 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating CNN Training by Sparsifying Activation Gradients
Paper and Code
Aug 01, 2019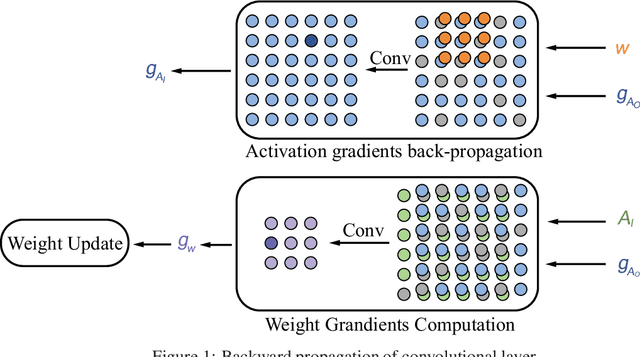
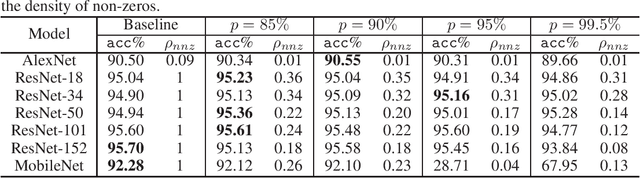
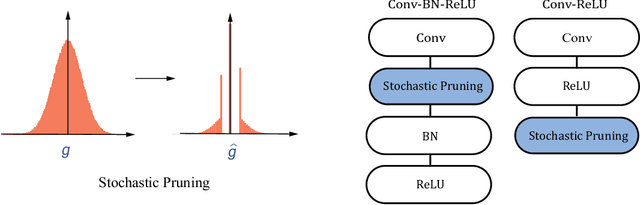
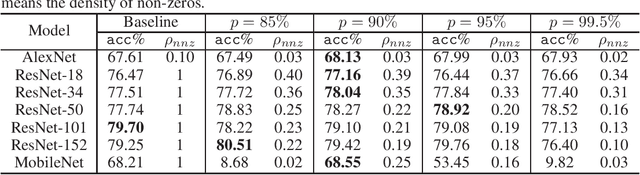
Gradients to activations get involved in most of the calculations during back propagation procedure of Convolution Neural Networks (CNNs) training. However, an important known observation is that the majority of these gradients are close to zero, imposing little impact on weights update. These gradients can be then pruned to achieve high gradient sparsity during CNNs training and reduce the computational cost. In particular, we randomly change a gradient to zero or a threshold value if the gradient is below the threshold which is determined by the statistical distribution of activation gradients. We also theoretically proved that the training convergence of the CNN model can be guaranteed when the above activation gradient sparsification method is applied. We evaluated our method on AlexNet, MobileNet, ResNet-{18, 34, 50, 101, 152} with CIFAR-{10, 100} and ImageNet datasets. Experimental results show that our method can substantially reduce the computational cost with negligible accuracy loss or even accuracy improvement. Finally, we analyzed the benefits that the sparsity of activation gradients introduced in detail.