 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCRF: A Federated Cross-domain Recommendation Method with Semantic-driven Deep Knowledge Fusion
Apr 20, 2026As user behavior data becomes increasingly scattered across different platforms, achieving cross-domain knowledge fusion while preserving privacy has become a critical issue in recommender systems. Existing PPCDR methods usually rely on overlapping users or items as a bridge, making them inapplicable to non-overlapping scenarios. They also suffer from limitations in the collaborative modeling of global and local semantics. To this end, this paper proposes a Federated Cross-domain Recommendation method with deep knowledge Fusion (FedCRF). Using textual semantics as a cross-domain bridge, FedCRF achieves cross-domain knowledge transfer via federated semantic learning under the non-overlapping scenario. Specifically, FedCRF constructs global semantic clusters on the server side to extract shared semantic information, and designs a FGSAT module on the client side to dynamically adapt to local data distributions and alleviate cross-domain distribution shift. Meanwhile, it builds a semantic graph based on textual features to learn representations that integrate both structural and semantic information, and introduces contrastive learning constraints between global and local semantic representations to enhance semantic consistency and promote deep knowledge fusion. In this framework, only item semantic representations are shared, while user interaction data remains locally stored, effectively mitigating privacy leakage risks. Experimental results on multiple real-world datasets show that FedCRF significantly outperforms existing methods in terms of Recall@20 and NDCG@20, validating its effectiveness and superiority in non-overlapping cross-domain recommendation scenarios.
MedDialogRubrics: A Comprehensive Benchmark and Evaluation Framework for Multi-turn Medical Consultations in Large Language Models
Jan 07, 2026Medical conversational AI (AI) plays a pivotal role in the development of safer and more effective medical dialogue systems. However, existing benchmarks and evaluation frameworks for assessing the information-gathering and diagnostic reasoning abilities of medical large language models (LLMs) have not been rigorously evaluated. To address these gaps, we present MedDialogRubrics, a novel benchmark comprising 5,200 synthetically constructed patient cases and over 60,000 fine-grained evaluation rubrics generated by LLMs and subsequently refined by clinical experts, specifically designed to assess the multi-turn diagnostic capabilities of LLM. Our framework employs a multi-agent system to synthesize realistic patient records and chief complaints from underlying disease knowledge without accessing real-world electronic health records, thereby mitigating privacy and data-governance concerns. We design a robust Patient Agent that is limited to a set of atomic medical facts and augmented with a dynamic guidance mechanism that continuously detects and corrects hallucinations throughout the dialogue, ensuring internal coherence and clinical plausibility of the simulated cases. Furthermore, we propose a structured LLM-based and expert-annotated rubric-generation pipeline that retrieves Evidence-Based Medicine (EBM) guidelines and utilizes the reject sampling to derive a prioritized set of rubric items ("must-ask" items) for each case. We perform a comprehensive evaluation of state-of-the-art models and demonstrate that, across multiple assessment dimensions, current models face substantial challenges. Our results indicate that improving medical dialogue will require advances in dialogue management architectures, not just incremental tuning of the base-model.
Monocle: Hybrid Local-Global In-Context Evaluation for Long-Text Generation with Uncertainty-Based Active Learning
May 27, 2025Assessing the quality of long-form, model-generated text is challenging, even with advanced LLM-as-a-Judge methods, due to performance degradation as input length increases. To address this issue, we propose a divide-and-conquer approach, which breaks down the comprehensive evaluation task into a series of localized scoring tasks, followed by a final global assessment. This strategy allows for more granular and manageable evaluations, ensuring that each segment of the text is assessed in isolation for both coherence and quality, while also accounting for the overall structure and consistency of the entire piece. Moreover, we introduce a hybrid in-context learning approach that leverages human annotations to enhance the performance of both local and global evaluations. By incorporating human-generated feedback directly into the evaluation process, this method allows the model to better align with human judgment. Finally, we develop an uncertainty-based active learning algorithm that efficiently selects data samples for human annotation, thereby reducing annotation costs in practical scenarios. Experimental results show that the proposed evaluation framework outperforms several representative baselines, highlighting the effectiveness of our approach.
