 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Policy Selection and Fine-Tuning under Interaction Budgets for Offline-to-Online Reinforcement Learning
May 06, 2026In offline-to-online reinforcement learning (O2O-RL), policies are first safely trained offline using previously collected datasets and then further fine-tuned for tasks via limited online interactions. In a typical O2O-RL pipeline, candidate policies trained with offline RL are evaluated via either off-policy evaluation (OPE) or online evaluation (OE). The policy with the highest estimated value is then deployed and continually fine-tuned. However, this setup has two main issues. First, OPE can be unreliable, making it risky to deploy a policy based solely on those estimates, whereas OE may identify a viable policy with substantial online interaction, which could have been used for fine-tuning. Second--and more importantly--it is also often not possible to determine a priori whether a pretrained policy will improve with post-deployment fine-tuning, especially in non-stationary environments. As a result, procedures committing to a single deployed policy are impractical in many real-world settings. Moreover, a naive remedy that exhaustively fine-tunes all candidates would violate interaction budget constraints and is likewise infeasible. In this paper, we propose a novel adaptive approach for policy selection and fine-tuning under online interaction budgets in O2O-RL. Following the standard pipeline, we first train a set of candidate policies with different offline RL algorithms and hyperparameters; we then perform OPE to obtain initial performance estimates. We next adaptively select and fine-tune the policies based on their predicted performance via an upper-confidence-bound approach thereby making efficient use of online interactions. We demonstrate that our approach improves upon O2O-RL baselines with various benchmarks.
Neuro-Logic Lifelong Learning
Nov 16, 2025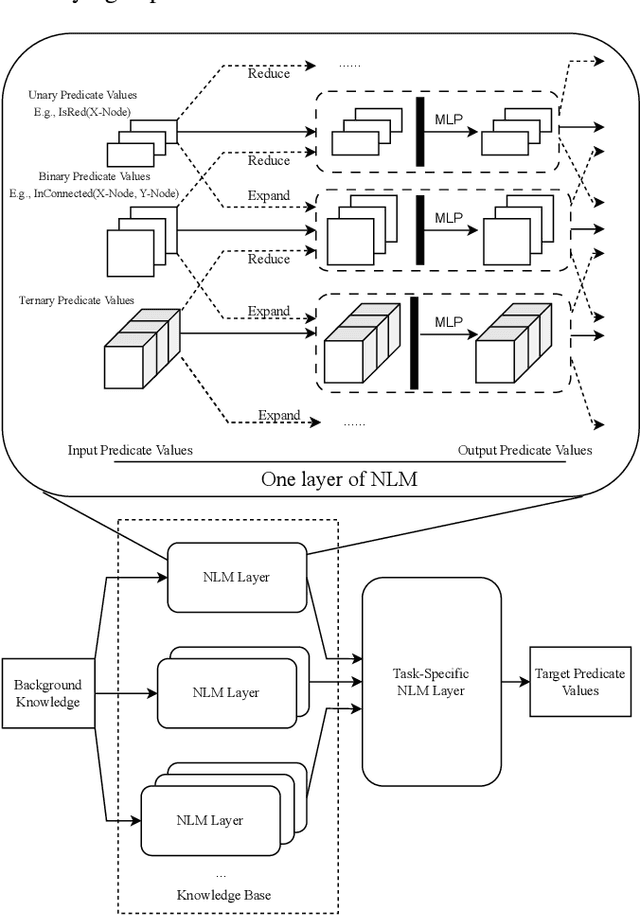
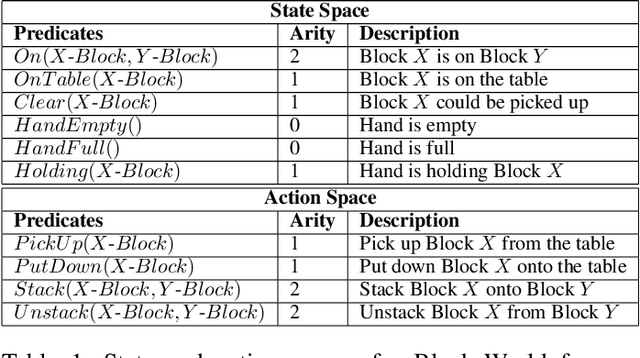
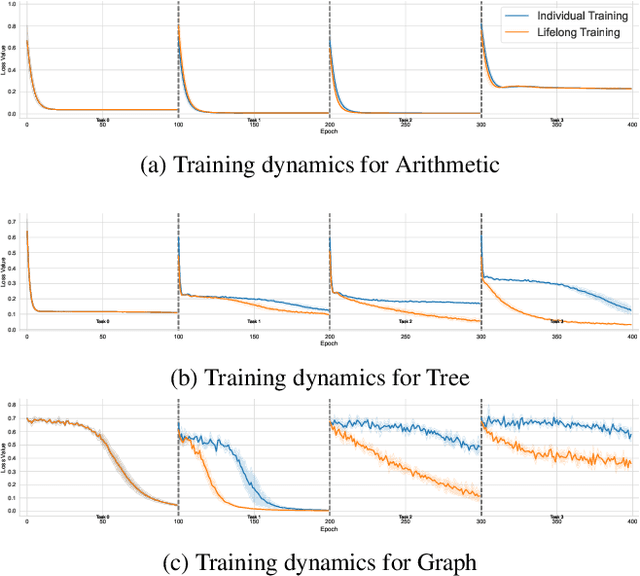
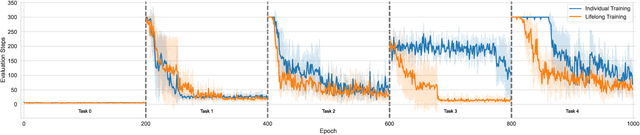
Solving Inductive Logic Programming (ILP) problems with neural networks is a key challenge in Neural-Symbolic Ar- tificial Intelligence (AI). While most research has focused on designing novel network architectures for individual prob- lems, less effort has been devoted to exploring new learning paradigms involving a sequence of problems. In this work, we investigate lifelong learning ILP, which leverages the com- positional and transferable nature of logic rules for efficient learning of new problems. We introduce a compositional framework, demonstrating how logic rules acquired from ear- lier tasks can be efficiently reused in subsequent ones, leading to improved scalability and performance. We formalize our approach and empirically evaluate it on sequences of tasks. Experimental results validate the feasibility and advantages of this paradigm, opening new directions for continual learn- ing in Neural-Symbolic AI.
