 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Robust Retinal Eye Tracking: A Weakly Supervised Algorithmic Framework
May 09, 2026Retinal image-based eye tracking is widely used in ophthalmic imaging and vision science, and is a promising path to deliver higher gaze accuracy than the pupil- and cornea-based approaches commonly used in modern AR/VR devices. Nevertheless, existing retinal tracking algorithms still primarily rely on classical template-matching registration, which can be insufficiently robust to retinal feature variability and real-world imaging conditions. In this work, we propose a novel weakly-supervised, learning-based framework for robust retinal eye tracking. Initial studies demonstrate high accuracy, achieving the 95th-percentile gaze error < 0.45 deg across a cohort of 6 participants.
Rapidly deploying on-device eye tracking by distilling visual foundation models
Apr 02, 2026Eye tracking (ET) plays a critical role in augmented and virtual reality applications. However, rapidly deploying high-accuracy, on-device gaze estimation for new products remains challenging because hardware configurations (e.g., camera placement, camera pose, and illumination) often change across device generations. Visual foundation models (VFMs) are a promising direction for rapid training and deployment, and they excel on natural-image benchmarks; yet we find that off-the-shelf VFMs still struggle to achieve high accuracy on specialized near-eye infrared imagery. To address this gap, we introduce DistillGaze, a framework that distills a foundation model by leveraging labeled synthetic data and unlabeled real data for rapid and high-performance on-device gaze estimation. DistillGaze proceeds in two stages. First, we adapt a VFM into a domain-specialized teacher using self-supervised learning on labeled synthetic and unlabeled real images. Synthetic data provides scalable, high-quality gaze supervision, while unlabeled real data helps bridge the synthetic-to-real domain gap. Second, we train an on-device student using both teacher guidance and self-training. Evaluated on a large-scale, crowd-sourced dataset spanning over 2,000 participants, DistillGaze reduces median gaze error by 58.62% relative to synthetic-only baselines while maintaining a lightweight 256K-parameter model suitable for real-time on-device deployment. Overall, DistillGaze provides an efficient pathway for training and deploying ET models that adapt to hardware changes, and offers a recipe for combining synthetic supervision with unlabeled real data in on-device regression tasks.
DepthTCM: High Efficient Depth Compression via Physics-aware Transformer-CNN Mixed Architecture
Mar 22, 2026We propose DepthTCM, a physics-aware end-to-end framework for depth map compression. In our framework of DepthTCM, the high-bit depth map is first converted to a conventional 3-channel image representation losslessly using a method inspired by a physical sinusoidal fringe pattern based profiliometry system, then the 3-channel color image is encoded and decoded by a recently developed Transformer-CNN mixed neural network architecture. Specifically, DepthTCM maps depth to a smooth 3-channel using multiwavelength depth (MWD) encoding, then globally quantized the MWD encoded representation to 4 bits per channel to reduce entropy, and finally is compressed using a learned codec that combines convolutional and Transformer layers. Experiment results demonstrate the advantage of our proposed method. On Middlebury 2014, DepthTCM reaches 0.307 bpp while preserving 99.38% accuracy, a level of fidelity commensurate with lossless PNG. We additionally demonstrate practical efficiency and scalability, reporting average end-to-end inference times of 41.48 ms (encoder) and 47.45 ms (decoder) on the ScanNet++ iPhone RGB-D subset. Ablations validate our design choices: relative to 8-bit quantization, 4-bit quantization reduces bitrate by 66% while maintaining comparable reconstruction quality, with only a marginal 0.68 dB PSNR change and a 0.04% accuracy difference. In addition, Transformer--CNN blocks further improve PSNR by up to 0.75 dB over CNN-only architectures.
