 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalous Motion Detection on Highway Using Deep Learning
Jun 15, 2020



Research in visual anomaly detection draws much interest due to its applications in surveillance. Common datasets for evaluation are constructed using a stationary camera overlooking a region of interest. Previous research has shown promising results in detecting spatial as well as temporal anomalies in these settings. The advent of self-driving cars provides an opportunity to apply visual anomaly detection in a more dynamic application yet no dataset exists in this type of environment. This paper presents a new anomaly detection dataset - the Highway Traffic Anomaly (HTA) dataset - for the problem of detecting anomalous traffic patterns from dash cam videos of vehicles on highways. We evaluate state-of-the-art deep learning anomaly detection models and propose novel variations to these methods. Our results show that state-of-the-art models built for settings with a stationary camera do not translate well to a more dynamic environment. The proposed variations to these SoTA methods show promising results on the new HTA dataset.
Attributes for Improved Attributes: A Multi-Task Network for Attribute Classification
Apr 25, 2016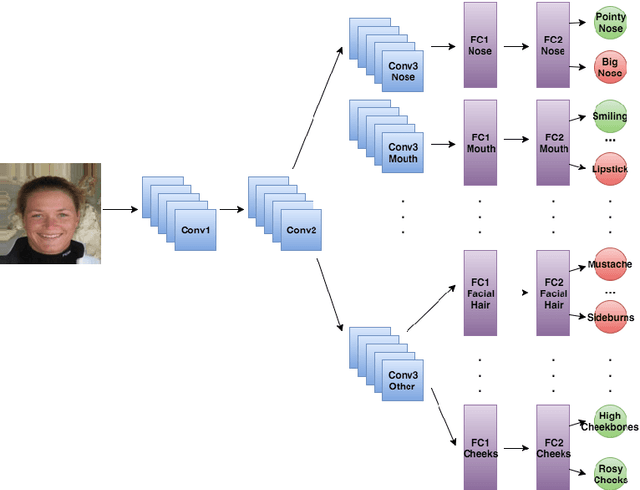


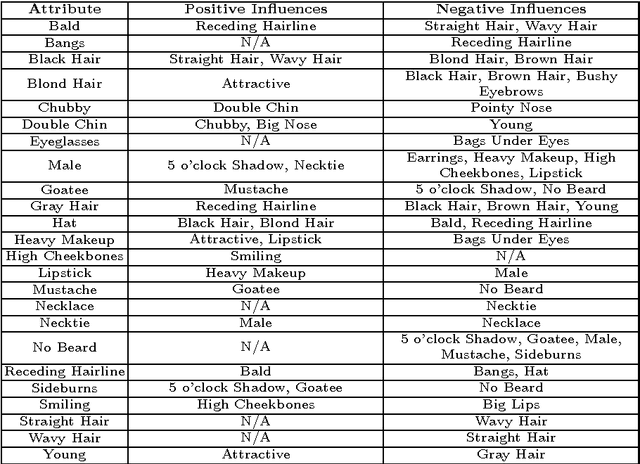
Attributes, or semantic features, have gained popularity in the past few years in domains ranging from activity recognition in video to face verification. Improving the accuracy of attribute classifiers is an important first step in any application which uses these attributes. In most works to date, attributes have been considered to be independent. However, we know this not to be the case. Many attributes are very strongly related, such as heavy makeup and wearing lipstick. We propose to take advantage of attribute relationships in three ways: by using a multi-task deep convolutional neural network (MCNN) sharing the lowest layers amongst all attributes, sharing the higher layers for related attributes, and by building an auxiliary network on top of the MCNN which utilizes the scores from all attributes to improve the final classification of each attribute. We demonstrate the effectiveness of our method by producing results on two challenging publicly available datasets.
Gradual DropIn of Layers to Train Very Deep Neural Networks
Nov 22, 2015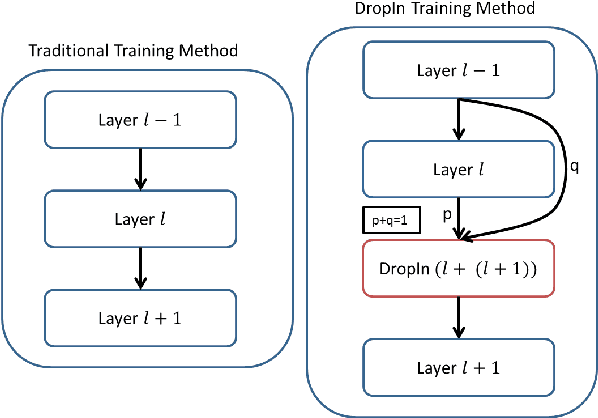

