 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Spatial Relations in Images using Convolutional Neural Networks
Paper and Code
Jun 13, 2017

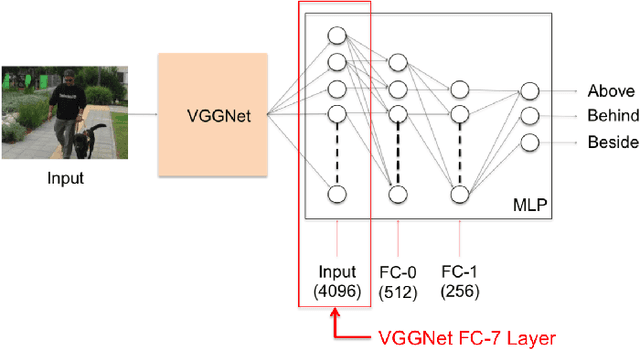
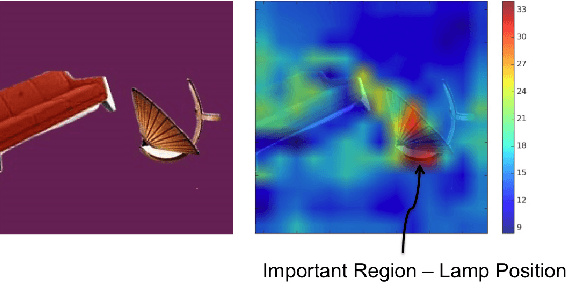
Traditional approaches to building a large scale knowledge graph have usually relied on extracting information (entities, their properties, and relations between them) from unstructured text (e.g. Dbpedia). Recent advances in Convolutional Neural Networks (CNN) allow us to shift our focus to learning entities and relations from images, as they build robust models that require little or no pre-processing of the images. In this paper, we present an approach to identify and extract spatial relations (e.g., The girl is standing behind the table) from images using CNNs. Our research addresses two specific challenges: providing insight into how spatial relations are learned by the network and which parts of the image are used to predict these relations. We use the pre-trained network VGGNet to extract features from an image and train a Multi-layer Perceptron (MLP) on a set of synthetic images and the sun09 dataset to extract spatial relations. The MLP predicts spatial relations without a bounding box around the objects or the space in the image depicting the relation. To understand how the spatial relations are represented in the network, a heatmap is overlayed on the image to show the regions that are deemed important by the network. Also, we analyze the MLP to show the relationship between the activation of consistent groups of nodes and the prediction of a spatial relation. We show how the loss of these groups affects the networks ability to identify relations.