 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMG-Det: Foundation Model Guided Robust Object Detection
May 29, 2025

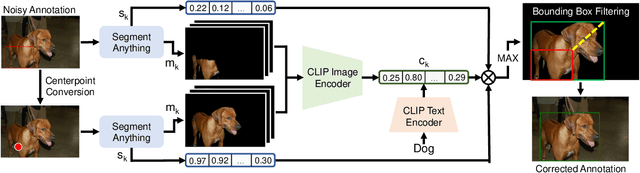

Collecting high quality data for object detection tasks is challenging due to the inherent subjectivity in labeling the boundaries of an object. This makes it difficult to not only collect consistent annotations across a dataset but also to validate them, as no two annotators are likely to label the same object using the exact same coordinates. These challenges are further compounded when object boundaries are partially visible or blurred, which can be the case in many domains. Training on noisy annotations significantly degrades detector performance, rendering them unusable, particularly in few-shot settings, where just a few corrupted annotations can impact model performance. In this work, we propose FMG-Det, a simple, efficient methodology for training models with noisy annotations. More specifically, we propose combining a multiple instance learning (MIL) framework with a pre-processing pipeline that leverages powerful foundation models to correct labels prior to training. This pre-processing pipeline, along with slight modifications to the detector head, results in state-of-the-art performance across a number of datasets, for both standard and few-shot scenarios, while being much simpler and more efficient than other approaches.
ColMix -- A Simple Data Augmentation Framework to Improve Object Detector Performance and Robustness in Aerial Images
May 22, 2023In the last decade, Convolutional Neural Network (CNN) and transformer based object detectors have achieved high performance on a large variety of datasets. Though the majority of detection literature has developed this capability on datasets such as MS COCO, these detectors have still proven effective for remote sensing applications. Challenges in this particular domain, such as small numbers of annotated objects and low object density, hinder overall performance. In this work, we present a novel augmentation method, called collage pasting, for increasing the object density without a need for segmentation masks, thereby improving the detector performance. We demonstrate that collage pasting improves precision and recall beyond related methods, such as mosaic augmentation, and enables greater control of object density. However, we find that collage pasting is vulnerable to certain out-of-distribution shifts, such as image corruptions. To address this, we introduce two simple approaches for combining collage pasting with PixMix augmentation method, and refer to our combined techniques as ColMix. Through extensive experiments, we show that employing ColMix results in detectors with superior performance on aerial imagery datasets and robust to various corruptions.
Reward-Free Attacks in Multi-Agent Reinforcement Learning
Dec 02, 2021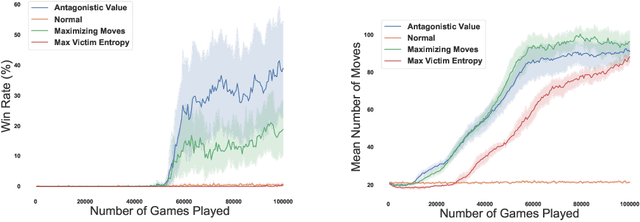

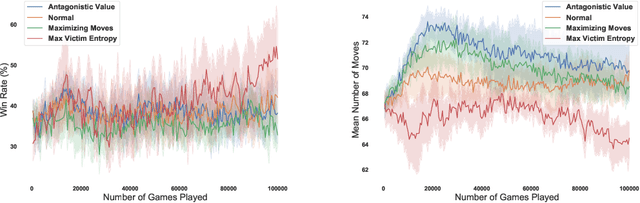

We investigate how effective an attacker can be when it only learns from its victim's actions, without access to the victim's reward. In this work, we are motivated by the scenario where the attacker wants to behave strategically when the victim's motivations are unknown. We argue that one heuristic approach an attacker can use is to maximize the entropy of the victim's policy. The policy is generally not obfuscated, which implies it may be extracted simply by passively observing the victim. We provide such a strategy in the form of a reward-free exploration algorithm that maximizes the attacker's entropy during the exploration phase, and then maximizes the victim's empirical entropy during the planning phase. In our experiments, the victim agents are subverted through policy entropy maximization, implying an attacker might not need access to the victim's reward to succeed. Hence, reward-free attacks, which are based only on observing behavior, show the feasibility of an attacker to act strategically without knowledge of the victim's motives even if the victim's reward information is protected.