Digitally Prototype Your Eye Tracker: Simulating Hardware Performance using 3D Synthetic Data
Mar 20, 2025



Eye tracking (ET) is a key enabler for Augmented and Virtual Reality (AR/VR). Prototyping new ET hardware requires assessing the impact of hardware choices on eye tracking performance. This task is compounded by the high cost of obtaining data from sufficiently many variations of real hardware, especially for machine learning, which requires large training datasets. We propose a method for end-to-end evaluation of how hardware changes impact machine learning-based ET performance using only synthetic data. We utilize a dataset of real 3D eyes, reconstructed from light dome data using neural radiance fields (NeRF), to synthesize captured eyes from novel viewpoints and camera parameters. Using this framework, we demonstrate that we can predict the relative performance across various hardware configurations, accounting for variations in sensor noise, illumination brightness, and optical blur. We also compare our simulator with the publicly available eye tracking dataset from the Project Aria glasses, demonstrating a strong correlation with real-world performance. Finally, we present a first-of-its-kind analysis in which we vary ET camera positions, evaluating ET performance ranging from on-axis direct views of the eye to peripheral views on the frame. Such an analysis would have previously required manufacturing physical devices to capture evaluation data. In short, our method enables faster prototyping of ET hardware.
Quasi-calibration method for structured light system with auxiliary camera
Mar 02, 2024The structured light projection technique is a representative active method for 3-D reconstruction, but many researchers face challenges with the intricate projector calibration process. To address this complexity, we employs an additional camera, temporarily referred to as the auxiliary camera, to eliminate the need for projector calibration. The auxiliary camera aids in constructing rational model equations, enabling the generation of world coordinates based on absolute phase information. Once calibration is complete, the auxiliary camera can be removed, mitigating occlusion issues and allowing the system to maintain its compact single-camera, single-projector design. Our approach not only resolves the common problem of calibrating projectors in digital fringe projection systems but also enhances the feasibility of diverse-shaped 3D imaging systems that utilize fringe projection, all without the need for the complex projector calibration process.
PointACL:Adversarial Contrastive Learning for Robust Point Clouds Representation under Adversarial Attack
Sep 14, 2022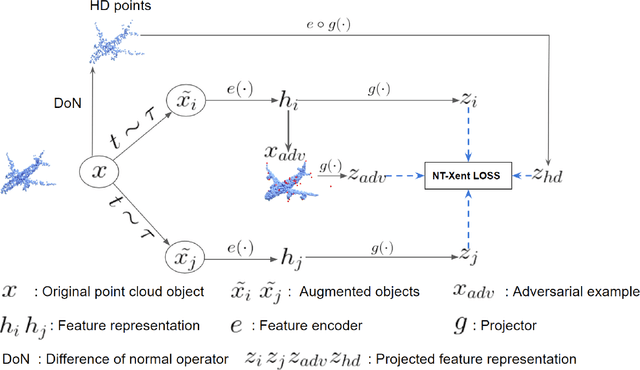
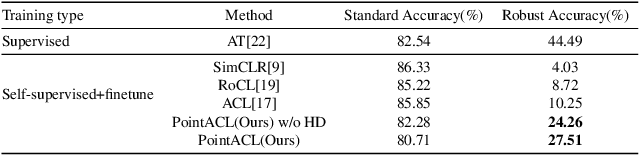

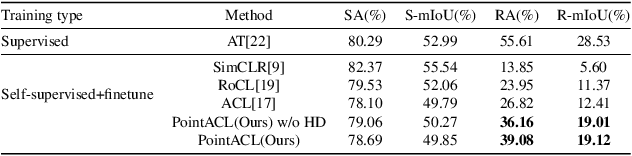
Despite recent success of self-supervised based contrastive learning model for 3D point clouds representation, the adversarial robustness of such pre-trained models raised concerns. Adversarial contrastive learning (ACL) is considered an effective way to improve the robustness of pre-trained models. In contrastive learning, the projector is considered an effective component for removing unnecessary feature information during contrastive pretraining and most ACL works also use contrastive loss with projected feature representations to generate adversarial examples in pretraining, while "unprojected " feature representations are used in generating adversarial inputs during inference.Because of the distribution gap between projected and "unprojected" features, their models are constrained of obtaining robust feature representations for downstream tasks. We introduce a new method to generate high-quality 3D adversarial examples for adversarial training by utilizing virtual adversarial loss with "unprojected" feature representations in contrastive learning framework. We present our robust aware loss function to train self-supervised contrastive learning framework adversarially. Furthermore, we find selecting high difference points with the Difference of Normal (DoN) operator as additional input for adversarial self-supervised contrastive learning can significantly improve the adversarial robustness of the pre-trained model. We validate our method, PointACL on downstream tasks, including 3D classification and 3D segmentation with multiple datasets. It obtains comparable robust accuracy over state-of-the-art contrastive adversarial learning methods.
