 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegral Policy Iterations for Reinforcement Learning Problems in Continuous Time and Space
Paper and Code

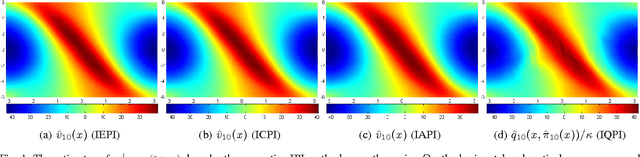


Policy iteration (PI) is a recursive process of policy evaluation and improvement to solve an optimal decision-making, e.g., reinforcement learning (RL) or optimal control problem and has served as the fundamental to develop RL methods. Motivated by integral PI (IPI) schemes in optimal control and RL methods in continuous time and space (CTS), this paper proposes on-policy IPI to solve the general RL problem in CTS, with its environment modeled by an ordinary differential equation (ODE). In such continuous domain, we also propose four off-policy IPI methods---two are the ideal PI forms that use advantage and Q-functions, respectively, and the other two are natural extensions of the existing off-policy IPI schemes to our general RL framework. Compared to the IPI methods in optimal control, the proposed IPI schemes can be applied to more general situations and do not require an initial stabilizing policy to run; they are also strongly relevant to the RL algorithms in CTS such as advantage updating, Q-learning, and value-gradient based (VGB) greedy policy improvement. Our on-policy IPI is basically model-based but can be made partially model-free; each off-policy method is also either partially or completely model-free. The mathematical properties of the IPI methods---admissibility, monotone improvement, and convergence towards the optimal solution---are all rigorously proven, together with the equivalence of on- and off-policy IPI. Finally, the IPI methods are simulated with an inverted-pendulum model to support the theory and verify the performance.