 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
Delving into Multi-modal Multi-task Foundation Models for Road Scene Understanding: From Learning Paradigm Perspectives
Feb 05, 2024



Foundation models have indeed made a profound impact on various fields, emerging as pivotal components that significantly shape the capabilities of intelligent systems. In the context of intelligent vehicles, leveraging the power of foundation models has proven to be transformative, offering notable advancements in visual understanding. Equipped with multi-modal and multi-task learning capabilities, multi-modal multi-task visual understanding foundation models (MM-VUFMs) effectively process and fuse data from diverse modalities and simultaneously handle various driving-related tasks with powerful adaptability, contributing to a more holistic understanding of the surrounding scene. In this survey, we present a systematic analysis of MM-VUFMs specifically designed for road scenes. Our objective is not only to provide a comprehensive overview of common practices, referring to task-specific models, unified multi-modal models, unified multi-task models, and foundation model prompting techniques, but also to highlight their advanced capabilities in diverse learning paradigms. These paradigms include open-world understanding, efficient transfer for road scenes, continual learning, interactive and generative capability. Moreover, we provide insights into key challenges and future trends, such as closed-loop driving systems, interpretability, embodied driving agents, and world models. To facilitate researchers in staying abreast of the latest developments in MM-VUFMs for road scenes, we have established a continuously updated repository at https://github.com/rolsheng/MM-VUFM4DS
Learning Better Features for Face Detection with Feature Fusion and Segmentation Supervision
Nov 20, 2018

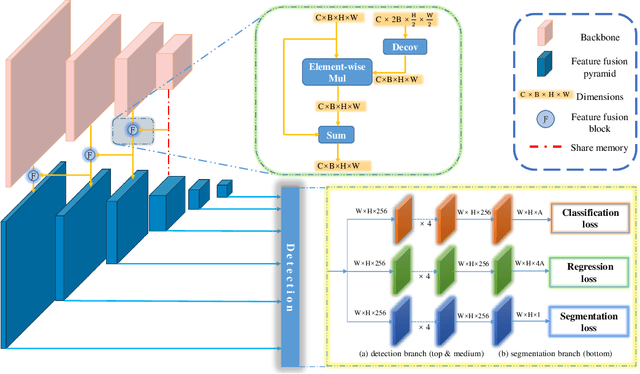
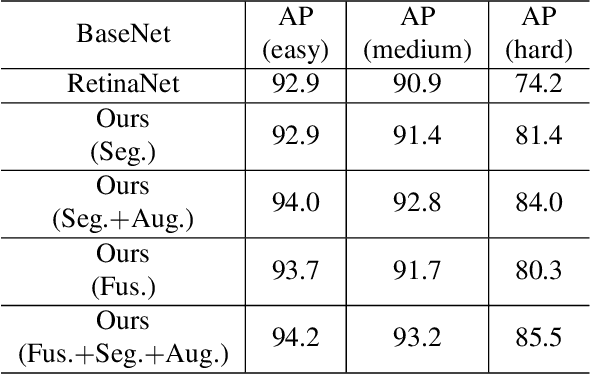
The performance of face detectors has been largely improved with the development of convolutional neural network. However, it remains challenging for face detectors to detect tiny, occluded or blurry faces. Besides, most face detectors can't locate face's position precisely and can't achieve high Intersection-over-Union (IoU) scores. We assume that problems inside are inadequate use of supervision information and imbalance between semantics and details at all level feature maps in CNN even with Feature Pyramid Networks (FPN). In this paper, we present a novel single-shot face detection network, named DF$^2$S$^2$ (Detection with Feature Fusion and Segmentation Supervision), which introduces a more effective feature fusion pyramid and a more efficient segmentation branch on ResNet-50 to handle mentioned problems. Specifically, inspired by FPN and SENet, we apply semantic information from higher-level feature maps as contextual cues to augment low-level feature maps via a spatial and channel-wise attention style, preventing details from being covered by too much semantics and making semantics and details complement each other. We further propose a semantic segmentation branch to best utilize detection supervision information meanwhile applying attention mechanism in a self-supervised manner. The segmentation branch is supervised by weak segmentation ground-truth (no extra annotation is required) in a hierarchical manner, deprecated in the inference time so it wouldn't compromise the inference speed. We evaluate our model on WIDER FACE dataset and achieved state-of-art results.