 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Trustworthy AI: Multi-Target Adversarial Attacks and Robust Defenses for Continuous Data Summarization
Jun 10, 2026Trustworthy AI requires reliable data-processing pipelines, not only robust downstream predictive models. As an upstream component, data summarization determines which information is retained and passed to subsequent learning or decision modules. Therefore, adversarial perturbations to the summarization process can compromise trustworthy AI in an upstream manner: they may alter the selected summary, reduce its representativeness, and further degrade the utility of subsequent learning tasks. In this paper, we study adversarial attacks on continuous data summarization under similarity-level perturbations through DR-submodular optimization. We show that a class of multi-resolution image summarization objectives can be formulated as multilinear extensions of non-negative submodular set functions and satisfy DR-submodularity with $m$-weak monotonicity. We then formulate multi-target attack generation as a min-max problem, where one admissible perturbation of the similarity structure is optimized to degrade multiple target summarization models. To mitigate such perturbations, we formulate robust defense against mixed attack types as a regularized max-min problem. For both problems, we develop approximation algorithms with theoretical guarantees. Experiments on real-data and controlled clustered benchmarks show that the proposed attack is effective in representative low-to-moderate budget regimes and can induce downstream task-performance loss. The proposed defense improves the robustness--mitigation trade-off in structured settings, while also revealing the parameter sensitivity of robust protection on real data.
AgentRAE: Remote Action Execution through Notification-based Visual Backdoors against Screenshots-based Mobile GUI Agents
Mar 24, 2026The rapid adoption of mobile graphical user interface (GUI) agents, which autonomously control applications and operating systems (OS), exposes new system-level attack surfaces. Existing backdoors against web GUI agents and general GenAI models rely on environmental injection or deceptive pop-ups to mislead the agent operation. However, these techniques do not work on screenshots-based mobile GUI agents due to the challenges of restricted trigger design spaces, OS background interference, and conflicts in multiple trigger-action mappings. We propose AgentRAE, a novel backdoor attack capable of inducing Remote Action Execution in mobile GUI agents using visually natural triggers (e.g., benign app icons in notifications). To address the underfitting caused by natural triggers and achieve accurate multi-target action redirection, we design a novel two-stage pipeline that first enhances the agent's sensitivity to subtle iconographic differences via contrastive learning, and then associates each trigger with a specific mobile GUI agent action through a backdoor post-training. Our extensive evaluation reveals that the proposed backdoor preserves clean performance with an attack success rate of over 90% across ten mobile operations. Furthermore, it is hard to visibly detect the benign-looking triggers and circumvents eight representative state-of-the-art defenses. These results expose an overlooked backdoor vector in mobile GUI agents, underscoring the need for defenses that scrutinize notification-conditioned behaviors and internal agent representations.
Approximation Algorithm for Constrained $k$-Center Clustering: A Local Search Approach
Jan 17, 2026Clustering is a long-standing research problem and a fundamental tool in AI and data analysis. The traditional k-center problem, a fundamental theoretical challenge in clustering, has a best possible approximation ratio of 2, and any improvement to a ratio of 2 - ε would imply P = NP. In this work, we study the constrained k-center clustering problem, where instance-level cannot-link (CL) and must-link (ML) constraints are incorporated as background knowledge. Although general CL constraints significantly increase the hardness of approximation, previous work has shown that disjoint CL sets permit constant-factor approximations. However, whether local search can achieve such a guarantee in this setting remains an open question. To this end, we propose a novel local search framework based on a transformation to a dominating matching set problem, achieving the best possible approximation ratio of 2. The experimental results on both real-world and synthetic datasets demonstrate that our algorithm outperforms baselines in solution quality.
Optimized Algorithms for Text Clustering with LLM-Generated Constraints
Jan 16, 2026Clustering is a fundamental tool that has garnered significant interest across a wide range of applications including text analysis. To improve clustering accuracy, many researchers have incorporated background knowledge, typically in the form of must-link and cannot-link constraints, to guide the clustering process. With the recent advent of large language models (LLMs), there is growing interest in improving clustering quality through LLM-based automatic constraint generation. In this paper, we propose a novel constraint-generation approach that reduces resource consumption by generating constraint sets rather than using traditional pairwise constraints. This approach improves both query efficiency and constraint accuracy compared to state-of-the-art methods. We further introduce a constrained clustering algorithm tailored to the characteristics of LLM-generated constraints. Our method incorporates a confidence threshold and a penalty mechanism to address potentially inaccurate constraints. We evaluate our approach on five text datasets, considering both the cost of constraint generation and the overall clustering performance. The results show that our method achieves clustering accuracy comparable to the state-of-the-art algorithms while reducing the number of LLM queries by more than 20 times.
Reconstruction of Differentially Private Text Sanitization via Large Language Models
Oct 16, 2024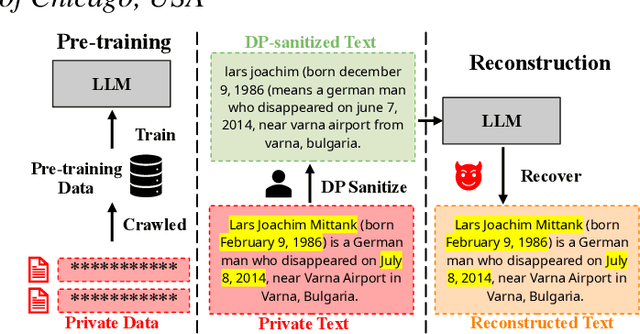
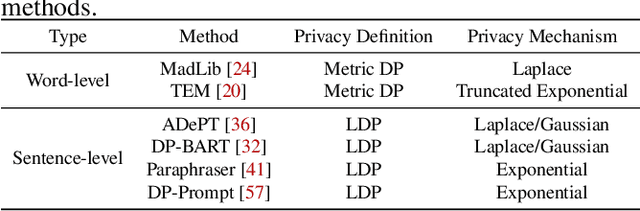