FDLLM: A Text Fingerprint Detection Method for LLMs in Multi-Language, Multi-Domain Black-Box Environments
Jan 27, 2025



Using large language models (LLMs) integration platforms without transparency about which LLM is being invoked can lead to potential security risks. Specifically, attackers may exploit this black-box scenario to deploy malicious models and embed viruses in the code provided to users. In this context, it is increasingly urgent for users to clearly identify the LLM they are interacting with, in order to avoid unknowingly becoming victims of malicious models. However, existing studies primarily focus on mixed classification of human and machine-generated text, with limited attention to classifying texts generated solely by different models. Current research also faces dual bottlenecks: poor quality of LLM-generated text (LLMGT) datasets and limited coverage of detectable LLMs, resulting in poor detection performance for various LLMGT in black-box scenarios. We propose the first LLMGT fingerprint detection model, \textbf{FDLLM}, based on Qwen2.5-7B and fine-tuned using LoRA to address these challenges. FDLLM can more efficiently handle detection tasks across multilingual and multi-domain scenarios. Furthermore, we constructed a dataset named \textbf{FD-Datasets}, consisting of 90,000 samples that span multiple languages and domains, covering 20 different LLMs. Experimental results demonstrate that FDLLM achieves a macro F1 score 16.7\% higher than the best baseline method, LM-D.
Navigating User Experience of ChatGPT-based Conversational Recommender Systems: The Effects of Prompt Guidance and Recommendation Domain
May 22, 2024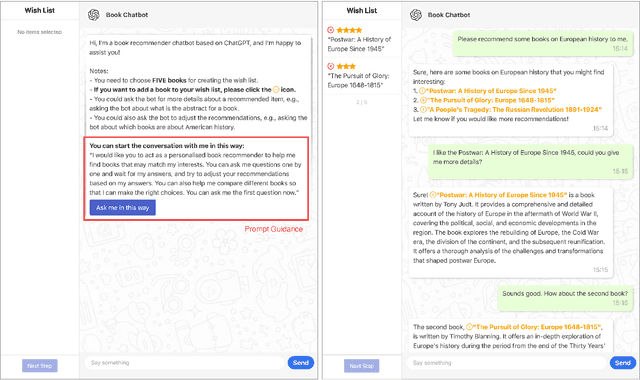
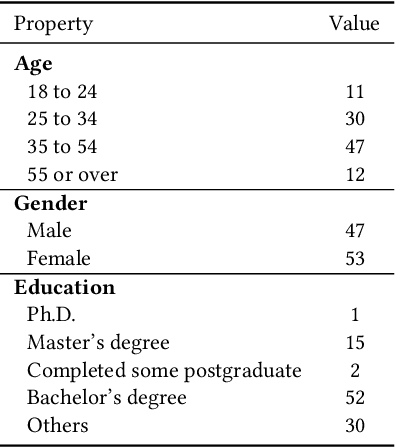
