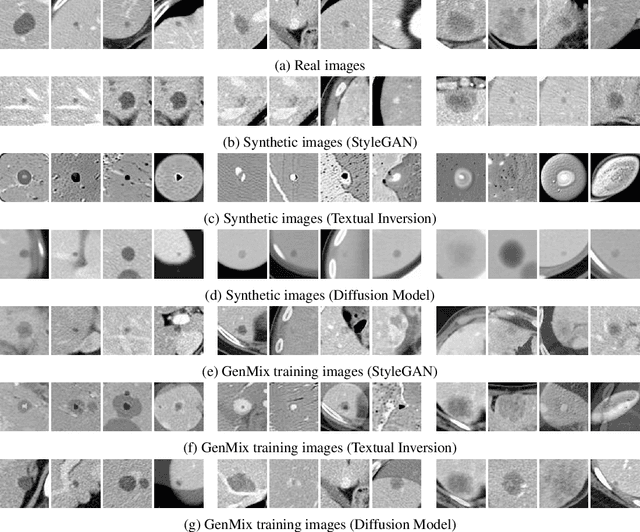
In this paper, we propose a novel data augmentation technique called GenMix, which combines generative and mixture approaches to leverage the strengths of both methods. While generative models excel at creating new data patterns, they face challenges such as mode collapse in GANs and difficulties in training diffusion models, especially with limited medical imaging data. On the other hand, mixture models enhance class boundary regions but tend to favor the major class in scenarios with class imbalance. To address these limitations, GenMix integrates both approaches to complement each other. GenMix operates in two stages: (1) training a generative model to produce synthetic images, and (2) performing mixup between synthetic and real data. This process improves the quality and diversity of synthetic data while simultaneously benefiting from the new pattern learning of generative models and the boundary enhancement of mixture models. We validate the effectiveness of our method on the task of classifying focal liver lesions (FLLs) in CT images. Our results demonstrate that GenMix enhances the performance of various generative models, including DCGAN, StyleGAN, Textual Inversion, and Diffusion Models. Notably, the proposed method with Textual Inversion outperforms other methods without fine-tuning diffusion model on the FLL dataset.
DropMix: Reducing Class Dependency in Mixed Sample Data Augmentation
Jul 18, 2023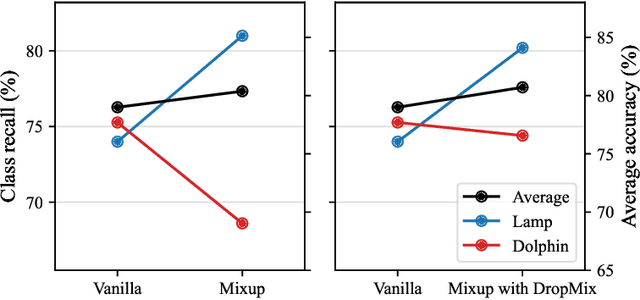
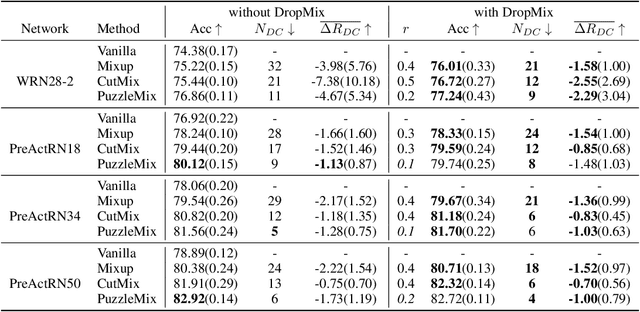


Mixed sample data augmentation (MSDA) is a widely used technique that has been found to improve performance in a variety of tasks. However, in this paper, we show that the effects of MSDA are class-dependent, with some classes seeing an improvement in performance while others experience a decline. To reduce class dependency, we propose the DropMix method, which excludes a specific percentage of data from the MSDA computation. By training on a combination of MSDA and non-MSDA data, the proposed method not only improves the performance of classes that were previously degraded by MSDA, but also increases overall average accuracy, as shown in experiments on two datasets (CIFAR-100 and ImageNet) using three MSDA methods (Mixup, CutMix and PuzzleMix).
