 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipf-Gramming: Scaling Byte N-Grams Up to Production Sized Malware Corpora
Nov 17, 2025A classifier using byte n-grams as features is the only approach we have found fast enough to meet requirements in size (sub 2 MB), speed (multiple GB/s), and latency (sub 10 ms) for deployment in numerous malware detection scenarios. However, we've consistently found that 6-8 grams achieve the best accuracy on our production deployments but have been unable to deploy regularly updated models due to the high cost of finding the top-k most frequent n-grams over terabytes of executable programs. Because the Zipfian distribution well models the distribution of n-grams, we exploit its properties to develop a new top-k n-gram extractor that is up to $35\times$ faster than the previous best alternative. Using our new Zipf-Gramming algorithm, we are able to scale up our production training set and obtain up to 30\% improvement in AUC at detecting new malware. We show theoretically and empirically that our approach will select the top-k items with little error and the interplay between theory and engineering required to achieve these results.
* Published in CIKM 2025
Quick-Draw Bandits: Quickly Optimizing in Nonstationary Environments with Extremely Many Arms
May 30, 2025Canonical algorithms for multi-armed bandits typically assume a stationary reward environment where the size of the action space (number of arms) is small. More recently developed methods typically relax only one of these assumptions: existing non-stationary bandit policies are designed for a small number of arms, while Lipschitz, linear, and Gaussian process bandit policies are designed to handle a large (or infinite) number of arms in stationary reward environments under constraints on the reward function. In this manuscript, we propose a novel policy to learn reward environments over a continuous space using Gaussian interpolation. We show that our method efficiently learns continuous Lipschitz reward functions with $\mathcal{O}^*(\sqrt{T})$ cumulative regret. Furthermore, our method naturally extends to non-stationary problems with a simple modification. We finally demonstrate that our method is computationally favorable (100-10000x faster) and experimentally outperforms sliding Gaussian process policies on datasets with non-stationarity and an extremely large number of arms.
Stop Walking in Circles! Bailing Out Early in Projected Gradient Descent
Mar 25, 2025
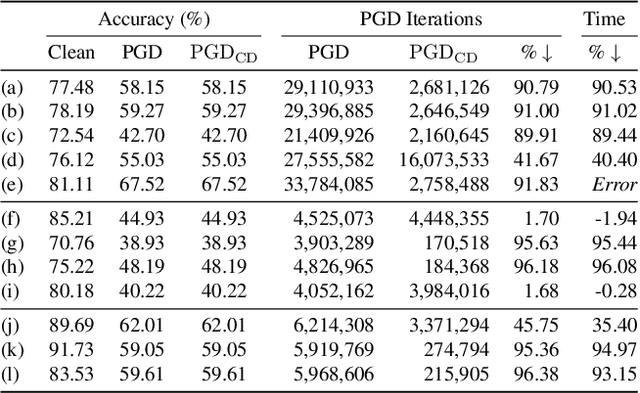


Projected Gradient Descent (PGD) under the $L_\infty$ ball has become one of the defacto methods used in adversarial robustness evaluation for computer vision (CV) due to its reliability and efficacy, making a strong and easy-to-implement iterative baseline. However, PGD is computationally demanding to apply, especially when using thousands of iterations is the current best-practice recommendation to generate an adversarial example for a single image. In this work, we introduce a simple novel method for early termination of PGD based on cycle detection by exploiting the geometry of how PGD is implemented in practice and show that it can produce large speedup factors while providing the \emph{exact} same estimate of model robustness as standard PGD. This method substantially speeds up PGD without sacrificing any attack strength, enabling evaluations of robustness that were previously computationally intractable.
Multi-layer Radial Basis Function Networks for Out-of-distribution Detection
Jan 05, 2025



Existing methods for out-of-distribution (OOD) detection use various techniques to produce a score, separate from classification, that determines how ``OOD'' an input is. Our insight is that OOD detection can be simplified by using a neural network architecture which can effectively merge classification and OOD detection into a single step. Radial basis function networks (RBFNs) inherently link classification confidence and OOD detection; however, these networks have lost popularity due to the difficult of training them in a multi-layer fashion. In this work, we develop a multi-layer radial basis function network (MLRBFN) which can be easily trained. To ensure that these networks are also effective for OOD detection, we develop a novel depression mechanism. We apply MLRBFNs as standalone classifiers and as heads on top of pretrained feature extractors, and find that they are competitive with commonly used methods for OOD detection. Our MLRBFN architecture demonstrates a promising new direction for OOD detection methods.
Improving Out-of-Distribution Detection via Epistemic Uncertainty Adversarial Training
Sep 09, 2022
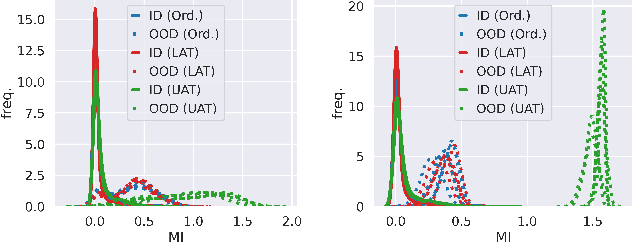
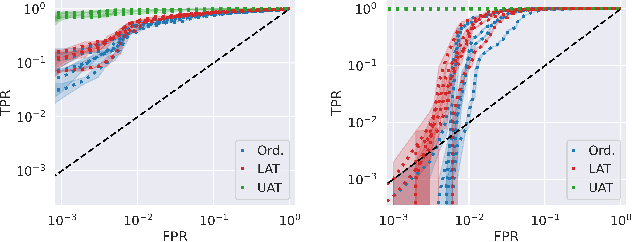
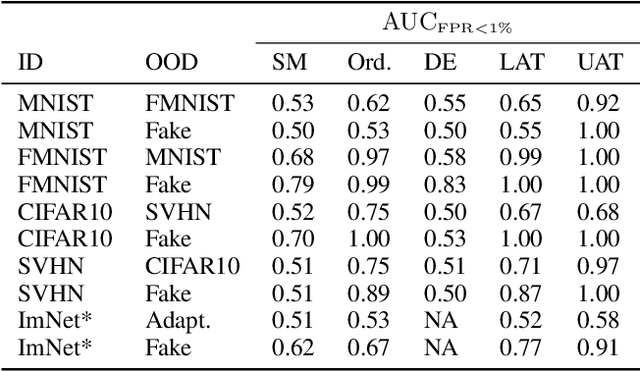
The quantification of uncertainty is important for the adoption of machine learning, especially to reject out-of-distribution (OOD) data back to human experts for review. Yet progress has been slow, as a balance must be struck between computational efficiency and the quality of uncertainty estimates. For this reason many use deep ensembles of neural networks or Monte Carlo dropout for reasonable uncertainty estimates at relatively minimal compute and memory. Surprisingly, when we focus on the real-world applicable constraint of $\leq 1\%$ false positive rate (FPR), prior methods fail to reliably detect OOD samples as such. Notably, even Gaussian random noise fails to trigger these popular OOD techniques. We help to alleviate this problem by devising a simple adversarial training scheme that incorporates an attack of the epistemic uncertainty predicted by the dropout ensemble. We demonstrate this method improves OOD detection performance on standard data (i.e., not adversarially crafted), and improves the standardized partial AUC from near-random guessing performance to $\geq 0.75$.