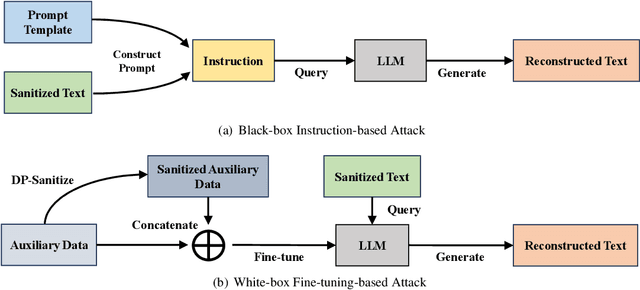
Differential privacy (DP) is the de facto privacy standard against privacy leakage attacks, including many recently discovered ones against large language models (LLMs). However, we discovered that LLMs could reconstruct the altered/removed privacy from given DP-sanitized prompts. We propose two attacks (black-box and white-box) based on the accessibility to LLMs and show that LLMs could connect the pair of DP-sanitized text and the corresponding private training data of LLMs by giving sample text pairs as instructions (in the black-box attacks) or fine-tuning data (in the white-box attacks). To illustrate our findings, we conduct comprehensive experiments on modern LLMs (e.g., LLaMA-2, LLaMA-3, ChatGPT-3.5, ChatGPT-4, ChatGPT-4o, Claude-3, Claude-3.5, OPT, GPT-Neo, GPT-J, Gemma-2, and Pythia) using commonly used datasets (such as WikiMIA, Pile-CC, and Pile-Wiki) against both word-level and sentence-level DP. The experimental results show promising recovery rates, e.g., the black-box attacks against the word-level DP over WikiMIA dataset gave 72.18% on LLaMA-2 (70B), 82.39% on LLaMA-3 (70B), 75.35% on Gemma-2, 91.2% on ChatGPT-4o, and 94.01% on Claude-3.5 (Sonnet). More urgently, this study indicates that these well-known LLMs have emerged as a new security risk for existing DP text sanitization approaches in the current environment.
Efficient Constrained $k$-Center Clustering with Background Knowledge
Jan 23, 2024



Center-based clustering has attracted significant research interest from both theory and practice. In many practical applications, input data often contain background knowledge that can be used to improve clustering results. In this work, we build on widely adopted $k$-center clustering and model its input background knowledge as must-link (ML) and cannot-link (CL) constraint sets. However, most clustering problems including $k$-center are inherently $\mathcal{NP}$-hard, while the more complex constrained variants are known to suffer severer approximation and computation barriers that significantly limit their applicability. By employing a suite of techniques including reverse dominating sets, linear programming (LP) integral polyhedron, and LP duality, we arrive at the first efficient approximation algorithm for constrained $k$-center with the best possible ratio of 2. We also construct competitive baseline algorithms and empirically evaluate our approximation algorithm against them on a variety of real datasets. The results validate our theoretical findings and demonstrate the great advantages of our algorithm in terms of clustering cost, clustering quality, and running time.
Practical, Private Assurance of the Value of Collaboration
Oct 04, 2023



Two parties wish to collaborate on their datasets. However, before they reveal their datasets to each other, the parties want to have the guarantee that the collaboration would be fruitful. We look at this problem from the point of view of machine learning, where one party is promised an improvement on its prediction model by incorporating data from the other party. The parties would only wish to collaborate further if the updated model shows an improvement in accuracy. Before this is ascertained, the two parties would not want to disclose their models and datasets. In this work, we construct an interactive protocol for this problem based on the fully homomorphic encryption scheme over the Torus (TFHE) and label differential privacy, where the underlying machine learning model is a neural network. Label differential privacy is used to ensure that computations are not done entirely in the encrypted domain, which is a significant bottleneck for neural network training according to the current state-of-the-art FHE implementations. We prove the security of our scheme in the universal composability framework assuming honest-but-curious parties, but where one party may not have any expertise in labelling its initial dataset. Experiments show that we can obtain the output, i.e., the accuracy of the updated model, with time many orders of magnitude faster than a protocol using entirely FHE operations.
A Differentially Private Framework for Deep Learning with Convexified Loss Functions
Apr 03, 2022

