Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Free Learning of Safe yet Effective Controllers
Paper and Code
Mar 26, 2021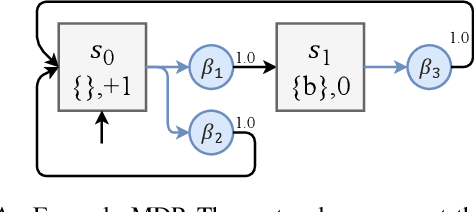
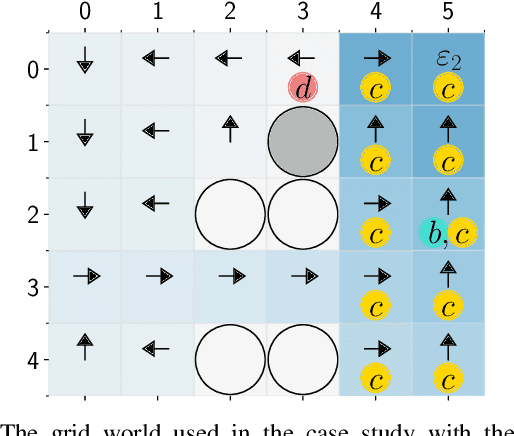
In this paper, we study the problem of learning safe control policies that are also effective -- i.e., maximizing the probability of satisfying the linear temporal logic (LTL) specification of the task, and the discounted reward capturing the (classic) control performance. We consider unknown environments that can be modeled as Markov decision processes (MDPs). We propose a model-free reinforcement learning algorithm that learns a policy that first maximizes the probability of ensuring the safety, then the probability of satisfying the given LTL specification and lastly, the sum of discounted Quality of Control (QoC) rewards. Finally, we illustrate the applicability of our RL-based approach on a case study.
View paper on