 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Test-Time Adaptation with Bayesian Conditional Priors
Jun 11, 2026Multi-label recognition with frozen Vision-Language Models (VLMs) is brittle under distribution shift: standard zero-shot inference scores labels independently, ignoring co-occurrence structure and producing incoherent label sets where dominant concepts suppress weaker but compatible labels. We introduce Bayesian Conditional Priors (BCP) Estimation, a gradient-free test-time adaptation method that injects label dependency without tuning the backbone. BCP views zero-shot logits as a proxy for marginal posteriors under a fixed image-text likelihood and attributes shift-induced errors mainly to a mismatched label prior. For each test image, it selects a high-confidence anchor label and applies an anchor-conditioned Bayesian refinement. This update is closed-form in logit space and admits a pointwise mutual information (PMI) interpretation, explicitly promoting compatible labels and suppressing incompatible ones. BCP operates without target annotations by estimating anchor-conditioned priors online from the unlabeled test stream via lightweight second-order co-occurrence statistics, adding negligible overhead beyond a single forward pass. Across standard multi-label benchmarks and multiple CLIP backbones, BCP consistently outperforms strong TTA baselines, e.g., improving RN50 average mAP from 57.31 to 69.22 and ViT-B/16 from 62.61 to 71.79.
Addressing Imbalance in Multi-Label Data via Label-Specific Distance-based Oversampling
Jun 04, 2026The complex imbalanced label distribution poses a crucial challenge to multi-label classification, as most classifiers are biased towards the majority class and high-frequent labels. Oversampling is an efficient and flexible solution that augments instances to provide a more balanced training dataset for multi-label classifiers. Most existing oversampling methods create synthetic instances in a heuristic way that essentially relies on neighborhood information retrieved using Euclidean distance within the entire feature space. However, they fail to consider the varying semantic relevance of features to different labels, leading to label inconsistency among proximate neighbors and further introducing label confusion and overfitting to synthetic instances. To overcome the above issue, we propose a novel sampling approach called Label-Specific Distance-based Multi-Label Oversampling (LSDMLO) that creates more useful and well-labeled synthetic instances to address the imbalance in multi-label datasets. LSDMLO derives the label-specific distance to identify label-consistent neighbors based on the weighted pertinent feature space, which facilitates selecting seed instances that express more label correlations in boundary areas and generating synthetic instances aligned with the label distribution of original data. The comprehensive experiments verify that the proposed LSDMLO outperforms the state-of-the-art multi-label sampling approaches under various base classifiers.
Focus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing
Feb 02, 2026Diffusion Large Language Models (dLLMs) deliver strong long-context processing capability in a non-autoregressive decoding paradigm. However, the considerable computational cost of bidirectional full attention limits the inference efficiency. Although sparse attention is promising, existing methods remain ineffective. This stems from the need to estimate attention importance for tokens yet to be decoded, while the unmasked token positions are unknown during diffusion. In this paper, we present Focus-dLLM, a novel training-free attention sparsification framework tailored for accurate and efficient long-context dLLM inference. Based on the finding that token confidence strongly correlates across adjacent steps, we first design a past confidence-guided indicator to predict unmasked regions. Built upon this, we propose a sink-aware pruning strategy to accurately estimate and remove redundant attention computation, while preserving highly influential attention sinks. To further reduce overhead, this strategy reuses identified sink locations across layers, leveraging the observed cross-layer consistency. Experimental results show that our method offers more than $29\times$ lossless speedup under $32K$ context length. The code is publicly available at: https://github.com/Longxmas/Focus-dLLM
SlimInfer: Accelerating Long-Context LLM Inference via Dynamic Token Pruning
Aug 08, 2025Long-context inference for Large Language Models (LLMs) is heavily limited by high computational demands. While several existing methods optimize attention computation, they still process the full set of hidden states at each layer, limiting overall efficiency. In this work, we propose SlimInfer, an innovative framework that aims to accelerate inference by directly pruning less critical prompt tokens during the forward pass. Our key insight is an information diffusion phenomenon: As information from critical tokens propagates through layers, it becomes distributed across the entire sequence. This diffusion process suggests that LLMs can maintain their semantic integrity when excessive tokens, even including these critical ones, are pruned in hidden states. Motivated by this, SlimInfer introduces a dynamic fine-grained pruning mechanism that accurately removes redundant tokens of hidden state at intermediate layers. This layer-wise pruning naturally enables an asynchronous KV cache manager that prefetches required token blocks without complex predictors, reducing both memory usage and I/O costs. Extensive experiments show that SlimInfer can achieve up to $\mathbf{2.53\times}$ time-to-first-token (TTFT) speedup and $\mathbf{1.88\times}$ end-to-end latency reduction for LLaMA3.1-8B-Instruct on a single RTX 4090, without sacrificing performance on LongBench. Our code will be released upon acceptance.
