 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl Synthesis from Linear Temporal Logic Specifications using Model-Free Reinforcement Learning
Paper and Code
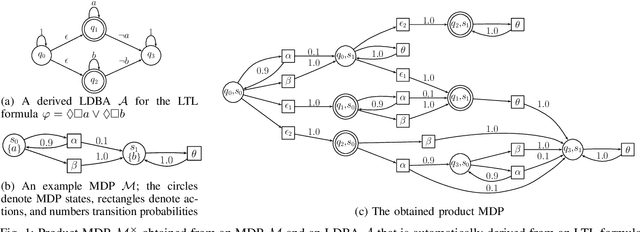

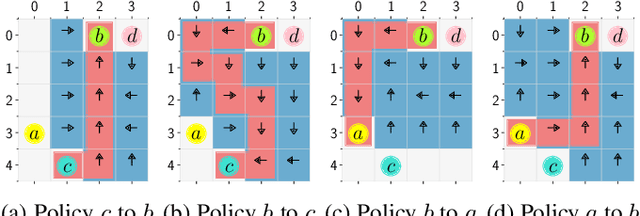
We present a reinforcement learning (RL) framework to synthesize a control policy from a given linear temporal logic (LTL) specification in an unknown stochastic environment that can be modeled as a Markov Decision Process (MDP). Specifically, we learn a policy that maximizes the probability of satisfying the LTL formula without learning the transition probabilities. We introduce a novel rewarding and path-dependent discounting mechanism based on the LTL formula such that (i) an optimal policy maximizing the total discounted reward effectively maximizes the probabilities of satisfying LTL objectives, and (ii) a model-free RL algorithm using these rewards and discount factors is guaranteed to converge to such policy. Finally, we illustrate the applicability of our RL-based synthesis approach on two motion planning case studies.