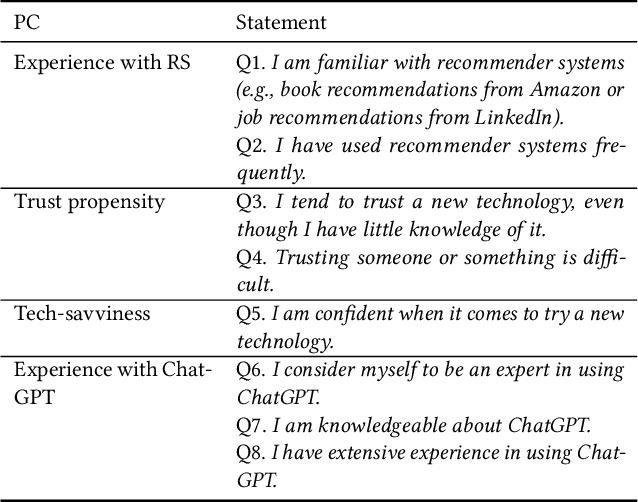
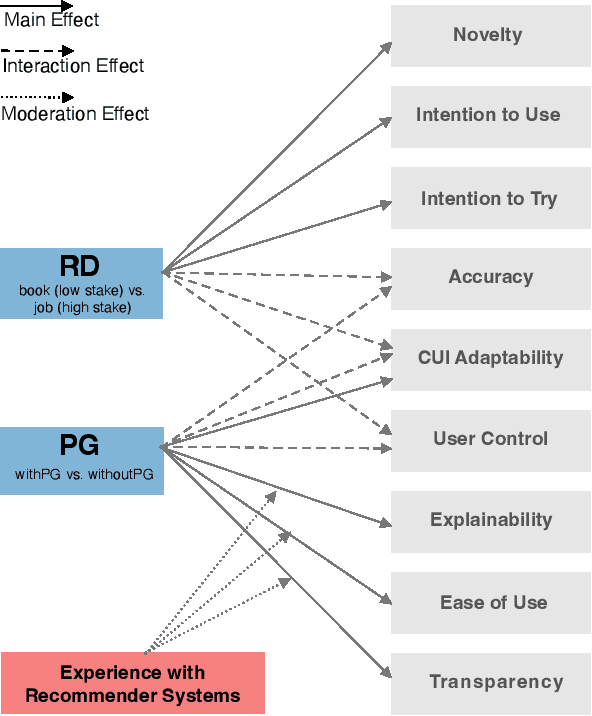
Conversational recommender systems (CRS) enable users to articulate their preferences and provide feedback through natural language. With the advent of large language models (LLMs), the potential to enhance user engagement with CRS and augment the recommendation process with LLM-generated content has received increasing attention. However, the efficacy of LLM-powered CRS is contingent upon the use of prompts, and the subjective perception of recommendation quality can differ across various recommendation domains. Therefore, we have developed a ChatGPT-based CRS to investigate the impact of these two factors, prompt guidance (PG) and recommendation domain (RD), on the overall user experience of the system. We conducted an online empirical study (N = 100) by employing a mixed-method approach that utilized a between-subjects design for the variable of PG (with vs. without) and a within-subjects design for RD (book recommendations vs. job recommendations). The findings reveal that PG can substantially enhance the system's explainability, adaptability, perceived ease of use, and transparency. Moreover, users are inclined to perceive a greater sense of novelty and demonstrate a higher propensity to engage with and try recommended items in the context of book recommendations as opposed to job recommendations. Furthermore, the influence of PG on certain user experience metrics and interactive behaviors appears to be modulated by the recommendation domain, as evidenced by the interaction effects between the two examined factors. This work contributes to the user-centered evaluation of ChatGPT-based CRS by investigating two prominent factors and offers practical design guidance.
