 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive-JEPA: Video JEPA Meets Multimodal Trajectory Distillation for End-to-End Driving
Jan 29, 2026End-to-end autonomous driving increasingly leverages self-supervised video pretraining to learn transferable planning representations. However, pretraining video world models for scene understanding has so far brought only limited improvements. This limitation is compounded by the inherent ambiguity of driving: each scene typically provides only a single human trajectory, making it difficult to learn multimodal behaviors. In this work, we propose Drive-JEPA, a framework that integrates Video Joint-Embedding Predictive Architecture (V-JEPA) with multimodal trajectory distillation for end-to-end driving. First, we adapt V-JEPA for end-to-end driving, pretraining a ViT encoder on large-scale driving videos to produce predictive representations aligned with trajectory planning. Second, we introduce a proposal-centric planner that distills diverse simulator-generated trajectories alongside human trajectories, with a momentum-aware selection mechanism to promote stable and safe behavior. When evaluated on NAVSIM, the V-JEPA representation combined with a simple transformer-based decoder outperforms prior methods by 3 PDMS in the perception-free setting. The complete Drive-JEPA framework achieves 93.3 PDMS on v1 and 87.8 EPDMS on v2, setting a new state-of-the-art.
GNNavigator: Towards Adaptive Training of Graph Neural Networks via Automatic Guideline Exploration
Apr 15, 2024Graph Neural Networks (GNNs) succeed significantly in many applications recently. However, balancing GNNs training runtime cost, memory consumption, and attainable accuracy for various applications is non-trivial. Previous training methodologies suffer from inferior adaptability and lack a unified training optimization solution. To address the problem, this work proposes GNNavigator, an adaptive GNN training configuration optimization framework. GNNavigator meets diverse GNN application requirements due to our unified software-hardware co-abstraction, proposed GNNs training performance model, and practical design space exploration solution. Experimental results show that GNNavigator can achieve up to 3.1x speedup and 44.9% peak memory reduction with comparable accuracy to state-of-the-art approaches.
Anything in Any Scene: Photorealistic Video Object Insertion
Jan 30, 2024Realistic video simulation has shown significant potential across diverse applications, from virtual reality to film production. This is particularly true for scenarios where capturing videos in real-world settings is either impractical or expensive. Existing approaches in video simulation often fail to accurately model the lighting environment, represent the object geometry, or achieve high levels of photorealism. In this paper, we propose Anything in Any Scene, a novel and generic framework for realistic video simulation that seamlessly inserts any object into an existing dynamic video with a strong emphasis on physical realism. Our proposed general framework encompasses three key processes: 1) integrating a realistic object into a given scene video with proper placement to ensure geometric realism; 2) estimating the sky and environmental lighting distribution and simulating realistic shadows to enhance the light realism; 3) employing a style transfer network that refines the final video output to maximize photorealism. We experimentally demonstrate that Anything in Any Scene framework produces simulated videos of great geometric realism, lighting realism, and photorealism. By significantly mitigating the challenges associated with video data generation, our framework offers an efficient and cost-effective solution for acquiring high-quality videos. Furthermore, its applications extend well beyond video data augmentation, showing promising potential in virtual reality, video editing, and various other video-centric applications. Please check our project website https://anythinginanyscene.github.io for access to our project code and more high-resolution video results.
Energy-efficient Integrated Sensing and Communication System and DNLFM Waveform
Sep 18, 2023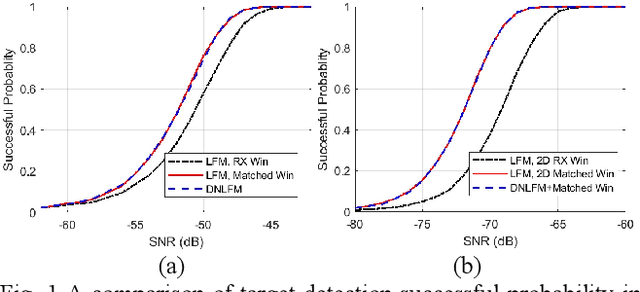
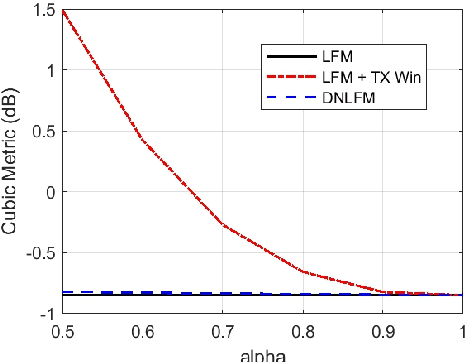
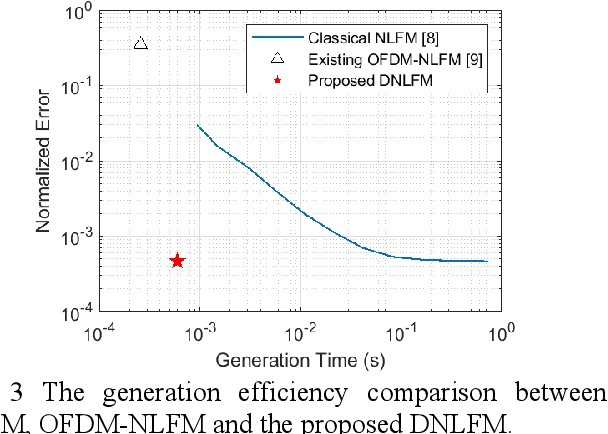

Integrated sensing and communication (ISAC) is a key enabler of 6G. Unlike communication radio links, the sensing signal requires to experience round trips from many scatters. Therefore, sensing is more power-sensitive and faces a severer multi-target interference. In this paper, the ISAC system employs dedicated sensing signals, which can be reused as the communication reference signal. This paper proposes to add time-frequency matched windows at both the transmitting and receiving sides, which avoids mismatch loss and increases energy efficiency. Discrete non-linear frequency modulation (DNLFM) is further proposed to achieve both time-domain constant modulus and frequency-domain arbitrary windowing weights. DNLFM uses very few Newton iterations and a simple geometrically-equivalent method to generate, which greatly reduces the complex numerical integral in the conventional method. Moreover, the spatial-domain matched window is proposed to achieve low sidelobes. The simulation results show that the proposed methods gain a higher energy efficiency than conventional methods.
