 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedRDMA: Communication-Efficient Cross-Silo Federated LLM via Chunked RDMA Transmission
Mar 01, 2024Communication overhead is a significant bottleneck in federated learning (FL), which has been exaggerated with the increasing size of AI models. In this paper, we propose FedRDMA, a communication-efficient cross-silo FL system that integrates RDMA into the FL communication protocol. To overcome the limitations of RDMA in wide-area networks (WANs), FedRDMA divides the updated model into chunks and designs a series of optimization techniques to improve the efficiency and robustness of RDMA-based communication. We implement FedRDMA atop the industrial federated learning framework and evaluate it on a real-world cross-silo FL scenario. The experimental results show that \sys can achieve up to 3.8$\times$ speedup in communication efficiency compared to traditional TCP/IP-based FL systems.
Lightweight Protection for Privacy in Offloaded Speech Understanding
Jan 22, 2024Speech is a common input method for mobile embedded devices, but cloud-based speech recognition systems pose privacy risks. Disentanglement-based encoders, designed to safeguard user privacy by filtering sensitive information from speech signals, unfortunately require substantial memory and computational resources, which limits their use in less powerful devices. To overcome this, we introduce a novel system, XXX, optimized for such devices. XXX is built on the insight that speech understanding primarily relies on understanding the entire utterance's long-term dependencies, while privacy concerns are often linked to short-term details. Therefore, XXX focuses on selectively masking these short-term elements, preserving the quality of long-term speech understanding. The core of XXX is an innovative differential mask generator, grounded in interpretable learning, which fine-tunes the masking process. We tested XXX on the STM32H7 microcontroller, assessing its performance in various potential attack scenarios. The results show that XXX maintains speech understanding accuracy and privacy at levels comparable to existing encoders, but with a significant improvement in efficiency, achieving up to 53.3$\times$ faster processing and a 134.1$\times$ smaller memory footprint.
Rethinking Mobile AI Ecosystem in the LLM Era
Aug 28, 2023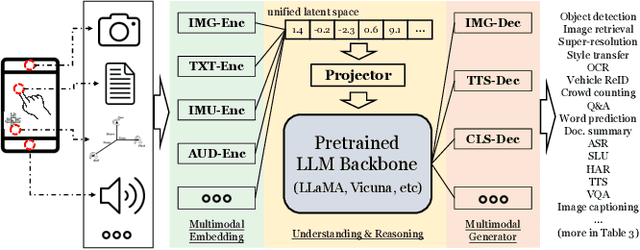
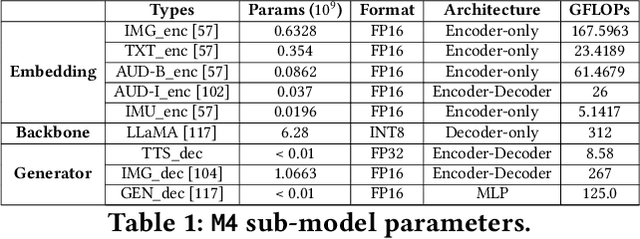
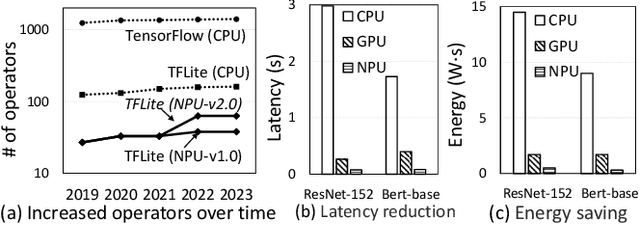
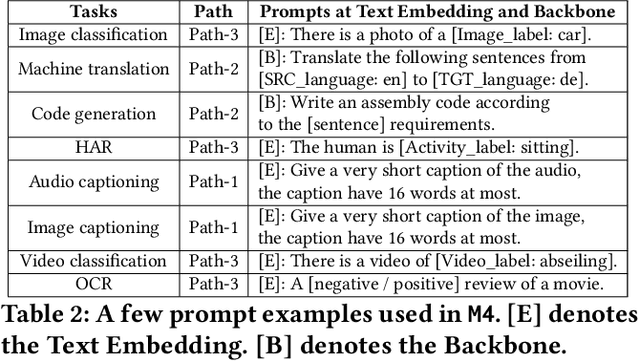
In today's landscape, smartphones have evolved into hubs for hosting a multitude of deep learning models aimed at local execution. A key realization driving this work is the notable fragmentation among these models, characterized by varied architectures, operators, and implementations. This fragmentation imposes a significant burden on the comprehensive optimization of hardware, system settings, and algorithms. Buoyed by the recent strides in large foundation models, this work introduces a pioneering paradigm for mobile AI: a collaborative management approach between the mobile OS and hardware, overseeing a foundational model capable of serving a broad spectrum of mobile AI tasks, if not all. This foundational model resides within the NPU and remains impervious to app or OS revisions, akin to firmware. Concurrently, each app contributes a concise, offline fine-tuned "adapter" tailored to distinct downstream tasks. From this concept emerges a concrete instantiation known as \sys. It amalgamates a curated selection of publicly available Large Language Models (LLMs) and facilitates dynamic data flow. This concept's viability is substantiated through the creation of an exhaustive benchmark encompassing 38 mobile AI tasks spanning 50 datasets, including domains such as Computer Vision (CV), Natural Language Processing (NLP), audio, sensing, and multimodal inputs. Spanning this benchmark, \sys unveils its impressive performance. It attains accuracy parity in 85\% of tasks, demonstrates improved scalability in terms of storage and memory, and offers satisfactory inference speed on Commercial Off-The-Shelf (COTS) mobile devices fortified with NPU support. This stands in stark contrast to task-specific models tailored for individual applications.