Privacy-Preserved Blockchain-Federated-Learning for Medical Image Analysis Towards Multiple Parties
Apr 22, 2021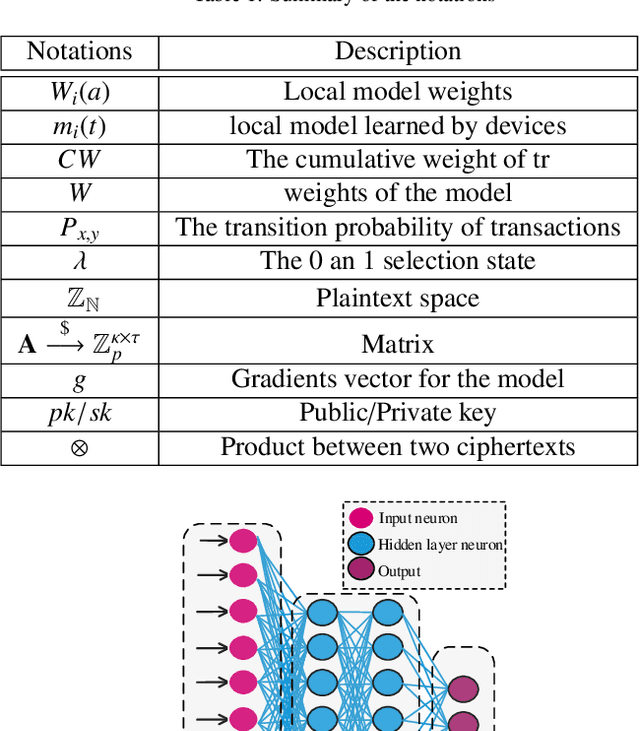
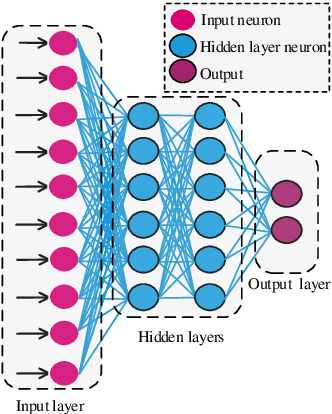
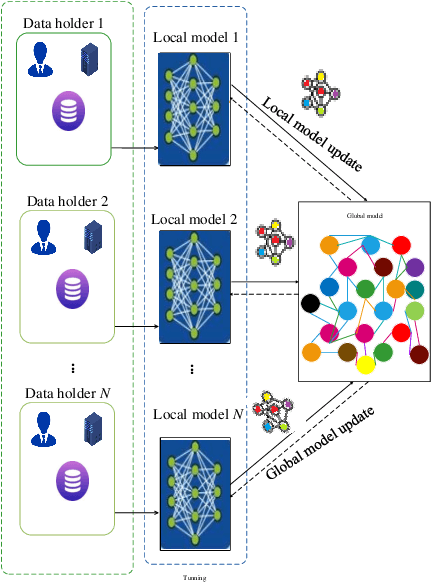
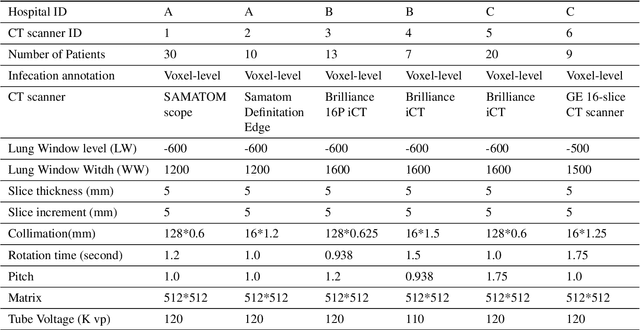
To share the patient\textquoteright s data in the blockchain network can help to learn the accurate deep learning model for the better prediction of COVID-19 patients. However, privacy (e.g., data leakage) and security (e.g., reliability or trust of data) concerns are the main challenging task for the health care centers. To solve this challenging task, this article designs a privacy-preserving framework based on federated learning and blockchain. In the first step, we train the local model by using the capsule network for the segmentation and classification of the COVID-19 images. The segmentation aims to extract nodules and classification to train the model. In the second step, we secure the local model through the homomorphic encryption scheme. The designed scheme encrypts and decrypts the gradients for federated learning. Moreover, for the decentralization of the model, we design a blockchain-based federated learning algorithm that can aggregate the gradients and update the local model. In this way, the proposed encryption scheme achieves the data provider privacy, and blockchain guarantees the reliability of the shared data. The experiment results demonstrate the performance of the proposed scheme.
