 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Data Attribution: Was Your Model Secretly Trained On Data Created By Mine?
Paper and Code
Sep 24, 2024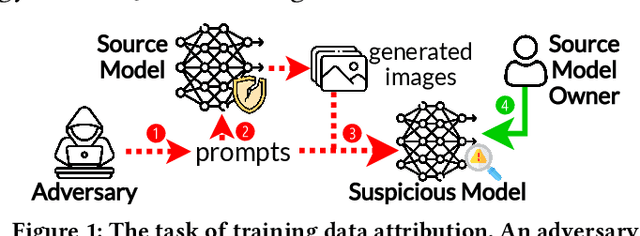
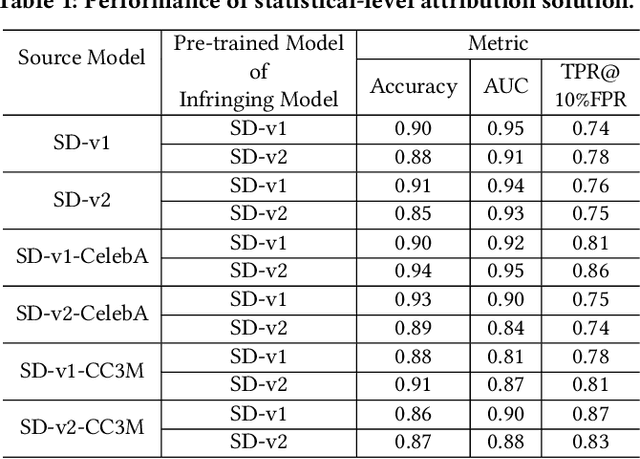

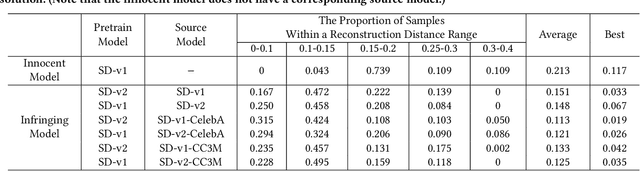
The emergence of text-to-image models has recently sparked significant interest, but the attendant is a looming shadow of potential infringement by violating the user terms. Specifically, an adversary may exploit data created by a commercial model to train their own without proper authorization. To address such risk, it is crucial to investigate the attribution of a suspicious model's training data by determining whether its training data originates, wholly or partially, from a specific source model. To trace the generated data, existing methods require applying extra watermarks during either the training or inference phases of the source model. However, these methods are impractical for pre-trained models that have been released, especially when model owners lack security expertise. To tackle this challenge, we propose an injection-free training data attribution method for text-to-image models. It can identify whether a suspicious model's training data stems from a source model, without additional modifications on the source model. The crux of our method lies in the inherent memorization characteristic of text-to-image models. Our core insight is that the memorization of the training dataset is passed down through the data generated by the source model to the model trained on that data, making the source model and the infringing model exhibit consistent behaviors on specific samples. Therefore, our approach involves developing algorithms to uncover these distinct samples and using them as inherent watermarks to verify if a suspicious model originates from the source model. Our experiments demonstrate that our method achieves an accuracy of over 80\% in identifying the source of a suspicious model's training data, without interfering the original training or generation process of the source model.