 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Adaptive Batch Selection by Highlighting Hard and Imbalanced Samples
Paper and Code
Mar 27, 2024
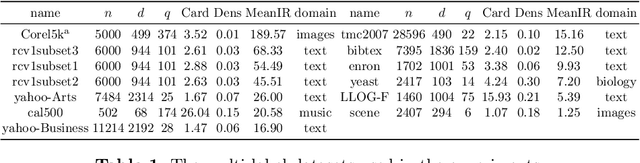

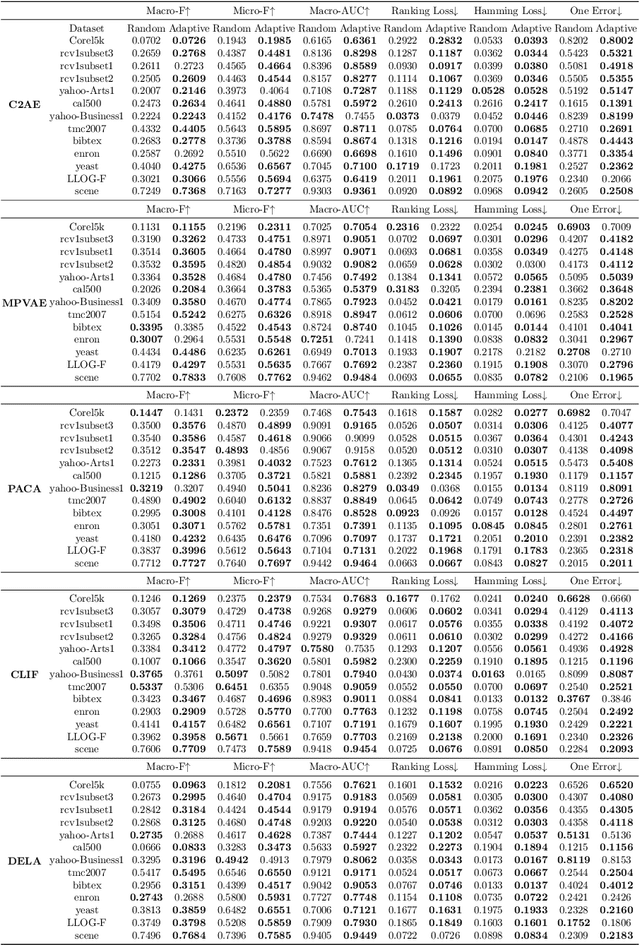
Deep neural network models have demonstrated their effectiveness in classifying multi-label data from various domains. Typically, they employ a training mode that combines mini-batches with optimizers, where each sample is randomly selected with equal probability when constructing mini-batches. However, the intrinsic class imbalance in multi-label data may bias the model towards majority labels, since samples relevant to minority labels may be underrepresented in each mini-batch. Meanwhile, during the training process, we observe that instances associated with minority labels tend to induce greater losses. Existing heuristic batch selection methods, such as priority selection of samples with high contribution to the objective function, i.e., samples with high loss, have been proven to accelerate convergence while reducing the loss and test error in single-label data. However, batch selection methods have not yet been applied and validated in multi-label data. In this study, we introduce a simple yet effective adaptive batch selection algorithm tailored to multi-label deep learning models. It adaptively selects each batch by prioritizing hard samples related to minority labels. A variant of our method also takes informative label correlations into consideration. Comprehensive experiments combining five multi-label deep learning models on thirteen benchmark datasets show that our method converges faster and performs better than random batch selection.