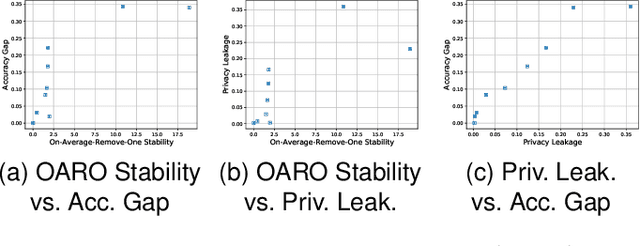
Differential privacy (DP) has been applied in deep learning for preserving privacy of the underlying training sets. Existing DP practice falls into three categories - objective perturbation, gradient perturbation and output perturbation. They suffer from three main problems. First, conditions on objective functions limit objective perturbation in general deep learning tasks. Second, gradient perturbation does not achieve a satisfactory privacy-utility trade-off due to over-injected noise in each epoch. Third, high utility of the output perturbation method is not guaranteed because of the loose upper bound on the global sensitivity of the trained model parameters as the noise scale parameter. To address these problems, we analyse a tighter upper bound on the global sensitivity of the model parameters. Under a black-box setting, based on this global sensitivity, to control the overall noise injection, we propose a novel output perturbation framework by injecting DP noise into a randomly sampled neuron (via the exponential mechanism) at the output layer of a baseline non-private neural network trained with a convexified loss function. We empirically compare the privacy-utility trade-off, measured by accuracy loss to baseline non-private models and the privacy leakage against black-box membership inference (MI) attacks, between our framework and the open-source differentially private stochastic gradient descent (DP-SGD) approaches on six commonly used real-world datasets. The experimental evaluations show that, when the baseline models have observable privacy leakage under MI attacks, our framework achieves a better privacy-utility trade-off than existing DP-SGD implementations, given an overall privacy budget $\epsilon \leq 1$ for a large number of queries.
Differentially Private k-Means Clustering with Guaranteed Convergence
Feb 03, 2020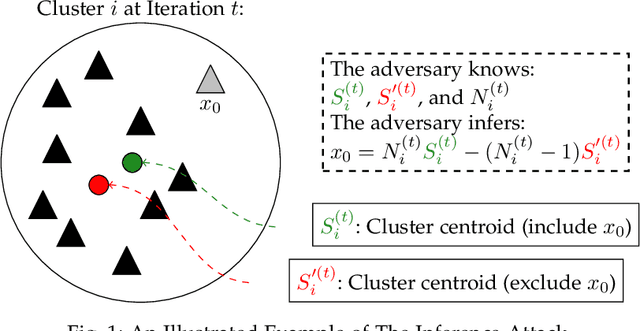
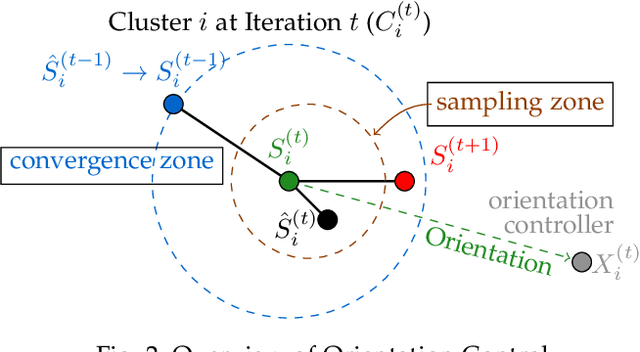

Iterative clustering algorithms help us to learn the insights behind the data. Unfortunately, this may allow adversaries to infer the privacy of individuals with some background knowledge. In the worst case, the adversaries know the centroids of an arbitrary iteration and the information of n-1 out of n items. To protect individual privacy against such an inference attack, preserving differential privacy (DP) for the iterative clustering algorithms has been extensively studied in the interactive settings. However, existing interactive differentially private clustering algorithms suffer from a non-convergence problem, i.e., these algorithms may not terminate without a predefined number of iterations. This problem severely impacts the clustering quality and the efficiency of a differentially private algorithm. To resolve this problem, in this paper, we propose a novel differentially private clustering framework in the interactive settings which controls the orientation of the movement of the centroids over the iterations to ensure the convergence by injecting DP noise in a selected area. We prove that, in the expected case, algorithm under our framework converges in at most twice the iterations of Lloyd's algorithm. We perform experimental evaluations on real-world datasets to show that our algorithm outperforms the state-of-the-art of the interactive differentially private clustering algorithms with guaranteed convergence and better clustering quality to meet the same DP requirement.