 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Optimal Strategies for Temporal Tasks in Stochastic Games
Paper and Code
Feb 08, 2021
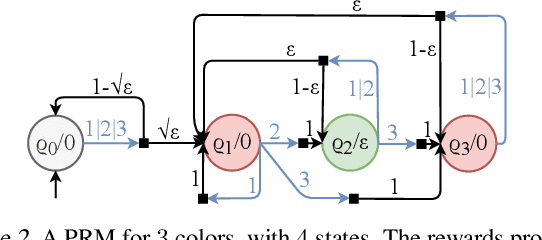
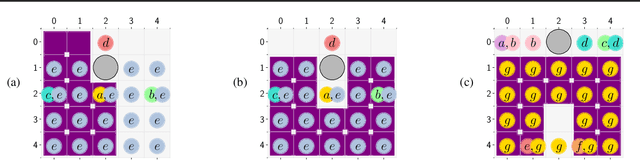
Linear temporal logic (LTL) is widely used to formally specify complex tasks for autonomy. Unlike usual tasks defined by reward functions only, LTL tasks are noncumulative and require memory-dependent strategies. In this work, we introduce a method to learn optimal controller strategies that maximize the satisfaction probability of LTL specifications of the desired tasks in stochastic games, which are natural extensions of Markov Decision Processes (MDPs) to systems with adversarial inputs. Our approach constructs a product game using the deterministic automaton derived from the given LTL task and a reward machine based on the acceptance condition of the automaton; thus, allowing for the use of a model-free RL algorithm to learn an optimal controller strategy. Since the rewards and the transition probabilities of the reward machine do not depend on the number of sets defining the acceptance condition, our approach is scalable to a wide range of LTL tasks, as we demonstrate on several case studies.