IoTMalware: Android IoT Malware Detection based on Deep Neural Network and Blockchain Technology
Feb 26, 2021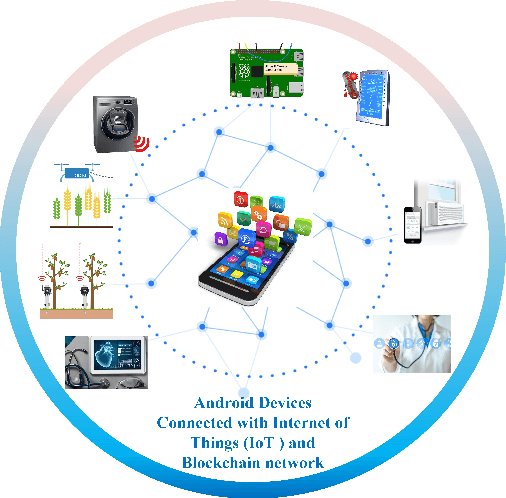
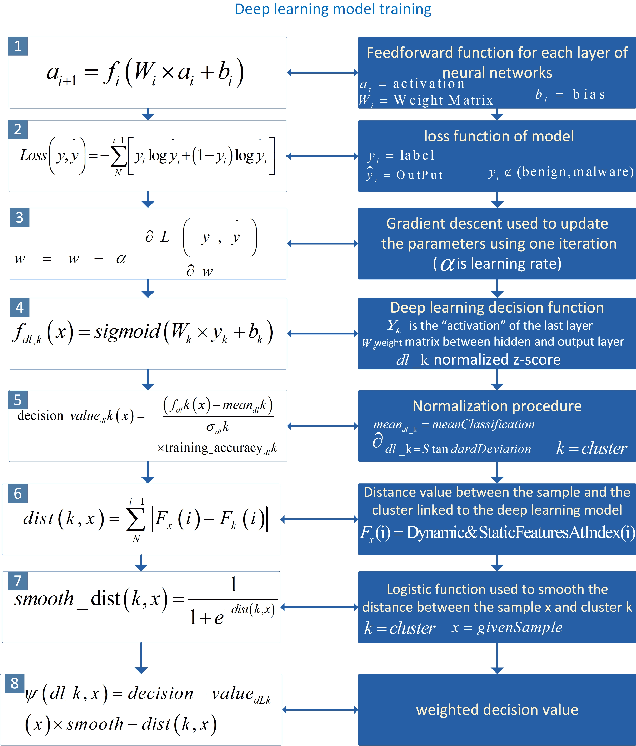
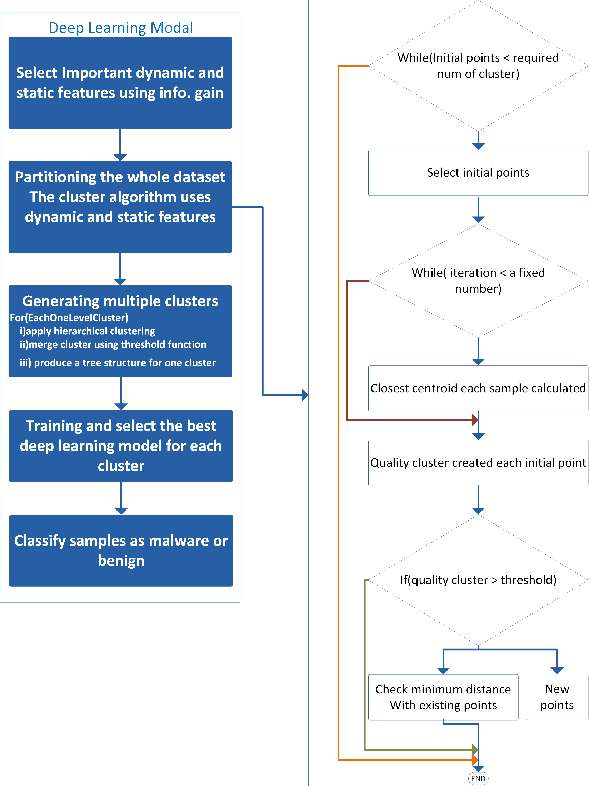
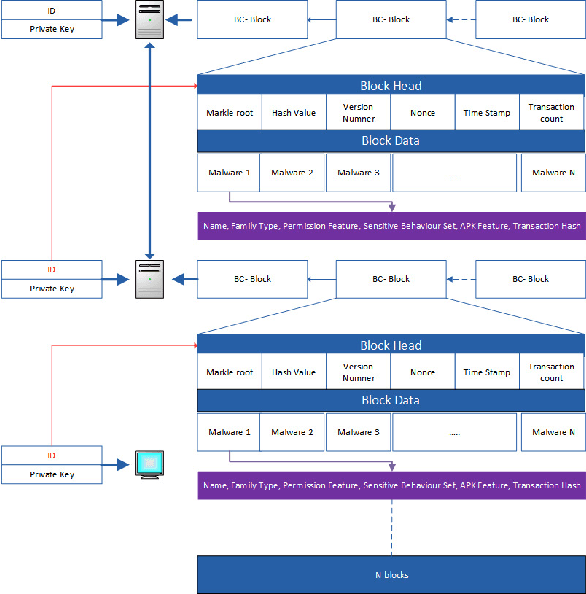
The Internet of Things (IoT) has been revolutionizing this world by introducing exciting applications almost in all walks of daily life, such as healthcare, smart cities, smart environments, safety, remote sensing, and many more. This paper proposes a new framework based on the blockchain and deep learning model to provide more security for Android IoT devices. Moreover, our framework is capable to find the malware activities in a real-time environment. The proposed deep learning model analyzes various static and dynamic features extracted from thousands of feature of malware and benign apps that are already stored in blockchain distributed ledger. The multi-layer deep learning model makes decisions by analyzing the previous data and follow some steps. Firstly, it divides the malware feature into multiple level clusters. Secondly, it chooses a unique deep learning model for each malware feature set or cluster. Finally, it produces the decision by combining the results generated from all cluster levels. Furthermore, the decisions and multiple-level clustering data are stored in a blockchain that can be further used to train every specialized cluster for unique data distribution. Also, a customized smart contract is designed to