Batch Selection for Multi-Label Classification Guided by Uncertainty and Dynamic Label Correlations
Dec 21, 2024



The accuracy of deep neural networks is significantly influenced by the effectiveness of mini-batch construction during training. In single-label scenarios, such as binary and multi-class classification tasks, it has been demonstrated that batch selection algorithms preferring samples with higher uncertainty achieve better performance than difficulty-based methods. Although there are two batch selection methods tailored for multi-label data, none of them leverage important uncertainty information. Adapting the concept of uncertainty to multi-label data is not a trivial task, since there are two issues that should be tackled. First, traditional variance or entropy-based uncertainty measures ignore fluctuations of predictions within sliding windows and the importance of the current model state. Second, existing multi-label methods do not explicitly exploit the label correlations, particularly the uncertainty-based label correlations that evolve during the training process. In this paper, we propose an uncertainty-based multi-label batch selection algorithm. It assesses uncertainty for each label by considering differences between successive predictions and the confidence of current outputs, and further leverages dynamic uncertainty-based label correlations to emphasize instances whose uncertainty is synergistically expressed across multiple labels. Empirical studies demonstrate the effectiveness of our method in improving the performance and accelerating the convergence of various multi-label deep learning models.
PhoneLM:an Efficient and Capable Small Language Model Family through Principled Pre-training
Nov 07, 2024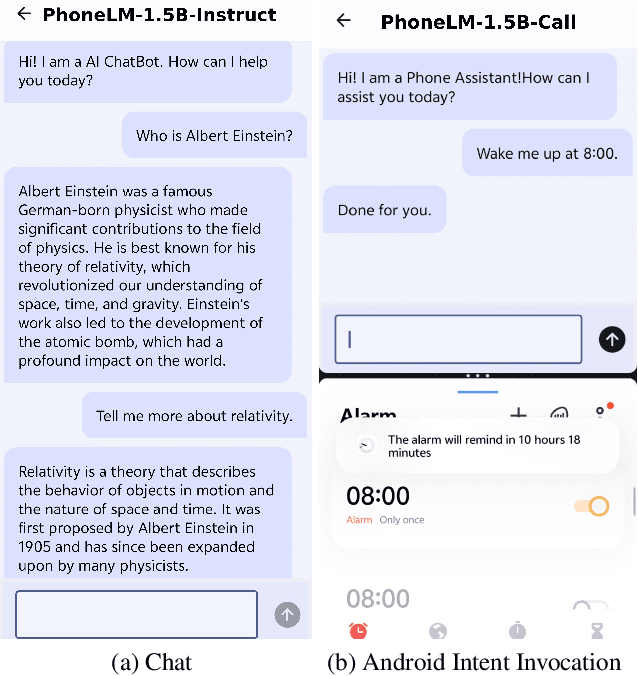
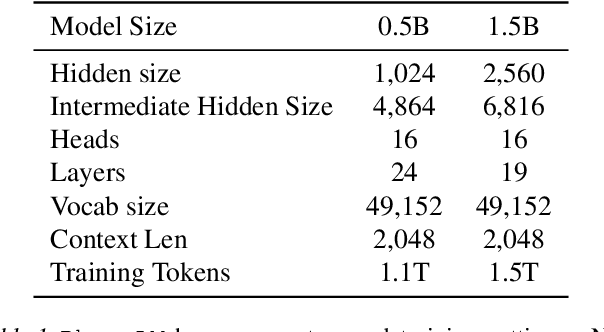
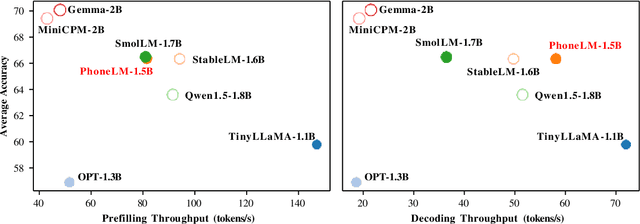

The interest in developing small language models (SLM) for on-device deployment is fast growing. However, the existing SLM design hardly considers the device hardware characteristics. Instead, this work presents a simple yet effective principle for SLM design: architecture searching for (near-)optimal runtime efficiency before pre-training. Guided by this principle, we develop PhoneLM SLM family (currently with 0.5B and 1.5B versions), that acheive the state-of-the-art capability-efficiency tradeoff among those with similar parameter size. We fully open-source the code, weights, and training datasets of PhoneLM for reproducibility and transparency, including both base and instructed versions. We also release a finetuned version of PhoneLM capable of accurate Android Intent invocation, and an end-to-end Android demo. All materials are available at https://github.com/UbiquitousLearning/PhoneLM.
