 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Uncertainty for Improved Static Malware Detection Under Extreme False Positive Constraints
Paper and Code


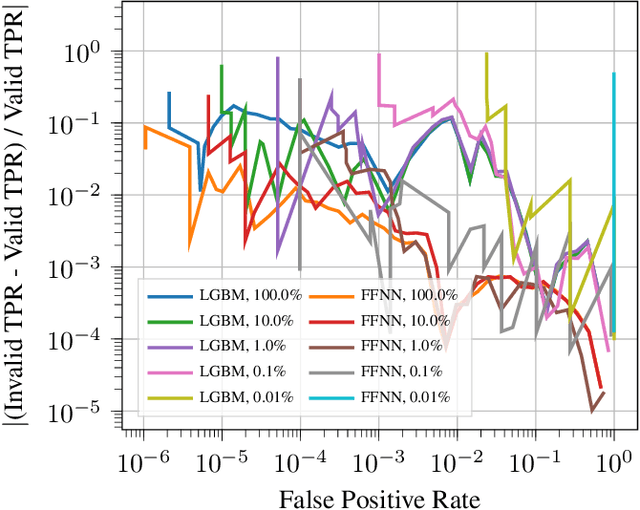
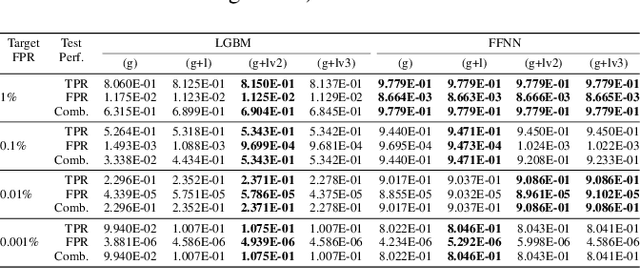
The detection of malware is a critical task for the protection of computing environments. This task often requires extremely low false positive rates (FPR) of 0.01% or even lower, for which modern machine learning has no readily available tools. We introduce the first broad investigation of the use of uncertainty for malware detection across multiple datasets, models, and feature types. We show how ensembling and Bayesian treatments of machine learning methods for static malware detection allow for improved identification of model errors, uncovering of new malware families, and predictive performance under extreme false positive constraints. In particular, we improve the true positive rate (TPR) at an actual realized FPR of 1e-5 from an expected 0.69 for previous methods to 0.80 on the best performing model class on the Sophos industry scale dataset. We additionally demonstrate how previous works have used an evaluation protocol that can lead to misleading results.