On the Uniqueness of Solution for the Bellman Equation of LTL Objectives
Apr 07, 2024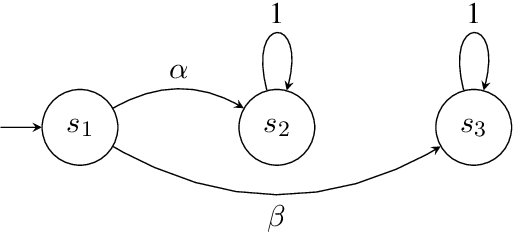
Surrogate rewards for linear temporal logic (LTL) objectives are commonly utilized in planning problems for LTL objectives. In a widely-adopted surrogate reward approach, two discount factors are used to ensure that the expected return approximates the satisfaction probability of the LTL objective. The expected return then can be estimated by methods using the Bellman updates such as reinforcement learning. However, the uniqueness of the solution to the Bellman equation with two discount factors has not been explicitly discussed. We demonstrate with an example that when one of the discount factors is set to one, as allowed in many previous works, the Bellman equation may have multiple solutions, leading to inaccurate evaluation of the expected return. We then propose a condition for the Bellman equation to have the expected return as the unique solution, requiring the solutions for states inside a rejecting bottom strongly connected component (BSCC) to be 0. We prove this condition is sufficient by showing that the solutions for the states with discounting can be separated from those for the states without discounting under this condition
Reinforcement Learning with Temporal Logic Constraints for Partially-Observable Markov Decision Processes
Apr 04, 2021
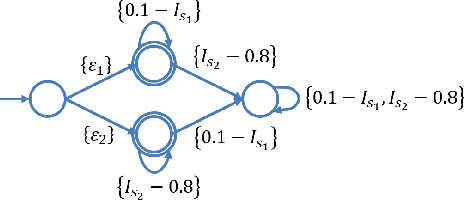
This paper proposes a reinforcement learning method for controller synthesis of autonomous systems in unknown and partially-observable environments with subjective time-dependent safety constraints. Mathematically, we model the system dynamics by a partially-observable Markov decision process (POMDP) with unknown transition/observation probabilities. The time-dependent safety constraint is captured by iLTL, a variation of linear temporal logic for state distributions. Our Reinforcement learning method first constructs the belief MDP of the POMDP, capturing the time evolution of estimated state distributions. Then, by building the product belief MDP of the belief MDP and the limiting deterministic B\uchi automaton (LDBA) of the temporal logic constraint, we transform the time-dependent safety constraint on the POMDP into a state-dependent constraint on the product belief MDP. Finally, we learn the optimal policy by value iteration under the state-dependent constraint.
