 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
PhoneLM:an Efficient and Capable Small Language Model Family through Principled Pre-training
Nov 07, 2024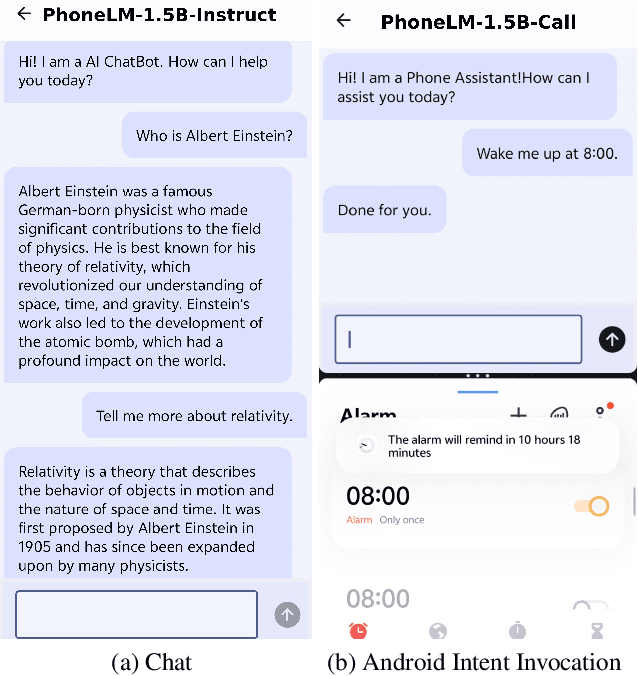
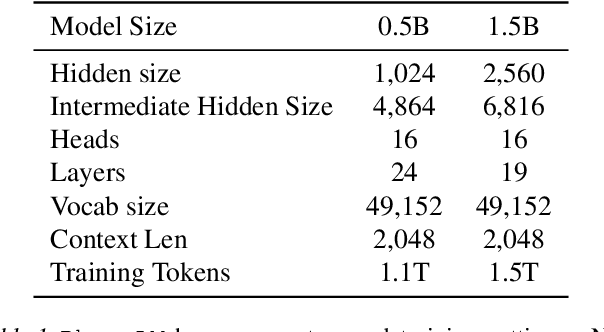
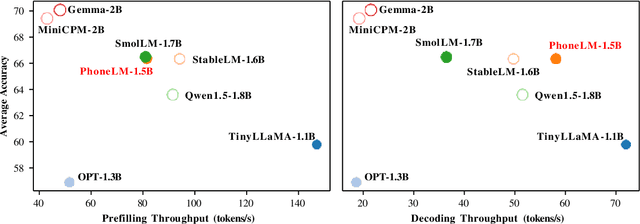

The interest in developing small language models (SLM) for on-device deployment is fast growing. However, the existing SLM design hardly considers the device hardware characteristics. Instead, this work presents a simple yet effective principle for SLM design: architecture searching for (near-)optimal runtime efficiency before pre-training. Guided by this principle, we develop PhoneLM SLM family (currently with 0.5B and 1.5B versions), that acheive the state-of-the-art capability-efficiency tradeoff among those with similar parameter size. We fully open-source the code, weights, and training datasets of PhoneLM for reproducibility and transparency, including both base and instructed versions. We also release a finetuned version of PhoneLM capable of accurate Android Intent invocation, and an end-to-end Android demo. All materials are available at https://github.com/UbiquitousLearning/PhoneLM.
Joint User Association and Power Control for Cell-Free Massive MIMO
Jan 05, 2024This work proposes novel approaches that jointly design user equipment (UE) association and power control (PC) in a downlink user-centric cell-free massive multiple-input multiple-output (CFmMIMO) network, where each UE is only served by a set of access points (APs) for reducing the fronthaul signalling and computational complexity. In order to maximize the sum spectral efficiency (SE) of the UEs, we formulate a mixed-integer nonconvex optimization problem under constraints on the per-AP transmit power, quality-of-service rate requirements, maximum fronthaul signalling load, and maximum number of UEs served by each AP. In order to solve the formulated problem efficiently, we propose two different schemes according to the different sizes of the CFmMIMO systems. For small-scale CFmMIMO systems, we present a successive convex approximation (SCA) method to obtain a stationary solution and also develop a learning-based method (JointCFNet) to reduce the computational complexity. For large-scale CFmMIMO systems, we propose a low-complexity suboptimal algorithm using accelerated projected gradient (APG) techniques. Numerical results show that our JointCFNet can yield similar performance and significantly decrease the run time compared with the SCA algorithm in small-scale systems. The presented APG approach is confirmed to run much faster than the SCA algorithm in the large-scale system while obtaining an SE performance close to that of the SCA approach. Moreover, the median sum SE of the APG method is up to about 2.8 fold higher than that of the heuristic baseline scheme.