detect deceptive applications through the blockchain framework. The smart contract verifies the malicious application both during the uploading and downloading process of Android apps on the network. Consequently, the proposed framework provides flexibility to features for run-time security regarding malware detection on heterogeneous IoT devices. Finally, the smart contract helps to approve or deny to uploading and downloading harmful Android applications.
Robust X-ray Sparse-view Phase Tomography via Hierarchical Synthesis Convolutional Neural Networks
Jan 30, 2019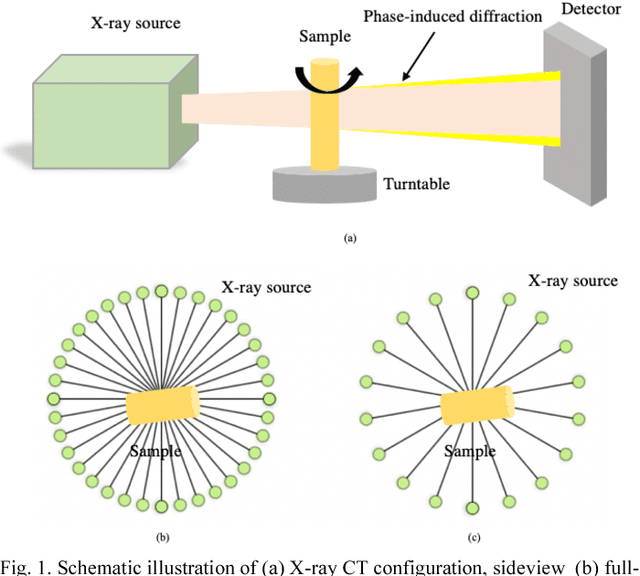
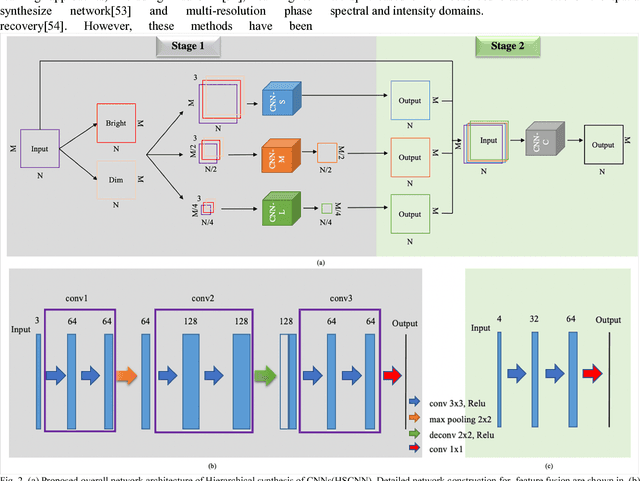


Convolutional Neural Networks (CNN) based image reconstruction methods have been intensely used for X-ray computed tomography (CT) reconstruction applications. Despite great success, good performance of this data-based approach critically relies on a representative big training data set and a dense convoluted deep network. The indiscriminating convolution connections over all dense layers could be prone to over-fitting, where sampling biases are wrongly integrated as features for the reconstruction. In this paper, we report a robust hierarchical synthesis reconstruction approach, where training data is pre-processed to separate the information on the domains where sampling biases are suspected. These split bands are then trained separately and combined successively through a hierarchical synthesis network. We apply the hierarchical synthesis reconstruction