 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Mobile AI Ecosystem in the LLM Era
Aug 28, 2023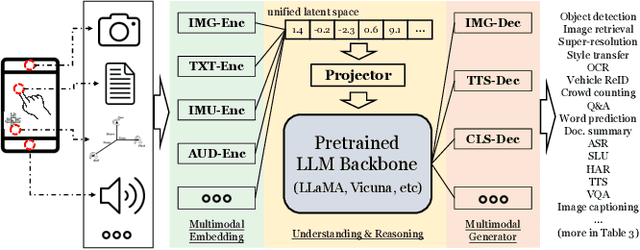
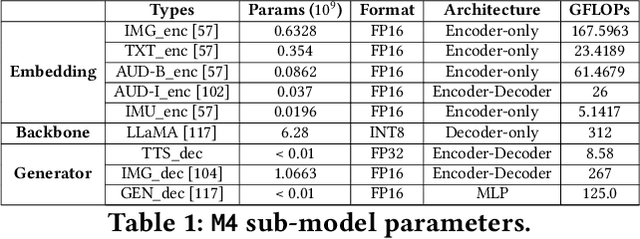
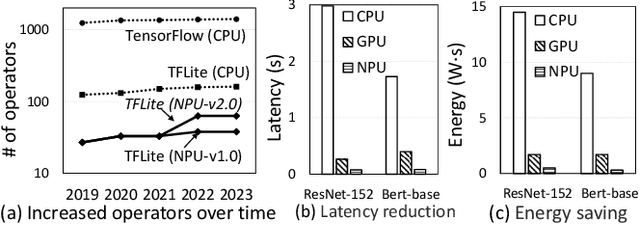
In today's landscape, smartphones have evolved into hubs for hosting a multitude of deep learning models aimed at local execution. A key realization driving this work is the notable fragmentation among these models, characterized by varied architectures, operators, and implementations. This fragmentation imposes a significant burden on the comprehensive optimization of hardware, system settings, and algorithms. Buoyed by the recent strides in large foundation models, this work introduces a pioneering paradigm for mobile AI: a collaborative management approach between the mobile OS and hardware, overseeing a foundational model capable of serving a broad spectrum of mobile AI tasks, if not all. This foundational model resides within the NPU and remains impervious to app or OS revisions, akin to firmware. Concurrently, each app contributes a concise, offline fine-tuned "adapter" tailored to distinct downstream tasks. From this concept emerges a concrete instantiation known as \sys. It amalgamates a curated selection of publicly available Large Language Models (LLMs) and facilitates dynamic data flow. This concept's viability is substantiated through the creation of an exhaustive benchmark encompassing 38 mobile AI tasks spanning 50 datasets, including domains such as Computer Vision (CV), Natural Language Processing (NLP), audio, sensing, and multimodal inputs. Spanning this benchmark, \sys unveils its impressive performance. It attains accuracy parity in 85\% of tasks, demonstrates improved scalability in terms of storage and memory, and offers satisfactory inference speed on Commercial Off-The-Shelf (COTS) mobile devices fortified with NPU support. This stands in stark contrast to task-specific models tailored for individual applications.
Hierarchical Federated Learning through LAN-WAN Orchestration
Oct 22, 2020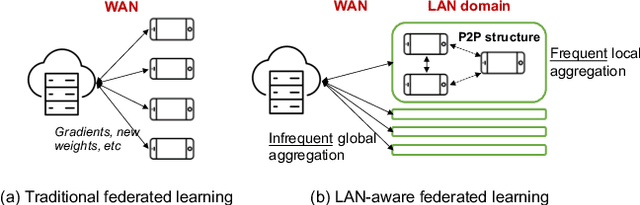



Federated learning (FL) was designed to enable mobile phones to collaboratively learn a global model without uploading their private data to a cloud server. However, exiting FL protocols has a critical communication bottleneck in a federated network coupled with privacy concerns, usually powered by a wide-area network (WAN). Such a WAN-driven FL design leads to significantly high cost and much slower model convergence. In this work, we propose an efficient FL protocol, which involves a hierarchical aggregation mechanism in the local-area network (LAN) due to its abundant bandwidth and almost negligible monetary cost than WAN. Our proposed FL can accelerate the learning process and reduce the monetary cost with frequent local aggregation in the same LAN and infrequent global aggregation on a cloud across WAN. We further design a concrete FL platform, namely LanFL, that incorporates several key techniques to handle those challenges introduced by LAN: cloud-device aggregation architecture, intra-LAN peer-to-peer (p2p) topology generation, inter-LAN bandwidth capacity heterogeneity. We evaluate LanFL on 2 typical Non-IID datasets, which reveals that LanFL can significantly accelerate FL training (1.5x-6.0x), save WAN traffic (18.3x-75.6x), and reduce monetary cost (3.8x-27.2x) while preserving the model accuracy.