 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence Guarantee of Dynamic Programming for LTL Surrogate Reward
Aug 10, 2024Linear Temporal Logic (LTL) is a formal way of specifying complex objectives for planning problems modeled as Markov Decision Processes (MDPs). The planning problem aims to find the optimal policy that maximizes the satisfaction probability of the LTL objective. One way to solve the planning problem is to use the surrogate reward with two discount factors and dynamic programming, which bypasses the graph analysis used in traditional model-checking. The surrogate reward is designed such that its value function represents the satisfaction probability. However, in some cases where one of the discount factors is set to $1$ for higher accuracy, the computation of the value function using dynamic programming is not guaranteed. This work shows that a multi-step contraction always exists during dynamic programming updates, guaranteeing that the approximate value function will converge exponentially to the true value function. Thus, the computation of satisfaction probability is guaranteed.
On the Uniqueness of Solution for the Bellman Equation of LTL Objectives
Apr 07, 2024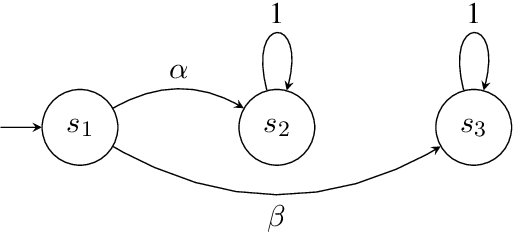
Surrogate rewards for linear temporal logic (LTL) objectives are commonly utilized in planning problems for LTL objectives. In a widely-adopted surrogate reward approach, two discount factors are used to ensure that the expected return approximates the satisfaction probability of the LTL objective. The expected return then can be estimated by methods using the Bellman updates such as reinforcement learning. However, the uniqueness of the solution to the Bellman equation with two discount factors has not been explicitly discussed. We demonstrate with an example that when one of the discount factors is set to one, as allowed in many previous works, the Bellman equation may have multiple solutions, leading to inaccurate evaluation of the expected return. We then propose a condition for the Bellman equation to have the expected return as the unique solution, requiring the solutions for states inside a rejecting bottom strongly connected component (BSCC) to be 0. We prove this condition is sufficient by showing that the solutions for the states with discounting can be separated from those for the states without discounting under this condition