Noisy Label Classification using Label Noise Selection with Test-Time Augmentation Cross-Entropy and NoiseMix Learning
Dec 01, 2022As the size of the dataset used in deep learning tasks increases, the noisy label problem, which is a task of making deep learning robust to the incorrectly labeled data, has become an important task. In this paper, we propose a method of learning noisy label data using the label noise selection with test-time augmentation (TTA) cross-entropy and classifier learning with the NoiseMix method. In the label noise selection, we propose TTA cross-entropy by measuring the cross-entropy to predict the test-time augmented training data. In the classifier learning, we propose the NoiseMix method based on MixUp and BalancedMix methods by mixing the samples from the noisy and the clean label data. In experiments on the ISIC-18 public skin lesion diagnosis dataset, the proposed TTA cross-entropy outperformed the conventional cross-entropy and the TTA uncertainty in detecting label noise data in the label noise selection process. Moreover, the proposed NoiseMix not only outperformed the state-of-the-art methods in the classification performance but also showed the most robustness to the label noise in the classifier learning.
Test-Time Mixup Augmentation for Data and Class-Specific Uncertainty Estimation in Multi-Class Image Classification
Dec 01, 2022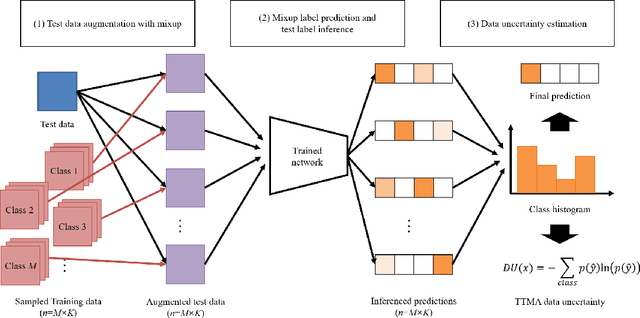
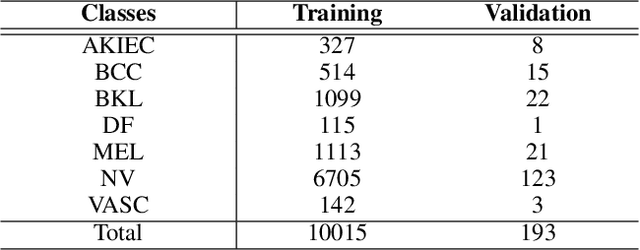
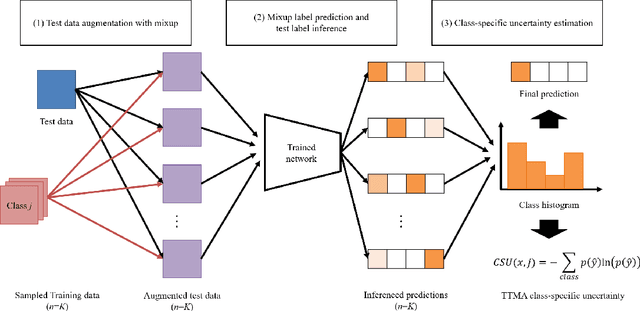
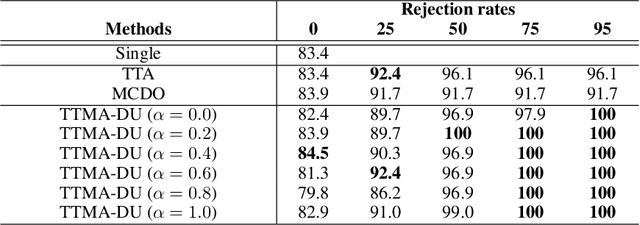
Uncertainty estimation of the trained deep learning network provides important information for improving the learning efficiency or evaluating the reliability of the network prediction. In this paper, we propose a method for the uncertainty estimation for multi-class image classification using test-time mixup augmentation (TTMA). To improve the discrimination ability between the correct and incorrect prediction of the existing aleatoric uncertainty, we propose the data uncertainty by applying the mixup augmentation on the test data and measuring the entropy of the histogram of predicted labels. In addition to the data uncertainty, we propose a class-specific uncertainty presenting the aleatoric uncertainty associated with the specific class, which can provide information on the class confusion and class similarity of the trained network. The proposed methods are validated on two public datasets, the ISIC-18 skin lesion diagnosis dataset, and the CIFAR-100 real-world image classification dataset. The experiments demonstrate that (1) the proposed data uncertainty better separates the correct and incorrect prediction than the existing uncertainty measures thanks to the mixup perturbation, and (2) the proposed class-specific uncertainty provides information on the class confusion and class similarity of the trained network for both datasets.