 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronoSpike: An Adaptive Spiking Graph Neural Network for Dynamic Graphs
Feb 01, 2026Dynamic graph representation learning requires capturing both structural relationships and temporal evolution, yet existing approaches face a fundamental trade-off: attention-based methods achieve expressiveness at $O(T^2)$ complexity, while recurrent architectures suffer from gradient pathologies and dense state storage. Spiking neural networks offer event-driven efficiency but remain limited by sequential propagation, binary information loss, and local aggregation that misses global context. We propose ChronoSpike, an adaptive spiking graph neural network that integrates learnable LIF neurons with per-channel membrane dynamics, multi-head attentive spatial aggregation on continuous features, and a lightweight Transformer temporal encoder, enabling both fine-grained local modeling and long-range dependency capture with linear memory complexity $O(T \cdot d)$. On three large-scale benchmarks, ChronoSpike outperforms twelve state-of-the-art baselines by $2.0\%$ Macro-F1 and $2.4\%$ Micro-F1 while achieving $3-10\times$ faster training than recurrent methods with a constant 105K-parameter budget independent of graph size. We provide theoretical guarantees for membrane potential boundedness, gradient flow stability under contraction factor $ρ< 1$, and BIBO stability; interpretability analyses reveal heterogeneous temporal receptive fields and a learned primacy effect with $83-88\%$ sparsity.
Interactive Data Integration through Smart Copy & Paste
Sep 09, 2009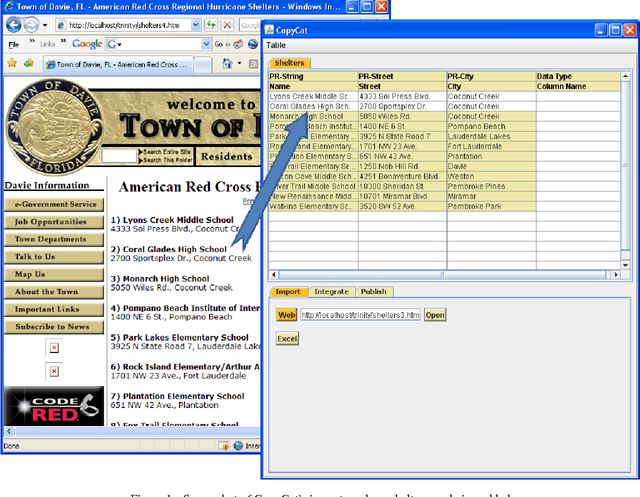

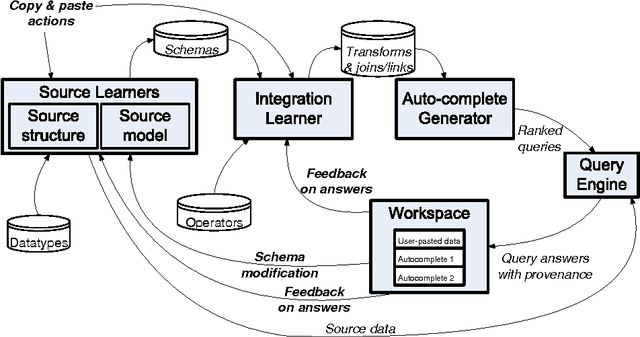
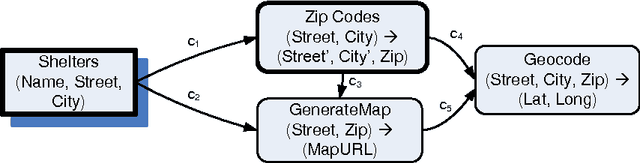
In many scenarios, such as emergency response or ad hoc collaboration, it is critical to reduce the overhead in integrating data. Ideally, one could perform the entire process interactively under one unified interface: defining extractors and wrappers for sources, creating a mediated schema, and adding schema mappings ? while seeing how these impact the integrated view of the data, and refining the design accordingly. We propose a novel smart copy and paste (SCP) model and architecture for seamlessly combining the design-time and run-time aspects of data integration, and we describe an initial prototype, the CopyCat system. In CopyCat, the user does not need special tools for the different stages of integration: instead, the system watches as the user copies data from applications (including the Web browser) and pastes them into CopyCat?s spreadsheet-like workspace. CopyCat generalizes these actions and presents proposed auto-completions, each with an explanation in the form of provenance. The user provides feedback on these suggestions ? through either direct interactions or further copy-and-paste operations ? and the system learns from this feedback. This paper provides an overview of our prototype system, and identifies key research challenges in achieving SCP in its full generality.