 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Distilling Knowledge Priors from Literature for Therapeutic Design
Aug 14, 2025AI-driven discovery can greatly reduce design time and enhance new therapeutics' effectiveness. Models using simulators explore broad design spaces but risk violating implicit constraints due to a lack of experimental priors. For example, in a new analysis we performed on a diverse set of models on the GuacaMol benchmark using supervised classifiers, over 60\% of molecules proposed had high probability of being mutagenic. In this work, we introduce \ourdataset, a dataset of priors for design problems extracted from literature describing compounds used in lab settings. It is constructed with LLM pipelines for discovering therapeutic entities in relevant paragraphs and summarizing information in concise fair-use facts. \ourdataset~ consists of 32.3 million pairs of natural language facts, and appropriate entity representations (i.e. SMILES or refseq IDs). To demonstrate the potential of the data, we train LLM, CLIP, and LLava architectures to reason jointly about text and design targets and evaluate on tasks from the Therapeutic Data Commons (TDC). \ourdataset~is highly effective for creating models with strong priors: in supervised prediction problems that use our data as pretraining, our best models with 15M learnable parameters outperform larger 2B TxGemma on both regression and classification TDC tasks, and perform comparably to 9B models on average. Models built with \ourdataset~can be used as constraints while optimizing for novel molecules in GuacaMol, resulting in proposals that are safer and nearly as effective. We release our dataset at \href{https://huggingface.co/datasets/medexanon/Medex}{huggingface.co/datasets/medexanon/Medex}, and will provide expanded versions as available literature grows.
RITA: Group Attention is All You Need for Timeseries Analytics
Jun 02, 2023Timeseries analytics is of great importance in many real-world applications. Recently, the Transformer model, popular in natural language processing, has been leveraged to learn high quality feature embeddings from timeseries, core to the performance of various timeseries analytics tasks. However, the quadratic time and space complexities limit Transformers' scalability, especially for long timeseries. To address these issues, we develop a timeseries analytics tool, RITA, which uses a novel attention mechanism, named group attention, to address this scalability issue. Group attention dynamically clusters the objects based on their similarity into a small number of groups and approximately computes the attention at the coarse group granularity. It thus significantly reduces the time and space complexity, yet provides a theoretical guarantee on the quality of the computed attention. The dynamic scheduler of RITA continuously adapts the number of groups and the batch size in the training process, ensuring group attention always uses the fewest groups needed to meet the approximation quality requirement. Extensive experiments on various timeseries datasets and analytics tasks demonstrate that RITA outperforms the state-of-the-art in accuracy and is significantly faster -- with speedups of up to 63X.
Interactive Data Integration through Smart Copy & Paste
Sep 09, 2009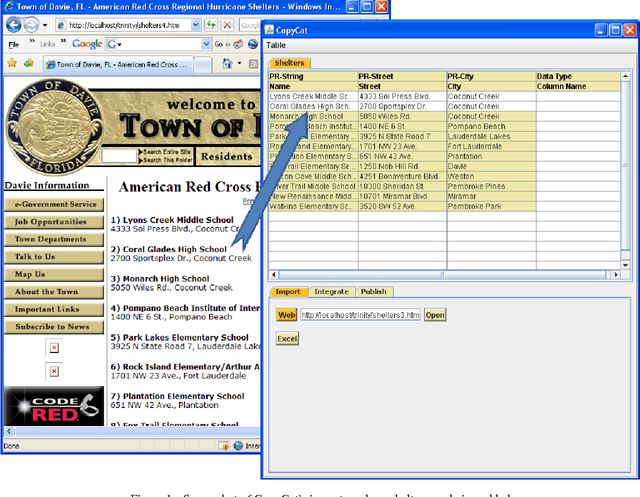

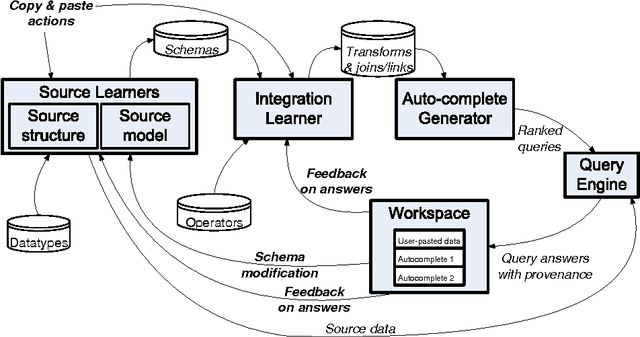
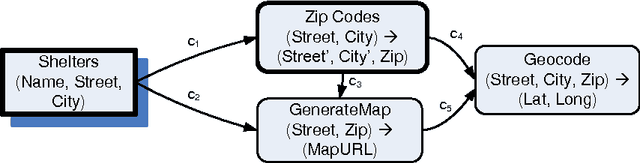
In many scenarios, such as emergency response or ad hoc collaboration, it is critical to reduce the overhead in integrating data. Ideally, one could perform the entire process interactively under one unified interface: defining extractors and wrappers for sources, creating a mediated schema, and adding schema mappings ? while seeing how these impact the integrated view of the data, and refining the design accordingly. We propose a novel smart copy and paste (SCP) model and architecture for seamlessly combining the design-time and run-time aspects of data integration, and we describe an initial prototype, the CopyCat system. In CopyCat, the user does not need special tools for the different stages of integration: instead, the system watches as the user copies data from applications (including the Web browser) and pastes them into CopyCat?s spreadsheet-like workspace. CopyCat generalizes these actions and presents proposed auto-completions, each with an explanation in the form of provenance. The user provides feedback on these suggestions ? through either direct interactions or further copy-and-paste operations ? and the system learns from this feedback. This paper provides an overview of our prototype system, and identifies key research challenges in achieving SCP in its full generality.