Model-Free Learning of Safe yet Effective Controllers
Mar 26, 2021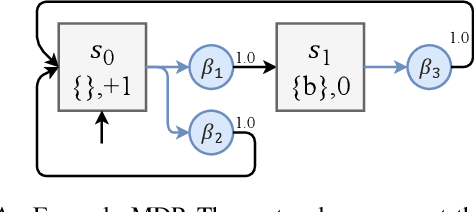
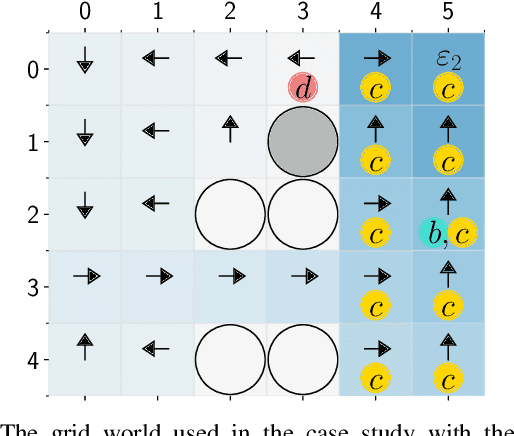
In this paper, we study the problem of learning safe control policies that are also effective -- i.e., maximizing the probability of satisfying the linear temporal logic (LTL) specification of the task, and the discounted reward capturing the (classic) control performance. We consider unknown environments that can be modeled as Markov decision processes (MDPs). We propose a model-free reinforcement learning algorithm that learns a policy that first maximizes the probability of ensuring the safety, then the probability of satisfying the given LTL specification and lastly, the sum of discounted Quality of Control (QoC) rewards. Finally, we illustrate the applicability of our RL-based approach on a case study.
Learning Optimal Strategies for Temporal Tasks in Stochastic Games
Feb 08, 2021
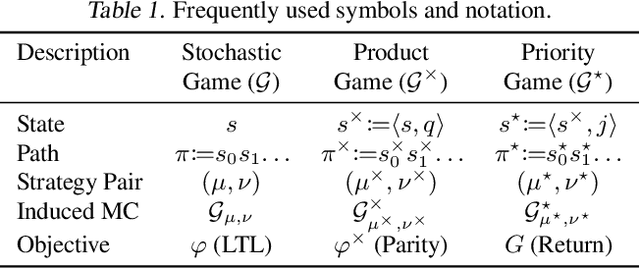
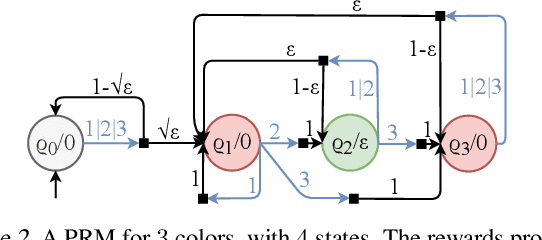
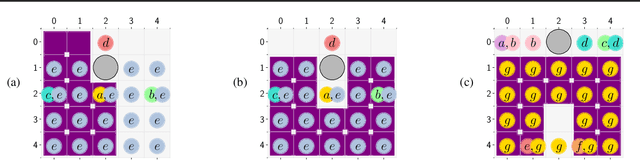
Linear temporal logic (LTL) is widely used to formally specify complex tasks for autonomy. Unlike usual tasks defined by reward functions only, LTL tasks are noncumulative and require memory-dependent strategies. In this work, we introduce a method to learn optimal controller strategies that maximize the satisfaction probability of LTL specifications of the desired tasks in stochastic games, which are natural extensions of Markov Decision Processes (MDPs) to systems with adversarial inputs. Our approach constructs a product game using the deterministic automaton derived from the given LTL task and a reward machine based on the acceptance condition of the automaton; thus, allowing for the use of a model-free RL algorithm to learn an optimal controller strategy. Since the rewards and the transition probabilities of the reward machine do not depend on the number of sets defining the acceptance condition, our approach is scalable to a wide range of LTL tasks, as we demonstrate on several case studies.