for two important and classical tomography reconstruction scenarios: the spares-view reconstruction and the phase reconstruction. Our simulated and experimental results show that comparable or improved performances are achieved with a dramatic reduction of network complexity and computational cost. This method can be generalized to a wide range of applications including material characterization, in-vivo monitoring and dynamic 4D imaging.
Local Uncertainty Sampling for Large-Scale Multi-Class Logistic Regression
Sep 13, 2018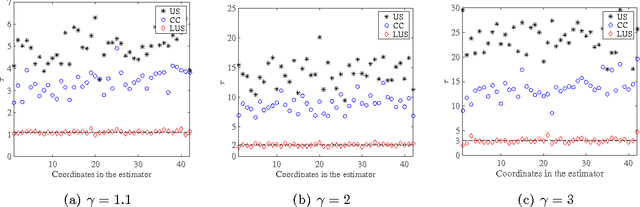

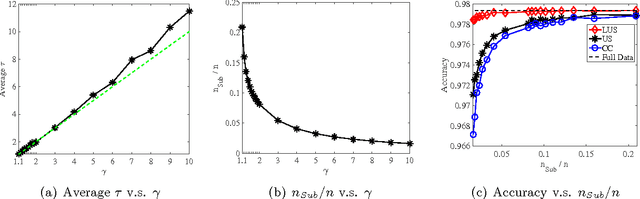
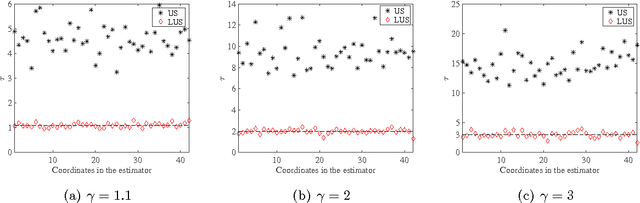
A major challenge for building statistical models in the big data era is that the available data volume far exceeds the computational capability. A common approach for solving this problem is to employ a subsampled dataset that can be handled by available computational resources. In this paper, we propose a general subsampling scheme for large-scale multi-class logistic regression and examine the variance of the resulting estimator. We show that asymptotically, the proposed method always achieves a smaller variance than that of the uniform random sampling. Moreover, when the classes are conditionally imbalanced, significant improvement over uniform sampling can be achieved. Empirical performance of the proposed method is compared to other methods on both simulated and real-world datasets, and these results match and confirm our theoretical analysis.