Dynamic Structural Brain Network Construction by Hierarchical Prototype Embedding GCN using T1-MRI
May 17, 2023Constructing structural brain networks using T1-weighted magnetic resonance imaging (T1-MRI) presents a significant challenge due to the lack of direct regional connectivity information. Current methods with T1-MRI rely on predefined regions or isolated pretrained location modules to obtain atrophic regions, which neglects individual specificity. Besides, existing methods capture global structural context only on the whole-image-level, which weaken correlation between regions and the hierarchical distribution nature of brain connectivity.We hereby propose a novel dynamic structural brain network construction method based on T1-MRI, which can dynamically localize critical regions and constrain the hierarchical distribution among them for constructing dynamic structural brain network. Specifically, we first cluster spatially-correlated channel and generate several critical brain regions as prototypes. Further, we introduce a contrastive loss function to constrain the prototypes distribution, which embed the hierarchical brain semantic structure into the latent space. Self-attention and GCN are then used to dynamically construct hierarchical correlations of critical regions for brain network and explore the correlation, respectively. Our method is evaluated on ADNI-1 and ADNI-2 databases for mild cognitive impairment (MCI) conversion prediction, and acheive the state-of-the-art (SOTA) performance. Our source code is available at http://github.com/*******.
3DG-STFM: 3D Geometric Guided Student-Teacher Feature Matching
Jul 06, 2022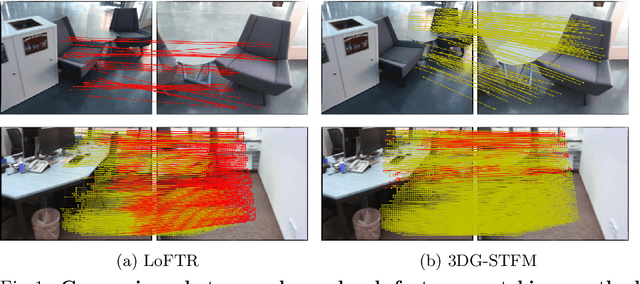
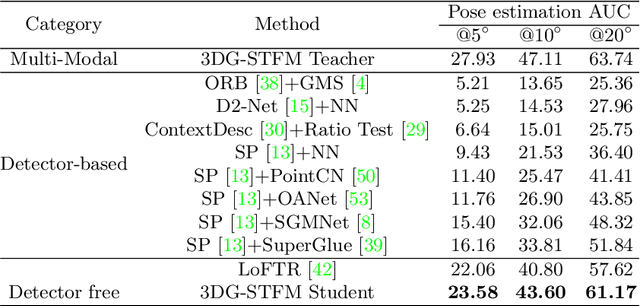
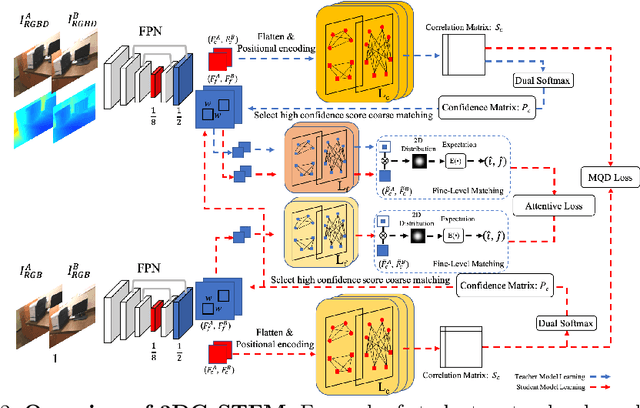
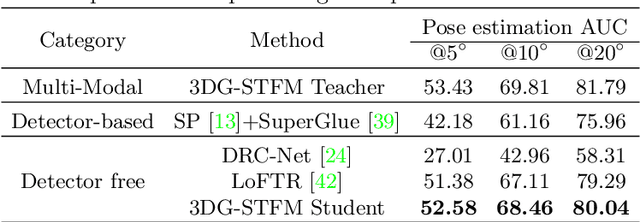
We tackle the essential task of finding dense visual correspondences between a pair of images. This is a challenging problem due to various factors such as poor texture, repetitive patterns, illumination variation, and motion blur in practical scenarios. In contrast to methods that use dense correspondence ground-truths as direct supervision for local feature matching training, we train 3DG-STFM: a multi-modal matching model (Teacher) to enforce the depth consistency under 3D dense correspondence supervision and transfer the knowledge to 2D unimodal matching model (Student). Both teacher and student models consist of two transformer-based matching modules that obtain dense correspondences in a coarse-to-fine manner. The teacher model guides the student model to learn RGB-induced depth information for the matching purpose on both coarse and fine branches. We also evaluate 3DG-STFM on a model compression task. To the best of our knowledge, 3DG-STFM is the first student-teacher learning method for the local feature matching task. The experiments show that our method outperforms state-of-the-art methods on indoor and outdoor camera pose estimations, and homography estimation problems. Code is available at: https://github.com/Ryan-prime/3DG-STFM.