Secure Planning Against Stealthy Attacks via Model-Free Reinforcement Learning
Nov 03, 2020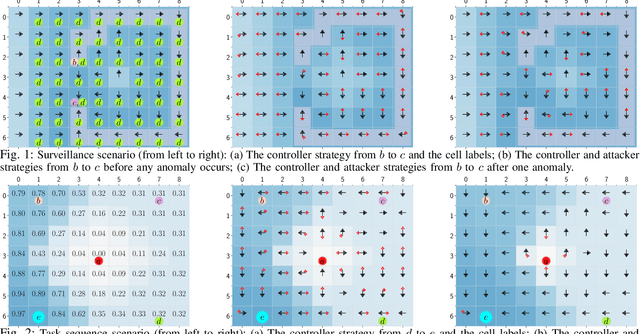
We consider the problem of security-aware planning in an unknown stochastic environment, in the presence of attacks on control signals (i.e., actuators) of the robot. We model the attacker as an agent who has the full knowledge of the controller as well as the employed intrusion-detection system and who wants to prevent the controller from performing tasks while staying stealthy. We formulate the problem as a stochastic game between the attacker and the controller and present an approach to express the objective of such an agent and the controller as a combined linear temporal logic (LTL) formula. We then show that the planning problem, described formally as the problem of satisfying an LTL formula in a stochastic game, can be solved via model-free reinforcement learning when the environment is completely unknown. Finally, we illustrate and evaluate our methods on two robotic planning case studies.
Model-Free Reinforcement Learning for Stochastic Games with Linear Temporal Logic Objectives
Oct 02, 2020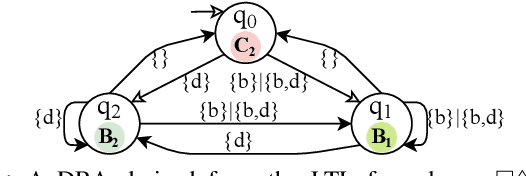
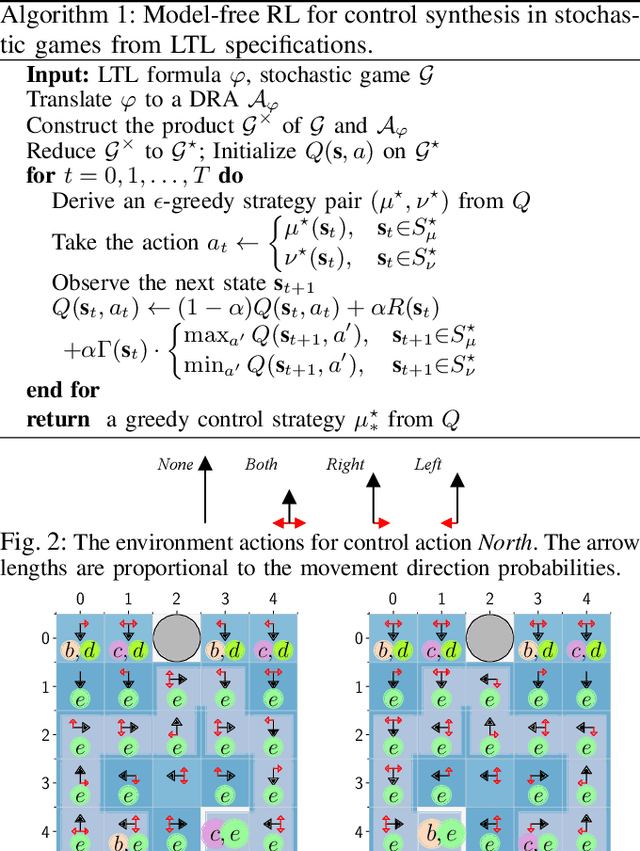
We study the problem of synthesizing control strategies for Linear Temporal Logic (LTL) objectives in unknown environments. We model this problem as a turn-based zero-sum stochastic game between the controller and the environment, where the transition probabilities and the model topology are fully unknown. The winning condition for the controller in this game is the satisfaction of the given LTL specification, which can be captured by the