 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast Optimization View: Reformulating Single Layer Attention in LLM Based on Tensor and SVM Trick, and Solving It in Matrix Multiplication Time
Paper and Code
Sep 14, 2023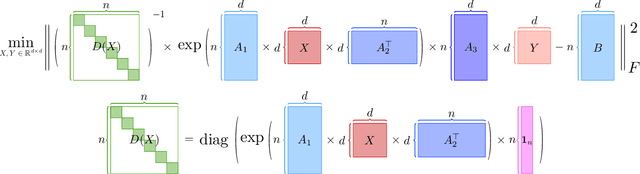

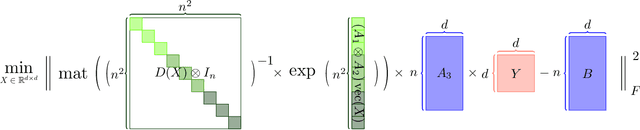
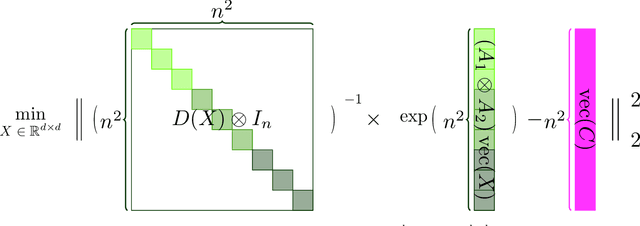
Large language models (LLMs) have played a pivotal role in revolutionizing various facets of our daily existence. Solving attention regression is a fundamental task in optimizing LLMs. In this work, we focus on giving a provable guarantee for the one-layer attention network objective function $L(X,Y) = \sum_{j_0 = 1}^n \sum_{i_0 = 1}^d ( \langle \langle \exp( \mathsf{A}_{j_0} x ) , {\bf 1}_n \rangle^{-1} \exp( \mathsf{A}_{j_0} x ), A_{3} Y_{*,i_0} \rangle - b_{j_0,i_0} )^2$. Here $\mathsf{A} \in \mathbb{R}^{n^2 \times d^2}$ is Kronecker product between $A_1 \in \mathbb{R}^{n \times d}$ and $A_2 \in \mathbb{R}^{n \times d}$. $A_3$ is a matrix in $\mathbb{R}^{n \times d}$, $\mathsf{A}_{j_0} \in \mathbb{R}^{n \times d^2}$ is the $j_0$-th block of $\mathsf{A}$. The $X, Y \in \mathbb{R}^{d \times d}$ are variables we want to learn. $B \in \mathbb{R}^{n \times d}$ and $b_{j_0,i_0} \in \mathbb{R}$ is one entry at $j_0$-th row and $i_0$-th column of $B$, $Y_{*,i_0} \in \mathbb{R}^d$ is the $i_0$-column vector of $Y$, and $x \in \mathbb{R}^{d^2}$ is the vectorization of $X$. In a multi-layer LLM network, the matrix $B \in \mathbb{R}^{n \times d}$ can be viewed as the output of a layer, and $A_1= A_2 = A_3 \in \mathbb{R}^{n \times d}$ can be viewed as the input of a layer. The matrix version of $x$ can be viewed as $QK^\top$ and $Y$ can be viewed as $V$. We provide an iterative greedy algorithm to train loss function $L(X,Y)$ up $\epsilon$ that runs in $\widetilde{O}( ({\cal T}_{\mathrm{mat}}(n,n,d) + {\cal T}_{\mathrm{mat}}(n,d,d) + d^{2\omega}) \log(1/\epsilon) )$ time. Here ${\cal T}_{\mathrm{mat}}(a,b,c)$ denotes the time of multiplying $a \times b$ matrix another $b \times c$ matrix, and $\omega\approx 2.37$ denotes the exponent of matrix multiplication.