AEMLO: AutoEncoder-Guided Multi-Label Oversampling
Aug 23, 2024Class imbalance significantly impacts the performance of multi-label classifiers. Oversampling is one of the most popular approaches, as it augments instances associated with less frequent labels to balance the class distribution. Existing oversampling methods generate feature vectors of synthetic samples through replication or linear interpolation and assign labels through neighborhood information. Linear interpolation typically generates new samples between existing data points, which may result in insufficient diversity of synthesized samples and further lead to the overfitting issue. Deep learning-based methods, such as AutoEncoders, have been proposed to generate more diverse and complex synthetic samples, achieving excellent performance on imbalanced binary or multi-class datasets. In this study, we introduce AEMLO, an AutoEncoder-guided Oversampling technique specifically designed for tackling imbalanced multi-label data. AEMLO is built upon two fundamental components. The first is an encoder-decoder architecture that enables the model to encode input data into a low-dimensional feature space, learn its latent representations, and then reconstruct it back to its original dimension, thus applying to the generation of new data. The second is an objective function tailored to optimize the sampling task for multi-label scenarios. We show that AEMLO outperforms the existing state-of-the-art methods with extensive empirical studies.
HGNAS: Hardware-Aware Graph Neural Architecture Search for Edge Devices
Aug 23, 2024



Graph Neural Networks (GNNs) are becoming increasingly popular for graph-based learning tasks such as point cloud processing due to their state-of-the-art (SOTA) performance. Nevertheless, the research community has primarily focused on improving model expressiveness, lacking consideration of how to design efficient GNN models for edge scenarios with real-time requirements and limited resources. Examining existing GNN models reveals varied execution across platforms and frequent Out-Of-Memory (OOM) problems, highlighting the need for hardware-aware GNN design. To address this challenge, this work proposes a novel hardware-aware graph neural architecture search framework tailored for resource constraint edge devices, namely HGNAS. To achieve hardware awareness, HGNAS integrates an efficient GNN hardware performance predictor that evaluates the latency and peak memory usage of GNNs in milliseconds. Meanwhile, we study GNN memory usage during inference and offer a peak memory estimation method, enhancing the robustness of architecture evaluations when combined with predictor outcomes. Furthermore, HGNAS constructs a fine-grained design space to enable the exploration of extreme performance architectures by decoupling the GNN paradigm. In addition, the multi-stage hierarchical search strategy is leveraged to facilitate the navigation of huge candidates, which can reduce the single search time to a few GPU hours. To the best of our knowledge, HGNAS is the first automated GNN design framework for edge devices, and also the first work to achieve hardware awareness of GNNs across different platforms. Extensive experiments across various applications and edge devices have proven the superiority of HGNAS. It can achieve up to a 10.6x speedup and an 82.5% peak memory reduction with negligible accuracy loss compared to DGCNN on ModelNet40.
FedMoE: Personalized Federated Learning via Heterogeneous Mixture of Experts
Aug 21, 2024As Large Language Models (LLMs) push the boundaries of AI capabilities, their demand for data is growing. Much of this data is private and distributed across edge devices, making Federated Learning (FL) a de-facto alternative for fine-tuning (i.e., FedLLM). However, it faces significant challenges due to the inherent heterogeneity among clients, including varying data distributions and diverse task types. Towards a versatile FedLLM, we replace traditional dense model with a sparsely-activated Mixture-of-Experts (MoE) architecture, whose parallel feed-forward networks enable greater flexibility. To make it more practical in resource-constrained environments, we present FedMoE, the efficient personalized FL framework to address data heterogeneity, constructing an optimal sub-MoE for each client and bringing the knowledge back to global MoE. FedMoE is composed of two fine-tuning stages. In the first stage, FedMoE simplifies the problem by conducting a heuristic search based on observed activation patterns, which identifies a suboptimal submodel for each client. In the second stage, these submodels are distributed to clients for further training and returned for server aggregating through a novel modular aggregation strategy. Meanwhile, FedMoE progressively adjusts the submodels to optimal through global expert recommendation. Experimental results demonstrate the superiority of our method over previous personalized FL methods.
HiGraphDTI: Hierarchical Graph Representation Learning for Drug-Target Interaction Prediction
Apr 16, 2024The discovery of drug-target interactions (DTIs) plays a crucial role in pharmaceutical development. The deep learning model achieves more accurate results in DTI prediction due to its ability to extract robust and expressive features from drug and target chemical structures. However, existing deep learning methods typically generate drug features via aggregating molecular atom representations, ignoring the chemical properties carried by motifs, i.e., substructures of the molecular graph. The atom-drug double-level molecular representation learning can not fully exploit structure information and fails to interpret the DTI mechanism from the motif perspective. In addition, sequential model-based target feature extraction either fuses limited contextual information or requires expensive computational resources. To tackle the above issues, we propose a hierarchical graph representation learning-based DTI prediction method (HiGraphDTI). Specifically, HiGraphDTI learns hierarchical drug representations from triple-level molecular graphs to thoroughly exploit chemical information embedded in atoms, motifs, and molecules. Then, an attentional feature fusion module incorporates information from different receptive fields to extract expressive target features.Last, the hierarchical attention mechanism identifies crucial molecular segments, which offers complementary views for interpreting interaction mechanisms. The experiment results not only demonstrate the superiority of HiGraphDTI to the state-of-the-art methods, but also confirm the practical ability of our model in interaction interpretation and new DTI discovery.