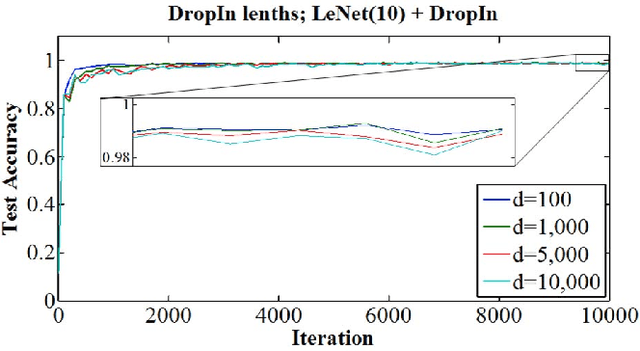
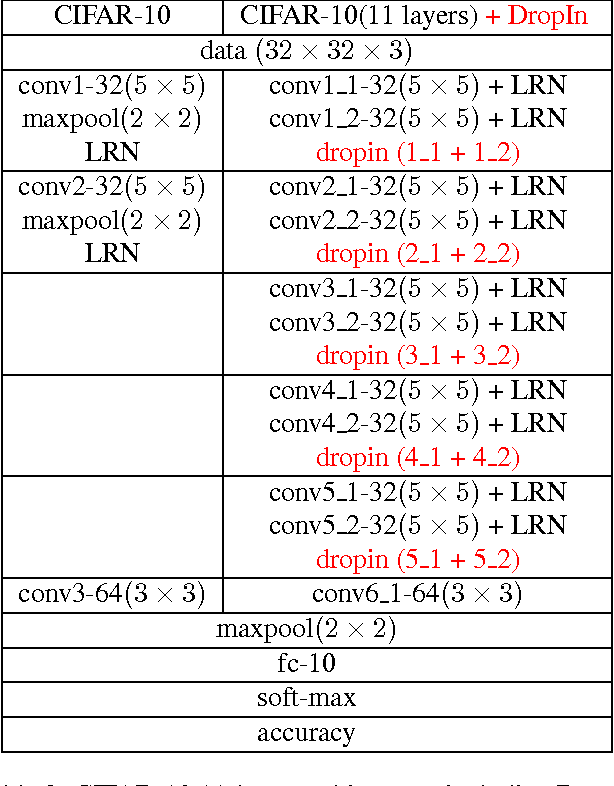
We introduce the concept of dynamically growing a neural network during training. In particular, an untrainable deep network starts as a trainable shallow network and newly added layers are slowly, organically added during training, thereby increasing the network's depth. This is accomplished by a new layer, which we call DropIn. The DropIn layer starts by passing the output from a previous layer (effectively skipping over the newly added layers), then increasingly including units from the new layers for both feedforward and backpropagation. We show that deep networks, which are untrainable with conventional methods, will converge with DropIn layers interspersed in the architecture. In addition, we demonstrate that DropIn provides regularization during training in an analogous way as dropout. Experiments are described with the MNIST dataset and various expanded LeNet architectures, CIFAR-10 dataset with its architecture expanded from 3 to 11 layers, and on the ImageNet dataset with the AlexNet architecture expanded to 13 layers and the VGG 16-layer architecture.