 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Better Features for Face Detection with Feature Fusion and Segmentation Supervision
Paper and Code
Nov 20, 2018

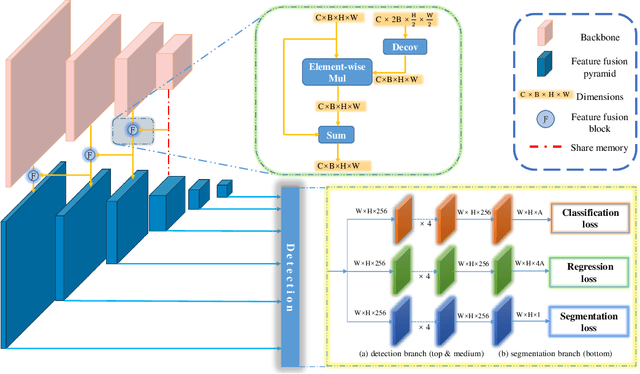
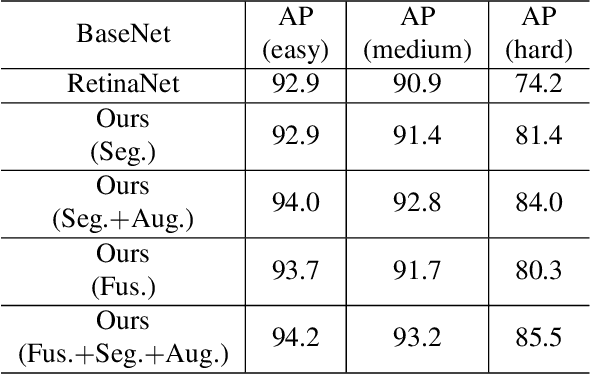
The performance of face detectors has been largely improved with the development of convolutional neural network. However, it remains challenging for face detectors to detect tiny, occluded or blurry faces. Besides, most face detectors can't locate face's position precisely and can't achieve high Intersection-over-Union (IoU) scores. We assume that problems inside are inadequate use of supervision information and imbalance between semantics and details at all level feature maps in CNN even with Feature Pyramid Networks (FPN). In this paper, we present a novel single-shot face detection network, named DF$^2$S$^2$ (Detection with Feature Fusion and Segmentation Supervision), which introduces a more effective feature fusion pyramid and a more efficient segmentation branch on ResNet-50 to handle mentioned problems. Specifically, inspired by FPN and SENet, we apply semantic information from higher-level feature maps as contextual cues to augment low-level feature maps via a spatial and channel-wise attention style, preventing details from being covered by too much semantics and making semantics and details complement each other. We further propose a semantic segmentation branch to best utilize detection supervision information meanwhile applying attention mechanism in a self-supervised manner. The segmentation branch is supervised by weak segmentation ground-truth (no extra annotation is required) in a hierarchical manner, deprecated in the inference time so it wouldn't compromise the inference speed. We evaluate our model on WIDER FACE dataset and achieved state-of-art results.