acceptance condition of a deterministic Rabin automaton (DRA) directly derived from the LTL specification. We introduce a model-free reinforcement learning (RL) methodology to find a strategy that maximizes the probability of satisfying a given LTL specification when the Rabin condition of the derived DRA has a single accepting pair. We then generalize this approach to LTL formulas for which the Rabin condition has a larger number of accepting pairs, providing a lower bound on the satisfaction probability. Finally, we illustrate applicability of our RL method on two motion planning case studies.
Control Synthesis from Linear Temporal Logic Specifications using Model-Free Reinforcement Learning
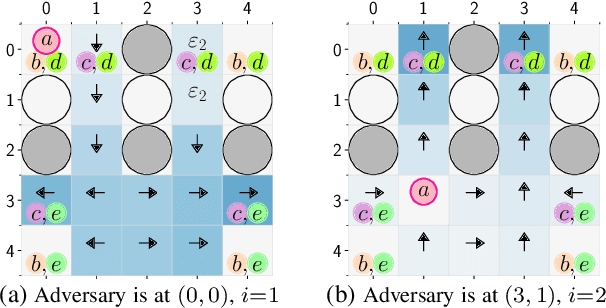
Sep 16, 2019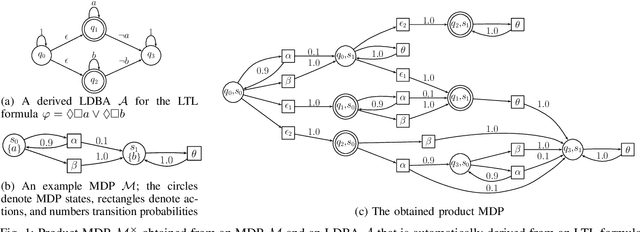

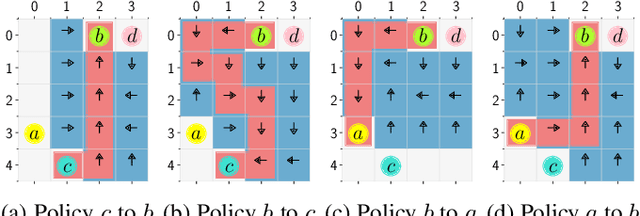
We present a reinforcement learning (RL) framework to synthesize a control policy from a given linear temporal logic (LTL) specification in an unknown stochastic environment that can be modeled as a Markov Decision Process (MDP). Specifically, we learn a policy that maximizes the probability of satisfying the LTL formula without learning the transition probabilities. We introduce a novel rewarding and path-dependent discounting mechanism based on the LTL formula such that (i) an optimal policy maximizing the total discounted reward effectively maximizes the probabilities of satisfying LTL objectives, and (ii) a model-free RL algorithm using these rewards and discount factors is guaranteed to converge to such policy. Finally, we illustrate the applicability of our RL-based synthesis approach on two motion planning case studies.