 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaCBM: An Adaptive Concept Bottleneck Model for Explainable and Accurate Diagnosis
Aug 04, 2024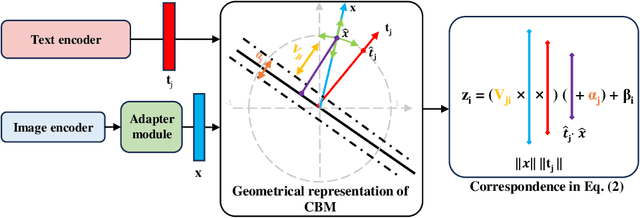
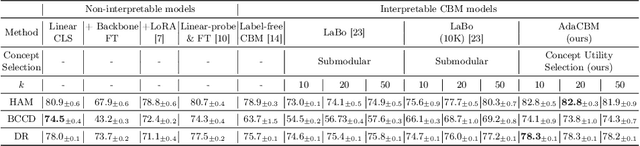

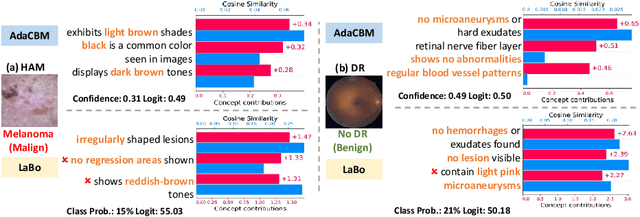
The integration of vision-language models such as CLIP and Concept Bottleneck Models (CBMs) offers a promising approach to explaining deep neural network (DNN) decisions using concepts understandable by humans, addressing the black-box concern of DNNs. While CLIP provides both explainability and zero-shot classification capability, its pre-training on generic image and text data may limit its classification accuracy and applicability to medical image diagnostic tasks, creating a transfer learning problem. To maintain explainability and address transfer learning needs, CBM methods commonly design post-processing modules after the bottleneck module. However, this way has been ineffective. This paper takes an unconventional approach by re-examining the CBM framework through the lens of its geometrical representation as a simple linear classification system. The analysis uncovers that post-CBM fine-tuning modules merely rescale and shift the classification outcome of the system, failing to fully leverage the system's learning potential. We introduce an adaptive module strategically positioned between CLIP and CBM to bridge the gap between source and downstream domains. This simple yet effective approach enhances classification performance while preserving the explainability afforded by the framework. Our work offers a comprehensive solution that encompasses the entire process, from concept discovery to model training, providing a holistic recipe for leveraging the strengths of GPT, CLIP, and CBM.
Zero-Shot Learning on 3D Point Cloud Objects and Beyond
Apr 11, 2021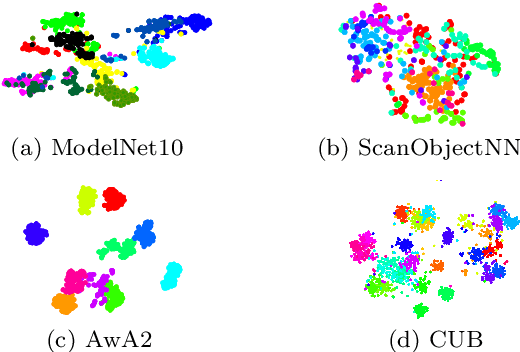
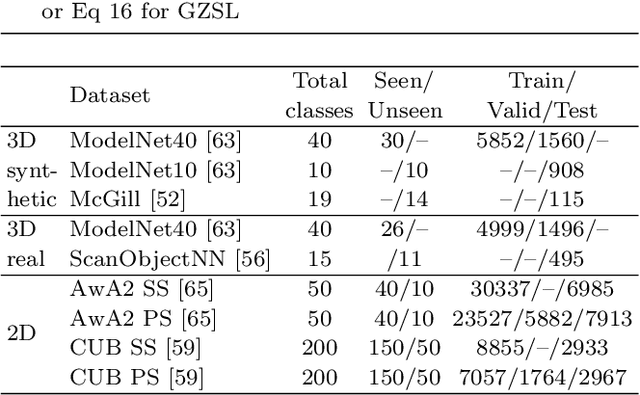
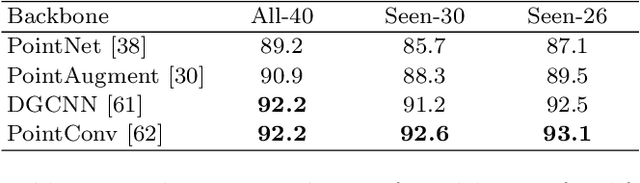
Zero-shot learning, the task of learning to recognize new classes not seen during training, has received considerable attention in the case of 2D image classification. However, despite the increasing ubiquity of 3D sensors, the corresponding 3D point cloud classification problem has not been meaningfully explored and introduces new challenges. In this paper, we identify some of the challenges and apply 2D Zero-Shot Learning (ZSL) methods in the 3D domain to analyze the performance of existing models. Then, we propose a novel approach to address the issues specific to 3D ZSL. We first present an inductive ZSL process and then extend it to the transductive ZSL and Generalized ZSL (GZSL) settings for 3D point cloud classification. To this end, a novel loss function is developed that simultaneously aligns seen semantics with point cloud features and takes advantage of unlabeled test data to address some known issues (e.g., the problems of domain adaptation, hubness, and data bias). While designed for the particularities of 3D point cloud classification, the method is shown to also be applicable to the more common use-case of 2D image classification. An extensive set of experiments is carried out, establishing state-of-the-art for ZSL and GZSL on synthetic (ModelNet40, ModelNet10, McGill) and real (ScanObjectNN) 3D point cloud datasets.