3DG-STFM: 3D Geometric Guided Student-Teacher Feature Matching
Jul 06, 2022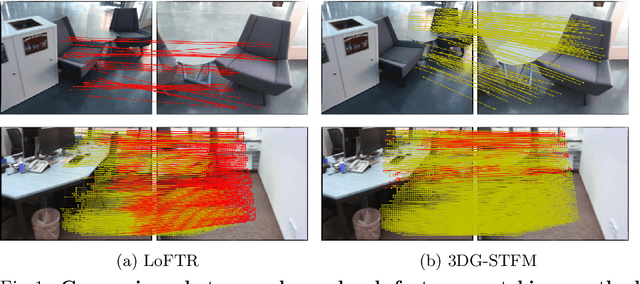
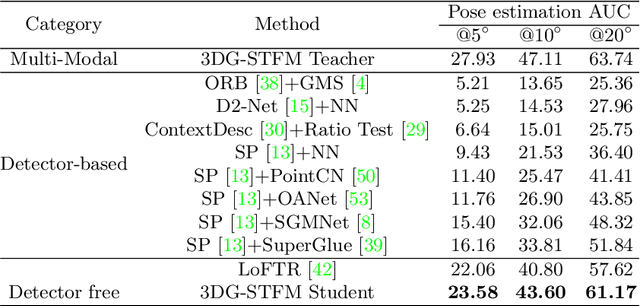
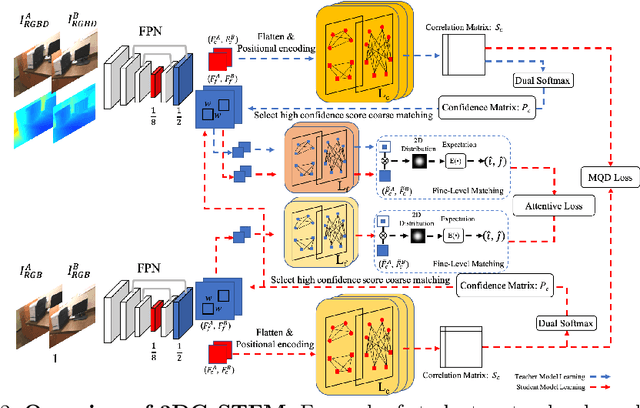
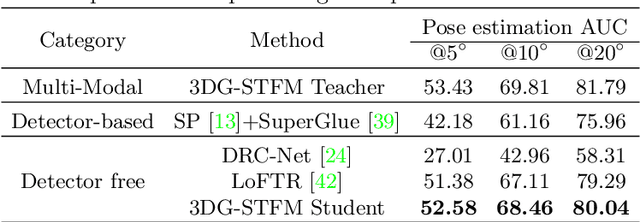
We tackle the essential task of finding dense visual correspondences between a pair of images. This is a challenging problem due to various factors such as poor texture, repetitive patterns, illumination variation, and motion blur in practical scenarios. In contrast to methods that use dense correspondence ground-truths as direct supervision for local feature matching training, we train 3DG-STFM: a multi-modal matching model (Teacher) to enforce the depth consistency under 3D dense correspondence supervision and transfer the knowledge to 2D unimodal matching model (Student). Both teacher and student models consist of two transformer-based matching modules that obtain dense correspondences in a coarse-to-fine manner. The teacher model guides the student model to learn RGB-induced depth information for the matching purpose on both coarse and fine branches. We also evaluate 3DG-STFM on a model compression task. To the best of our knowledge, 3DG-STFM is the first student-teacher learning method for the local feature matching task. The experiments show that our method outperforms state-of-the-art methods on indoor and outdoor camera pose estimations, and homography estimation problems. Code is available at: https://github.com/Ryan-prime/3DG-STFM.